Annotation
- Introducción
- Comprendiendo YOLO y la Detección de Objetos Moderna
- Configuración del Entorno: Google Colab y Desarrollo Local
- Construyendo Conjuntos de Datos Personalizados de Alta Calidad
- Anotación Eficiente con Label Studio
- Entrenamiento del Modelo en Google Colab
- Despliegue Local e Implementación Práctica
- Pros y Contras
- Conclusión
- Preguntas frecuentes
Detección de objetos YOLOv11: Guía completa de entrenamiento 2024
Aprende a entrenar e implementar YOLOv11 para detección de objetos usando Google Colab y Label Studio. Esta guía cubre la creación de conjuntos de datos, anotación, modelo
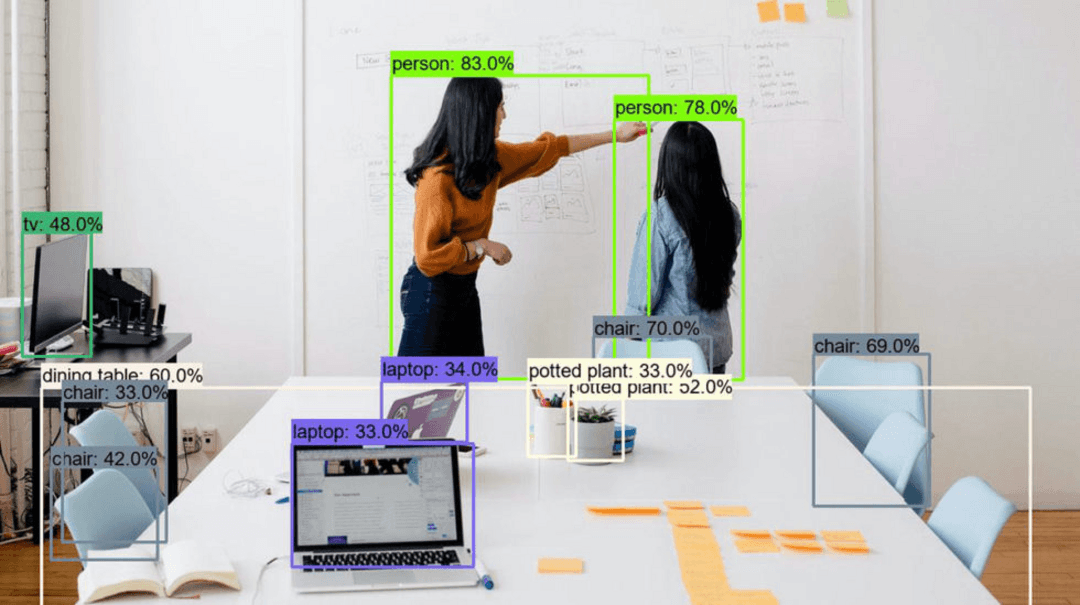
Introducción
YOLOv11 representa la vanguardia en tecnología de detección de objetos en tiempo real, construyendo sobre la arquitectura revolucionaria You Only Look Once. Esta guía completa te lleva a través del entrenamiento de modelos YOLO personalizados utilizando herramientas accesibles como Google Colab, creando conjuntos de datos especializados y desplegando tus modelos entrenados para aplicaciones prácticas. Ya sea que estés desarrollando sistemas de visión por computadora para vehículos autónomos, análisis minorista o proyectos creativos, este tutorial proporciona la base para construir soluciones robustas de detección de objetos.
Comprendiendo YOLO y la Detección de Objetos Moderna
YOLO (You Only Look Once) ha transformado la visión por computadora al consolidar la detección de objetos en un proceso de una sola etapa, ofreciendo mejoras notables en velocidad sobre los marcos tradicionales de dos etapas. YOLOv11 continúa esta innovación con refinamientos arquitectónicos que mejoran tanto la precisión como la eficiencia. El modelo procesa imágenes completas en un solo paso hacia adelante a través de la red neuronal, prediciendo simultáneamente cuadros delimitadores y probabilidades de clase. Este enfoque hace que YOLOv11 sea particularmente valioso para aplicaciones en tiempo real donde la latencia importa, como vigilancia por video, navegación autónoma y sistemas interactivos.
La detección de objetos representa un avance significativo más allá de la clasificación básica de imágenes. Mientras que la clasificación simplemente identifica lo que hay en una imagen, la detección localiza con precisión objetos con cuadros delimitadores y asigna etiquetas apropiadas. Esta comprensión granular permite aplicaciones en numerosas plataformas de automatización de IA, desde control de calidad industrial hasta análisis de imágenes médicas. La versatilidad de la tecnología la hace accesible para desarrolladores que trabajan con varios APIs y SDKs de IA para integrarlos en sistemas más grandes.
Configuración del Entorno: Google Colab y Desarrollo Local
Google Colab proporciona un punto de partida ideal para el entrenamiento de modelos YOLO, ofreciendo acceso gratuito a recursos GPU que aceleran drásticamente el proceso computacionalmente intensivo. Esta plataforma basada en la nube elimina la necesidad de inversiones costosas en hardware, haciendo que el aprendizaje profundo sea accesible para desarrolladores individuales y equipos pequeños. Para comenzar, asegúrate de tener una cuenta activa de Google y navega a colab.research.google.com. La interfaz de cuaderno Jupyter de la plataforma simplifica la ejecución de código y la experimentación.
Para el despliegue y prueba local, Anaconda ofrece una solución robusta para gestionar entornos Python y dependencias. Descarga la distribución desde anaconda.com y sigue el asistente de instalación. Esta configuración proporciona entornos aislados donde puedes instalar versiones específicas de paquetes sin conflictos. Crear entornos dedicados para diferentes proyectos asegura la reproducibilidad y simplifica la gestión de dependencias en múltiples escenarios de alojamiento de modelos de IA y objetivos de despliegue.
Construyendo Conjuntos de Datos Personalizados de Alta Calidad
La base de cualquier modelo exitoso de detección de objetos reside en sus datos de entrenamiento. Un conjunto de datos bien estructurado y diverso impacta directamente en la precisión del modelo y las capacidades de generalización. Para proyectos de prueba de concepto, apunta a 100-200 imágenes cuidadosamente curadas que representen la variedad de condiciones que tu modelo encontrará en producción. Esto incluye diferentes escenarios de iluminación, fondos, orientaciones de objetos y posibles oclusiones.
Las estrategias de recolección de datos varían según los requisitos del proyecto. Para aplicaciones personalizadas como nuestro ejemplo de detección de dulces, captura imágenes usando teléfonos inteligentes o cámaras web en múltiples entornos. Complementa tu colección con conjuntos de datos disponibles públicamente de plataformas como Roboflow Universe o Kaggle, pero siempre verifica la precisión de las etiquetas y la relevancia para tu caso de uso específico. Organiza tus imágenes en estructuras de carpetas lógicas, como un directorio principal "yolo" con subcarpetas para diferentes categorías de objetos o fuentes de datos.
Anotación Eficiente con Label Studio
Label Studio agiliza el crucial proceso de anotación con una interfaz web intuitiva y potentes funciones de automatización. Esta herramienta de código abierto admite varios tipos de anotación, siendo los cuadros delimitadores esenciales para tareas de detección de objetos. El proceso de instalación comienza creando un entorno Conda dedicado para mantener dependencias limpias: conda create --name yolo-env python=3.12 seguido de pip install label-studio.
El flujo de trabajo de anotación implica crear un nuevo proyecto, importar imágenes en lotes (hasta 100 a la vez para evitar limitaciones del servidor) y configurar la interfaz de etiquetado para detección de objetos. Reemplaza las etiquetas predeterminadas con tus nombres de clase específicos, luego anota sistemáticamente cada imagen dibujando cuadros delimitadores alrededor de los objetos objetivo. Utiliza atajos de teclado para eficiencia – presionar teclas numéricas correspondientes a los índices de clase acelera significativamente el proceso. Una vez completada la anotación, exporta tus datos en formato YOLO, que empaqueta imágenes y archivos de etiquetas correspondientes en un archivo descargable.
Entrenamiento del Modelo en Google Colab
Con los datos anotados preparados, pasa a Google Colab para el entrenamiento del modelo. Habilita la aceleración GPU a través de Runtime → Change runtime type → GPU para aprovechar las Unidades de Procesamiento Tensor para cálculos más rápidos. El proceso de entrenamiento involucra varios parámetros configurables: arquitectura del modelo (YOLOv11s para velocidad vs. YOLOv11 para precisión), resolución de entrada (típicamente 640x640 píxeles) y duración del entrenamiento (épocas).
Monitorea el progreso del entrenamiento a través de métricas como pérdida, precisión, recuperación y precisión media promedio (mAP). Estos indicadores ayudan a identificar cuándo los modelos convergen o requieren ajuste. Para un rendimiento subóptimo, considera estrategias como aumento de datos, programación de la tasa de aprendizaje o modificaciones arquitectónicas. El proceso de entrenamiento genera pesos del modelo (best.pt) y visualizaciones de resultados integrales en el directorio de salida, proporcionando información para la mejora iterativa e integración con varios agentes y asistentes de IA.
Despliegue Local e Implementación Práctica
Desplegar modelos entrenados localmente requiere la biblioteca Ultralytics (pip install ultralytics) y tus pesos de modelo exportados. Crea scripts Python que carguen el modelo, procesen imágenes de entrada o flujos de video y muestren los resultados de detección. El script de despliegue debe manejar varias fuentes de entrada – imágenes estáticas, archivos de video o flujos de cámara en tiempo real – mientras proporciona parámetros configurables para umbrales de confianza y formato de salida.
Para la aplicación de contador de calorías de dulces, extiende la funcionalidad básica de detección mapeando los tipos de dulces detectados a información nutricional. Esto demuestra cómo la detección de objetos sirve como base para aplicaciones más complejas que combinan visión por computadora con lógica de negocio. Tales implementaciones muestran el valor práctico de integrar modelos YOLO con herramientas de captura de pantalla y utilidades de conversión de imágenes para soluciones integrales de flujo de trabajo.
Pros y Contras
Ventajas
- Capacidades de procesamiento en tiempo real para video y transmisiones en vivo
- Arquitectura de una sola etapa ofrece velocidad excepcional
- Implementación de código abierto con soporte activo de la comunidad
- Personalización flexible para tipos de objetos específicos
- Compatible con varias plataformas de despliegue
- Mejoras continuas a través de actualizaciones de versión
- Extensa documentación y recursos de tutoriales
Desventajas
- Requiere datos etiquetados sustanciales para el entrenamiento
- Computacionalmente intensivo durante la fase de entrenamiento
- Dificultades con objetos muy pequeños o superpuestos
- Compromisos de precisión con variantes de modelo más rápidas
- Adaptación de dominio necesaria para aplicaciones especializadas
Conclusión
YOLOv11 democratiza la detección avanzada de objetos con rendimiento de vanguardia y herramientas accesibles. Esta guía capacita a los desarrolladores para construir sistemas de visión personalizados sin experiencia extensa en ML. La velocidad y precisión de YOLO son indispensables para aplicaciones del mundo real. Domina estas técnicas para unir teoría y práctica utilizando directorios de herramientas de IA para la innovación.
Preguntas frecuentes
¿Puedo usar conjuntos de datos preexistentes para el entrenamiento de YOLO?
Sí, plataformas como Roboflow Universe, Kaggle y Google Open Images ofrecen conjuntos de datos preetiquetados. Siempre verifica la calidad de los datos y su relevancia para tu caso de uso específico antes del entrenamiento.
¿Cómo puedo mejorar el rendimiento del modelo YOLO?
Mejora el rendimiento verificando la precisión de las etiquetas, aumentando las épocas de entrenamiento, utilizando arquitecturas de modelo más grandes, expandiendo la diversidad del conjunto de datos e implementando técnicas de aumento de datos.
¿Cuáles son las ventajas de Google Colab para el entrenamiento de YOLO?
Google Colab proporciona acceso gratuito a GPU, elimina los requisitos de hardware local, ofrece funciones colaborativas e incluye bibliotecas de aprendizaje automático preinstaladas para un desarrollo rápido.
¿Cuáles son las mejoras clave en YOLOv11?
YOLOv11 introduce una arquitectura mejorada para una mejor precisión y eficiencia, técnicas de entrenamiento mejoradas y rendimiento optimizado para detección en tiempo real en comparación con versiones anteriores.
¿Cuánto tiempo lleva entrenar un modelo YOLOv11?
El tiempo de entrenamiento varía según el tamaño del conjunto de datos, la arquitectura del modelo y el hardware. Usando Google Colab con GPU, puede tomar desde unas pocas horas hasta un día para conjuntos de datos estándar.
Artículos relevantes sobre IA y tendencias tecnológicas
Mantente al día con las últimas ideas, herramientas e innovaciones que dan forma al futuro de la IA y la tecnología.
Grok AI: Generación Ilimitada de Videos Gratuita a partir de Texto e Imágenes | Guía 2024
Grok AI ofrece generación ilimitada de videos gratuita a partir de texto e imágenes, haciendo accesible la creación de videos profesionales para todos sin necesidad de habilidades de edición.
Las 3 mejores extensiones gratuitas de IA para programar en VS Code 2025 - Aumenta la productividad
Descubre las mejores extensiones gratuitas de agentes de IA para programar en Visual Studio Code en 2025, incluyendo Gemini Code Assist, Tabnine y Cline, para mejorar tu
Configuración de Grok 4 Fast en Janitor AI: Guía Completa de Juego de Roles Sin Filtros
Guía paso a paso para configurar Grok 4 Fast en Janitor AI para juego de roles sin restricciones, incluyendo configuración de API, ajustes de privacidad y consejos de optimización