Annotation
- Introduction
- Evolution of Text Classification Techniques
- The Transformer Revolution in NLP
- Deep Learning Frameworks for Text Classification
- Transfer Learning with Pre-trained Models
- Practical Implementation with ULMFiT
- Pros and Cons
- Real-World Applications and Tools
- Enterprise Text Analysis with Gong.io
- Automated Email Tagging and Scheduling
- Future Directions in Text Classification
- Conclusion
- Frequently Asked Questions
Advanced Text Classification Guide: Deep Learning Frameworks & Techniques
Advanced text classification guide covering deep learning frameworks, BERT, transformers, transfer learning, and real-world applications for accurate

Introduction
Text classification represents a fundamental pillar of Natural Language Processing, empowering systems to automatically categorize and interpret unstructured text data. This comprehensive guide explores how deep learning frameworks have transformed text classification capabilities, enabling unprecedented accuracy in document categorization, sentiment analysis, and automated content organization. Whether you're building customer service automation or content moderation systems, understanding these advanced techniques is essential for modern AI applications.
Evolution of Text Classification Techniques
The progression of text classification methodologies reflects broader advances in computational linguistics and machine learning. Early approaches relied heavily on statistical methods that treated text as simple word collections without considering semantic relationships or contextual meaning.

The Bag of Words model emerged as an early standard, representing documents as word frequency vectors while completely ignoring grammar, word order, and semantic context. While straightforward to implement and providing interpretable results, BoW suffered from significant limitations including vocabulary constraints and inability to capture word relationships. For instance, it would treat "cat" and "kitten" as completely distinct entities with no semantic connection, and would process "the movie was funny and not boring" identically to "the movie was boring and not funny" – clearly problematic for accurate sentiment classification.
As computational resources expanded and neural network architectures matured, more sophisticated approaches emerged. Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs) began leveraging distributed word representations that captured semantic similarities through vector space models. This breakthrough allowed models to understand that related words should have similar vector representations, dramatically improving classification accuracy across various domains including AI chatbots and automated response systems.
The Transformer Revolution in NLP
The 2018 introduction of transformer architectures marked a watershed moment for natural language processing. These models employed self-attention mechanisms to process entire sequences simultaneously while capturing contextual relationships between all words in a document.
Models like BERT, ELMo, and GPT leveraged transformer architectures to generate contextual word embeddings – representations that vary based on surrounding words rather than maintaining static representations. This contextual understanding enabled unprecedented performance in tasks requiring nuanced language comprehension, from legal document analysis to medical text categorization. The computational demands of these models typically require GPU acceleration, but the accuracy improvements justify the infrastructure investment for production systems, particularly in AI automation platforms where precision is critical.
Deep Learning Frameworks for Text Classification
Modern text classification pipelines typically leverage established deep learning frameworks that provide comprehensive tooling for model development, training, and deployment. The ecosystem has matured significantly, offering multiple robust options suited to different use cases and team preferences.
TensorFlow, developed by Google, offers a production-ready ecosystem with extensive documentation and community support. Its static computation graph provides optimization opportunities that benefit large-scale deployment scenarios. PyTorch, favored by research communities, features dynamic computation graphs that enable more flexible model architectures and easier debugging workflows. Both frameworks integrate seamlessly with specialized NLP libraries like spaCy, which provides industrial-strength tokenization, part-of-speech tagging, and named entity recognition – essential preprocessing steps for effective text classification in AI APIs and SDKs.
Transfer Learning with Pre-trained Models
Transfer learning has dramatically reduced the data and computational requirements for building high-performance text classifiers. Instead of training models from scratch, practitioners can fine-tune models pre-trained on massive text corpora, adapting general language understanding to specific classification tasks.
This approach leverages the linguistic knowledge encoded in models like BERT, which have learned grammatical structures, semantic relationships, and even factual knowledge from training on Wikipedia, books, and web content. Fine-tuning requires significantly smaller labeled datasets – sometimes just hundreds or thousands of examples rather than millions – making sophisticated text classification accessible to organizations without massive data resources. This methodology has proven particularly valuable for AI writing tools that need to categorize content by tone, style, or subject matter.
Practical Implementation with ULMFiT
The Universal Language Model Fine-tuning (ULMFiT) approach provides a structured methodology for adapting pre-trained language models to specific text classification tasks. This three-phase process has become a standard workflow for many NLP practitioners.
First, start with a language model pre-trained on a large general corpus like Wikipedia. This model has already learned general language patterns and semantic relationships. Second, fine-tune this language model on domain-specific text – even unlabeled text from your target domain improves performance. Finally, add a classification layer and fine-tune the entire model on your labeled classification dataset. This gradual specialization approach typically outperforms training classifiers directly on limited labeled data.
For custom word embeddings, the process involves using Gensim to implement a sentence generator that feeds text to Word2Vec algorithms, training domain-specific embeddings that can then be integrated with spaCy pipelines for downstream classification tasks. This approach is especially valuable for conversational AI tools that need to understand domain-specific terminology and phrasing patterns.
Pros and Cons
Advantages
- Contextual understanding captures nuanced language meaning
- Transfer learning reduces data requirements significantly
- Pre-trained models provide strong baseline performance
- Framework ecosystems offer extensive tooling and support
- Scalable architectures handle large document volumes
- Continuous improvement through model fine-tuning
- Multilingual support through cross-lingual embeddings
Disadvantages
- Computational intensity requires GPU resources
- Model interpretability challenges for business users
- Domain adaptation still requires technical expertise
- Vocabulary limitations for highly specialized terminology
- Deployment complexity in production environments
Real-World Applications and Tools
Enterprise Text Analysis with Gong.io
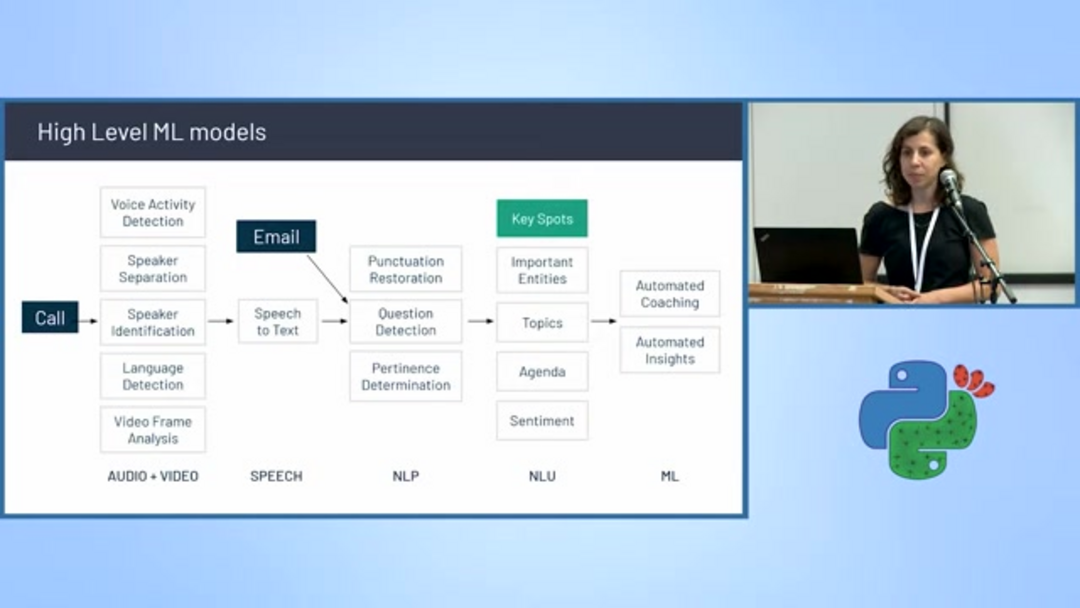
Commercial platforms like Gong.io demonstrate how advanced text classification transforms business operations, particularly in sales and customer success domains. The platform records, transcribes, and analyzes sales conversations using a sophisticated pipeline of machine learning models.
Gong's architecture incorporates multiple specialized classifiers including voice activity detection, speaker separation and identification, language detection, and speech-to-text conversion. Beyond basic transcription, the system performs advanced analysis including punctuation restoration, question detection, topic modeling, pertinence determination, agenda tracking, sentiment analysis, and entity extraction. This comprehensive approach enables AI agents and assistants to provide actionable insights to sales teams, highlighting competitive mentions, value proposition discussions, and objection handling patterns.
Automated Email Tagging and Scheduling
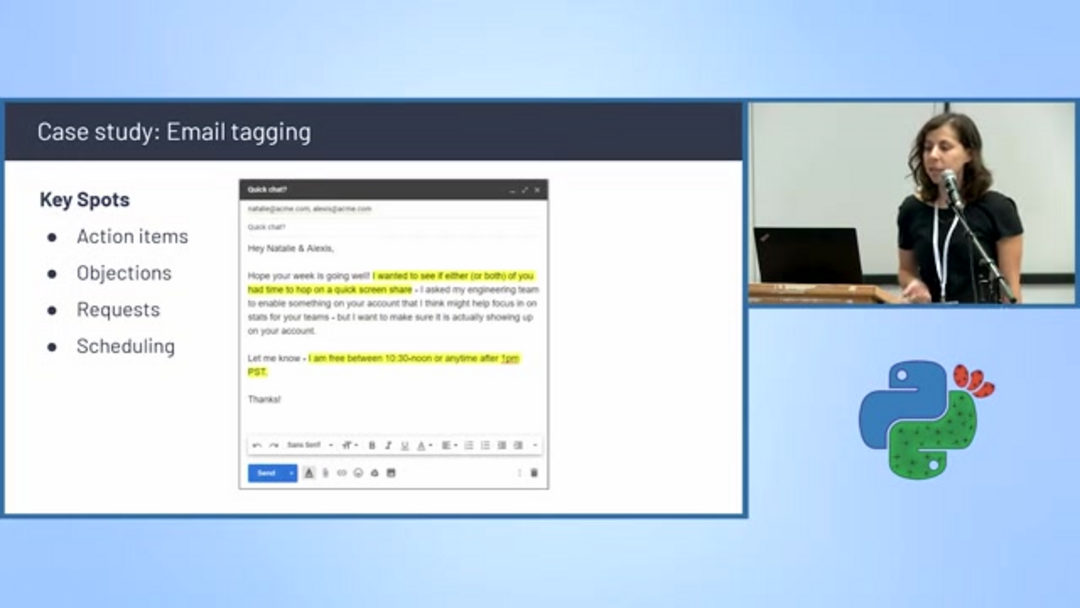
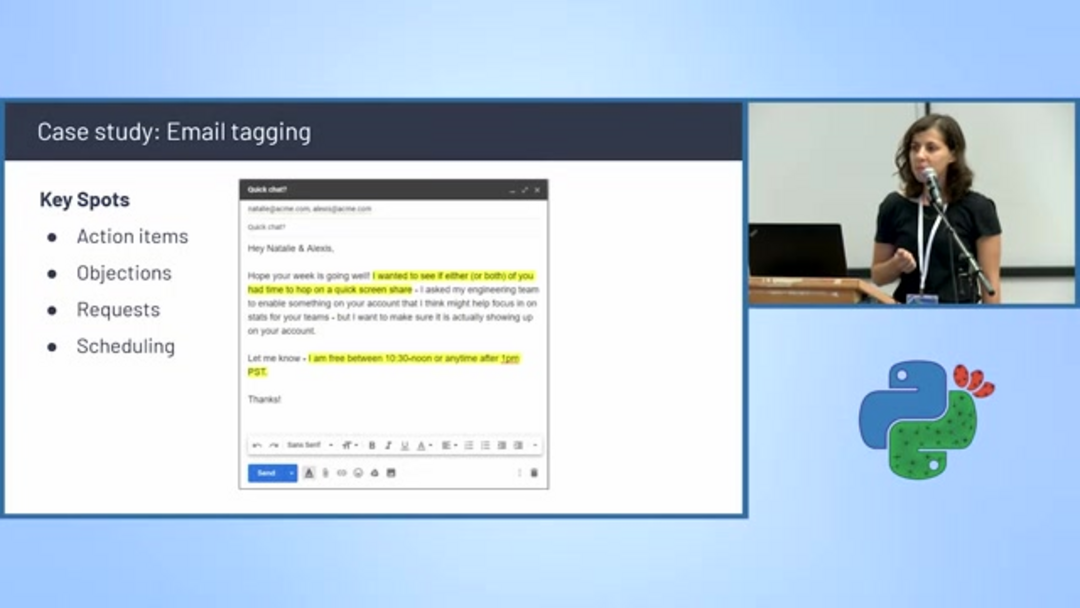
Text classification powers intelligent email management systems that automatically categorize messages and extract actionable information. Scheduling detection algorithms identify emails containing meeting proposals, availability discussions, and calendar coordination, automatically tagging them for priority handling.
These systems analyze key conversation elements including action items, objections, specific requests, and scheduling mentions. By filtering and categorizing emails based on content, businesses can streamline workflow management and ensure timely follow-up on critical communications. This capability is particularly valuable for AI email assistants that help manage overflowing inboxes and prioritize responses.
Future Directions in Text Classification
The field continues evolving rapidly, with several promising research directions addressing current limitations and expanding application possibilities. Explainable AI (XAI) focuses on making model decisions interpretable to human users, building trust and facilitating error analysis. Low-resource language modeling aims to extend sophisticated classification capabilities to languages with limited digital text resources.
Multimodal approaches integrate text with other data types like images and audio, creating richer understanding contexts – particularly valuable for social media analysis where text and visual content interact. Active learning strategies optimize annotation efforts by identifying the most informative samples for human review, while few-shot learning techniques enable effective model adaptation with minimal training examples, addressing one of the most significant pain points in machine learning deployment.
Conclusion
Text classification has evolved from simple statistical methods to sophisticated deep learning approaches that understand contextual nuance and semantic relationships. The combination of transformer architectures, transfer learning, and comprehensive frameworks has made high-accuracy classification accessible across diverse domains and applications. As research continues advancing explainability, efficiency, and multimodal capabilities, text classification will become increasingly integral to intelligent systems that process, organize, and derive insights from the ever-growing volumes of digital text. Mastering these techniques provides a significant competitive advantage in developing AI-powered solutions that understand and categorize human language with human-like comprehension.
Frequently Asked Questions
Why does word order matter in text classification?
Word order carries crucial semantic meaning – changing sequence can completely alter a sentence's meaning. Models that ignore word order cannot distinguish between 'the movie was funny and not boring' versus 'the movie was boring and not funny,' leading to inaccurate classification results, particularly in sentiment analysis.
What are the main steps for training custom word embeddings?
Training custom embeddings involves three key steps: implement a sentence generator using Gensim to feed text to the model, run Word2Vec or similar algorithms to train embeddings on your domain corpus, then integrate the trained model with spaCy or other NLP pipelines for downstream classification tasks requiring domain-specific language understanding.
How does transfer learning benefit text classification?
Transfer learning allows fine-tuning pre-trained models on specific tasks, reducing data requirements and improving accuracy by leveraging knowledge from large datasets, making it efficient for domain adaptation.
What are the key advantages of transformer models in NLP?
Transformer models use self-attention to process sequences in parallel, capturing contextual relationships between words, leading to better performance in tasks like text classification and sentiment analysis.
How can text classification be applied in business environments?
Text classification is used in customer service automation, content moderation, email categorization, and sales analysis, helping businesses automate processes and gain insights from text data.