Annotation
- Introduction
- Understanding Custom Text Classification
- Why Choose Azure AI Language Service for Text Classification
- Setting Up Azure AI Language Service
- Training Your Custom Text Classification Model
- Azure AI Language Service Pricing Structure
- Core Features and Capabilities
- Practical Applications and Use Cases
- Common Implementation Challenges
- Pros and Cons
- Conclusion
- Frequently Asked Questions
Azure AI Language Service: Custom Text Classification Setup & Training Guide
Learn how to implement custom text classification with Azure AI Language Service, from setup and training to deployment, for accurate text

Introduction
In today's data-rich business environment, effectively categorizing and understanding text data has become essential for driving informed decisions. Microsoft's Azure AI Language Service provides powerful natural language processing capabilities, including custom text classification that allows organizations to build tailored categorization systems. This comprehensive tutorial guides you through the complete process of setting up, training, and deploying custom text classification models using Azure's cloud infrastructure.
Understanding Custom Text Classification
Custom text classification represents a specialized machine learning approach that automatically assigns predefined categories to text documents based on your specific business requirements. Unlike general text analytics that might focus on sentiment analysis or key phrase extraction, custom text classification enables you to define domain-specific categories that align with your organizational needs. For instance, you could classify customer support tickets into categories like 'Technical Issue', 'Billing Inquiry', or 'Feature Request' – providing immediate context for routing and resolution.
Azure AI Language Service delivers enterprise-grade capabilities for building sophisticated text classification solutions that scale with your data volume and complexity requirements.
Why Choose Azure AI Language Service for Text Classification
Azure AI Language Service offers several compelling advantages for organizations implementing custom text classification. The platform's cloud-native architecture ensures seamless scalability to handle massive text volumes without performance degradation. Advanced machine learning algorithms and natural language processing techniques deliver high accuracy rates, while the customization options allow you to train models specifically on your data domain. The service integrates smoothly with other AI APIs and SDKs and AI automation platforms, creating a comprehensive AI ecosystem. The pay-as-you-go pricing model provides cost optimization flexibility, making it accessible for both small experiments and large-scale production deployments.
Setting Up Azure AI Language Service
Before beginning the configuration process, ensure you have an active Azure subscription. Microsoft offers free trial accounts for new users, providing credit to explore services without immediate financial commitment. The setup process involves several key steps that establish the foundation for your text classification projects.
The initial step involves creating an Azure AI Language resource through the Azure portal. This resource serves as the central management point for your custom text classification models and provides access to Language Studio – the web-based interface for model development. After logging into portal.azure.com with your credentials, navigate to 'Create a resource' and search for 'Language Service'. Select the appropriate service from results and proceed with creation.
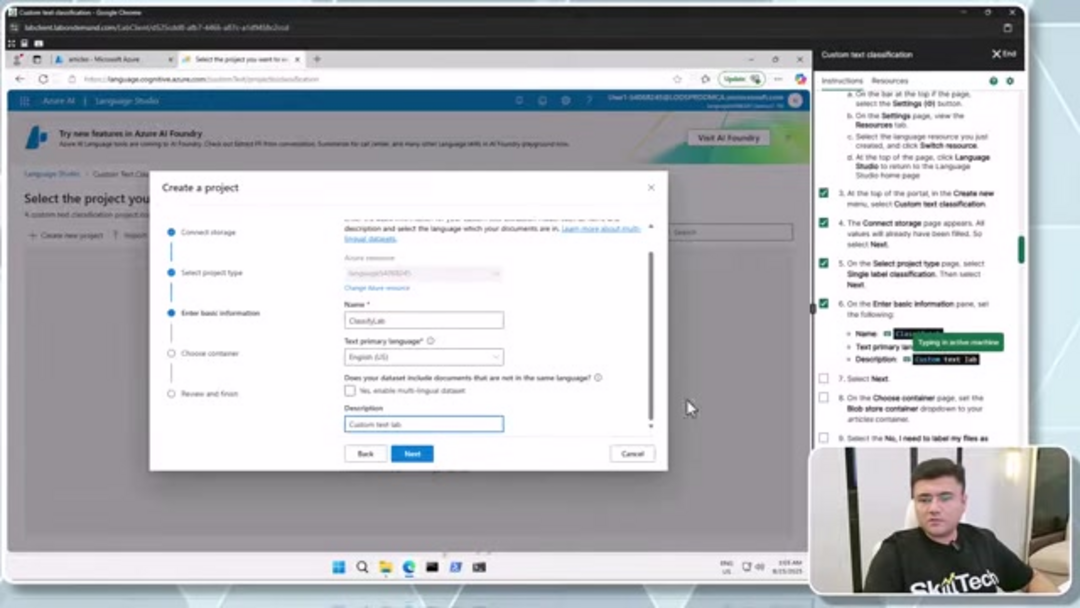
During configuration, provide essential details including your Azure subscription, resource group for organizational management, and geographic region selection – choosing locations near your data sources can improve performance. Assign a unique name for your Language Service resource and select the pricing tier that matches your project scope. The Free F0 tier works well for experimentation, while production environments typically require Standard or Premium tiers for higher transaction limits and advanced features.
Azure AI Language Service requires associated storage accounts for operational functionality. During resource creation, you'll configure a new storage account or link an existing one, ensuring Standard LRS (Locally Redundant Storage) is selected for reliability. After deployment completes, configure role-based access control by navigating to your storage account's Access Control (IAM) section. Add a role assignment selecting 'Storage Blob Data Owner' and assign this to your user account, enabling proper permissions for model training operations.
Training Your Custom Text Classification Model
With infrastructure established, the model training process begins with data preparation and labeling – critical steps that directly impact classification accuracy and performance.
Begin by creating a dedicated container within your storage account specifically for training documents. Navigate to the Containers section and create a new container named "articles" with access level set to "Container" to enable proper blob operations. Upload your sample documents – these should represent the various text categories you want to classify. For optimal results, ensure your training dataset includes sufficient examples from each category, with documents that realistically represent the text variations your model will encounter in production. This preparation phase is crucial for building effective AI agents and assistants that can process and categorize information accurately.
Data labeling provides the structured foundation that enables your model to learn category distinctions. In Language Studio, access the Data Labeling section where you'll see the uploaded files from your storage account. Create custom classes that match your classification needs – for example, you might establish categories like 'Sports', 'News', 'Entertainment', and 'Classifieds' for a media application. Systematically assign each document to its appropriate category, ensuring consistent labeling across your dataset. This meticulous approach to data preparation significantly influences model accuracy and generalization capability.
Initiate the training process by accessing Training Jobs in Language Studio. Create a new training job named appropriately for your project, such as "ClassifyArticles". Configure the data split between training and testing sets – the default 80/20 split typically provides good balance between model learning and validation. During training, Azure employs advanced machine learning techniques to analyze patterns in your labeled data and build classification capabilities. After training completes, evaluate model performance using the provided metrics, including precision, recall, and F1-score measurements that indicate how well your model distinguishes between categories.
Azure AI Language Service Pricing Structure
Understanding Azure's pricing model helps with budget planning and cost optimization. The Free Tier (F0) provides limited monthly transactions suitable for experimentation and proof-of-concept projects. The Standard Tier (S0) operates on pay-as-you-go pricing based on transaction volume, ideal for growing applications with variable usage patterns. The Premium Tier offers reserved capacity pricing for high-volume enterprise deployments requiring predictable costs and maximum throughput. Consider your expected text processing volume and response time requirements when selecting the appropriate tier for your implementation.
Core Features and Capabilities
Azure AI Language Service delivers comprehensive natural language processing functionality beyond custom text classification. Sentiment analysis determines emotional tone in text, while key phrase extraction identifies central concepts and topics. Language detection automatically recognizes text language, and named entity recognition identifies people, organizations, and locations mentioned in content. The service also supports custom named entity recognition for domain-specific entities and custom question answering for building intelligent knowledge bases. These capabilities can be combined to create sophisticated AI writing tools and AI chatbots that understand and process natural language effectively.
Practical Applications and Use Cases
Custom text classification finds application across numerous industries and business functions. Customer service organizations automate ticket categorization, routing inquiries to appropriate teams based on content analysis. Healthcare providers classify medical records and patient feedback for improved care coordination and operational efficiency. Financial institutions analyze documents, news, and reports for risk assessment and opportunity identification. E-commerce platforms categorize product reviews and customer feedback to enhance discovery and satisfaction. Media companies classify content for personalized recommendations and audience engagement. These applications demonstrate how text classification integrates with conversational AI tools and AI email assistants to automate information processing.
Common Implementation Challenges
Several challenges may arise during custom text classification projects. Data imbalance occurs when some categories have significantly more training examples than others, potentially creating biased models – techniques like oversampling minority classes can address this. Overfitting happens when models become too complex and perform poorly on new data – regularization and cross-validation help maintain generalization. Limited labeled data availability can constrain model training – active learning approaches and transfer learning techniques can optimize limited datasets. Ambiguous category definitions confuse models during training – spending adequate time establishing clear, distinct categories improves results. Data quality issues including noise and inconsistency impact performance – thorough data cleaning and preprocessing establishes a solid foundation for accurate classification.
Pros and Cons
Advantages
- Highly scalable cloud infrastructure handles large text volumes efficiently
- Advanced machine learning algorithms deliver accurate classification results
- Full customization options for domain-specific category definitions
- Seamless integration with comprehensive Azure service ecosystem
- Flexible pay-as-you-go pricing optimizes operational costs
- Enterprise-grade security and compliance certifications
- Continuous model improvement through retraining capabilities
Disadvantages
- Requires active Azure subscription and cloud dependency
- Steeper learning curve for Azure service newcomers
- Costs can escalate significantly with high-volume usage
- Limited offline functionality due to cloud-based nature
- Data governance considerations for sensitive information
Conclusion
Azure AI Language Service provides a robust, scalable platform for implementing custom text classification solutions that transform unstructured text into actionable categorized information. By following the comprehensive setup, training, and deployment process outlined in this guide, organizations can build tailored classification systems that address specific business needs. The service's integration capabilities with other Azure AI services and flexible pricing models make it accessible for projects of varying scales and complexities. As text data continues to grow in volume and importance, mastering custom text classification becomes increasingly valuable for extracting insights, automating processes, and enhancing decision-making across business functions.
Frequently Asked Questions
What is Azure AI Language Service used for?
Azure AI Language Service is a cloud-based natural language processing platform that provides text analysis capabilities including sentiment analysis, key phrase extraction, language detection, named entity recognition, and custom text classification for business applications.
How much does Azure AI Language Service cost?
Azure AI Language Service offers Free (F0) tier for experimentation, Standard (S0) pay-as-you-go pricing for growing applications, and Premium tier with reserved capacity for enterprise deployments with predictable costs based on transaction volume.
What are the main challenges in custom text classification?
Key challenges include data imbalance between categories, model overfitting, limited labeled training data, ambiguous category definitions, and data quality issues that require careful preprocessing and model configuration.
How accurate is Azure custom text classification?
Accuracy depends on training data quality and quantity, but Azure's advanced machine learning algorithms typically deliver high precision and recall rates when properly trained with sufficient, well-labeled representative documents.
How long does it take to train a custom text classification model?
Training time varies based on data size and complexity, but typically ranges from a few minutes to several hours for large datasets using Azure's scalable infrastructure.