Annotation
- Introduction
- Understanding Zero-Shot Learning Fundamentals
- Latent Embeddings: The Technical Foundation
- TARS Models: Advanced Zero-Shot Classification
- Prompt Engineering for Optimal Performance
- Open Source Solutions and Implementation
- Practical Business Applications
- Pros and Cons
- Conclusion
Zero-Shot Learning: Text Classification Without Labeled Training Data
Zero-shot learning enables AI to classify text into unseen categories without labeled data, using semantic embeddings and knowledge transfer for

Introduction
In the rapidly advancing field of Natural Language Processing, zero-shot learning represents a groundbreaking shift in how machines understand and categorize text. This innovative approach enables AI models to classify documents, sentiments, and topics without requiring extensive labeled training datasets – a limitation that has traditionally constrained machine learning applications. By leveraging semantic understanding and knowledge transfer, zero-shot learning opens new possibilities for organizations dealing with dynamic content and evolving classification needs across various AI chatbots and automation platforms.
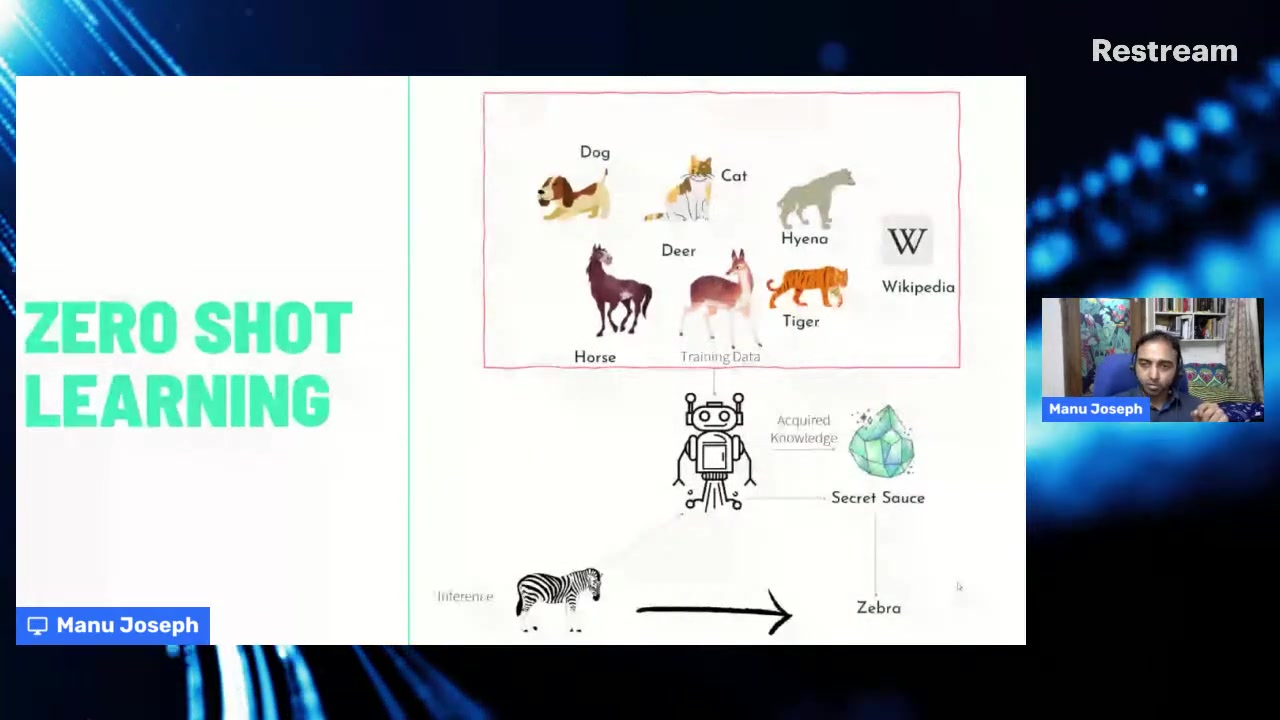
Understanding Zero-Shot Learning Fundamentals
Zero-shot learning represents a paradigm shift from traditional supervised learning methods. While conventional approaches require substantial labeled examples for each classification category, zero-shot learning enables models to categorize text into classes they've never encountered during training. This capability stems from the model's ability to understand semantic relationships and transfer knowledge from related domains.
The core mechanism involves projecting both text inputs and category labels into a shared semantic space where their relationships can be measured through similarity metrics. This approach mimics human reasoning – we can often categorize new concepts based on our understanding of related ideas without needing explicit examples.
Latent Embeddings: The Technical Foundation
Latent embeddings form the technical backbone of effective zero-shot classification systems. These embeddings create a multidimensional space where both text content and category labels can be represented numerically, allowing for precise similarity calculations. Advanced models like Sentence-BERT (S-BERT) excel at generating these embeddings by capturing nuanced semantic meanings beyond simple keyword matching.
The embedding process typically follows these steps:
- Text Encoding: Input text is processed through a transformer-based encoder to create a dense vector representation.
- Label Representation: Category labels are similarly encoded using the same model architecture.
- Similarity Assessment: Cosine similarity or other metrics calculate alignment between text and labels.
- Classification Decision: The system assigns text to the category with the highest similarity score.
This methodology proves valuable for AI writing tools that need to categorize diverse content types without constant retraining.
TARS Models: Advanced Zero-Shot Classification
Text-Aware Representation of Sentences (TARS) models represent a significant advancement in zero-shot learning capabilities. These specialized architectures build upon foundation models like BERT but incorporate additional mechanisms for handling classification tasks without task-specific training. TARS models demonstrate flexibility in adapting to new categorization schemes while maintaining robust performance.
The strength of TARS lies in its ability to understand contextual relationships between text and potential labels. This nuanced approach enables more accurate categorization, especially for complex tasks. Implementation involves pre-trained models applied to new domains with minimal adjustment, ideal for rapid deployment. This aligns well with modern conversational AI tools that require dynamic content understanding.
Prompt Engineering for Optimal Performance
Effective prompt engineering plays a crucial role in maximizing zero-shot learning performance. Since models rely on label representations, how labels are phrased impacts accuracy. Well-crafted prompts provide context for understanding category boundaries.
Best practices include using descriptive, unambiguous label names. For sentiment analysis, prompts like "text expressing satisfaction" and "text expressing criticism" yield better results. Advanced techniques use multiple prompt variations and ensemble methods to improve reliability, valuable for AI APIs and SDKs where consistent performance is critical.
Open Source Solutions and Implementation
The zero-shot learning ecosystem benefits from robust open-source implementations. Libraries like Hugging Face's Transformers provide pre-trained models for zero-shot tasks, while frameworks like SetFit offer efficient capabilities with minimal computational needs.
These solutions include pre-configured models, standardized APIs, documentation, and updates. For developers working with AI automation platforms, these reduce implementation barriers and provide a solid foundation for customization.
Practical Business Applications
Zero-shot learning delivers value in scenarios where traditional classification is impractical. Customer service categorizes support tickets into new issues without retraining. Marketing analyzes feedback across new products, and compliance monitors for unknown risks.
For AI agents and assistants, zero-shot capabilities enable adaptive interactions by understanding user requests outside trained domains. It also aids content moderation by identifying new inappropriate content based on semantic similarity.
Pros and Cons
Advantages
- Eliminates need for extensive labeled training datasets
- Enables classification of completely new, unseen categories
- Facilitates rapid adaptation to changing business requirements
- Reduces data preparation time and associated costs
- Supports knowledge transfer between related domains
Disadvantages
- May achieve lower accuracy than supervised learning with ample data
- Performance depends heavily on embedding quality and prompt design
- Can struggle with highly specialized or technical domain categories
Conclusion
Zero-shot learning represents a significant leap in making text classification more accessible and efficient. By reducing dependency on labeled datasets, it opens machine learning to organizations with dynamic needs. While not replacing supervised learning entirely, it offers a powerful alternative for flexibility and rapid adaptation, especially in applications involving text editors and content management systems.
Frequently Asked Questions
What is zero-shot learning in simple terms?
Zero-shot learning allows AI models to categorize text into classes they've never seen during training by understanding semantic relationships rather than relying on labeled examples for each specific category.
How does zero-shot learning differ from traditional classification?
Traditional classification requires extensive labeled data for each category, while zero-shot learning uses semantic understanding to classify unseen categories without specific training examples.
What are the main business benefits of zero-shot learning?
Key benefits include reduced data labeling costs, faster adaptation to new categories, handling dynamic classification needs, and enabling classification when labeled data is scarce.
Which industries benefit most from zero-shot text classification?
Customer service, content moderation, market research, compliance monitoring, and any field with evolving categories or emerging topics where labeling data is challenging.
What are the limitations of zero-shot learning?
Limitations include potential lower accuracy compared to supervised learning, dependence on embedding quality and prompt design, and challenges with ambiguous or highly technical content.