Annotation
- Introducción
- Comprendiendo el Rol de la IA en la Generación de Datos
- Construyendo un Generador de Pokémon: Aprovechando Arreglos
- Creando un Clasificador de Sentimiento: Aprovechando Enumeraciones
- Comparando la Generación de Arreglos y Enumeraciones
- Personalizando la Salida de Datos de IA con Zod
- Pros y Contras
- Conclusión
- Preguntas frecuentes
Datos Estructurados de IA: Guía de Arreglos y Enumeraciones para Desarrolladores | ToolPicker
Esta guía explora el uso de arreglos y enumeraciones en SDKs de IA para la generación de datos estructurados, con ejemplos prácticos como generadores de Pokémon y análisis de sentimientos.

Introducción
A medida que la inteligencia artificial continúa transformando el desarrollo de software, dominar la generación de datos estructurados se vuelve esencial para construir aplicaciones robustas. Esta guía completa explora cómo los desarrolladores pueden aprovechar arreglos y enumeraciones dentro de los SDK de IA para crear salidas organizadas y predecibles. Estas estructuras de datos permiten un procesamiento más eficiente, mejor seguridad de tipos y experiencias de usuario mejoradas en aplicaciones impulsadas por IA en varios dominios.
Comprendiendo el Rol de la IA en la Generación de Datos
El desarrollo de software tradicional a menudo requiere la definición manual de estructuras de datos, pero los SDK de IA ahora permiten una generación dinámica que se adapta a requisitos específicos. Este cambio de paradigma permite que las aplicaciones sean más flexibles y respondan a las necesidades del usuario. Los arreglos y las enumeraciones representan dos patrones fundamentales que los desarrolladores pueden implementar para estructurar las salidas de IA de manera efectiva. Los arreglos organizan elementos relacionados en listas, mientras que las enumeraciones clasifican los datos en categorías predefinidas, ambos proporcionando beneficios significativos para la validación de datos y la eficiencia del procesamiento.
La integración de estas estructuras con herramientas de desarrollo modernas crea combinaciones poderosas para construir aplicaciones inteligentes. Al trabajar con APIs y SDKs de IA, comprender cómo implementar correctamente arreglos y enumeraciones puede mejorar drásticamente la consistencia de la salida y la confiabilidad de la aplicación.
Construyendo un Generador de Pokémon: Aprovechando Arreglos
Los arreglos sirven como base para gestionar colecciones de objetos similares en datos generados por IA. Considere un ejemplo práctico donde necesita generar listas de Pokémon basadas en tipos específicos como 'fuego' o 'agua'. Usando un SDK de IA, puede instruir al modelo para que produzca arreglos estructurados que contengan nombres de Pokémon y sus habilidades asociadas. Este enfoque requiere definir un esquema claro para objetos individuales de Pokémon, luego envolver este esquema en una estructura de arreglo.
La implementación típicamente implica usar Zod, una biblioteca de validación de esquemas con prioridad en TypeScript, para definir la estructura de datos:
import { z } from "zod";
export const pokemonSchema = z.object({
name: z.string(),
abilities: z.array(z.string()),
});
export const pokemonUISchema = z.array(pokemonSchema);Esta definición de esquema asegura que cada objeto Pokémon contenga una cadena de nombre y un arreglo de cadenas de habilidades. El pokemonUISchema luego especifica que la IA debe generar múltiples instancias de estos objetos, creando una lista coherente. El aspecto de ingeniería de prompts implica instruir a la IA para que 'Genere una lista de 5 Pokémon de tipo {type}', donde el parámetro de tipo se ajusta dinámicamente basado en la entrada del usuario.
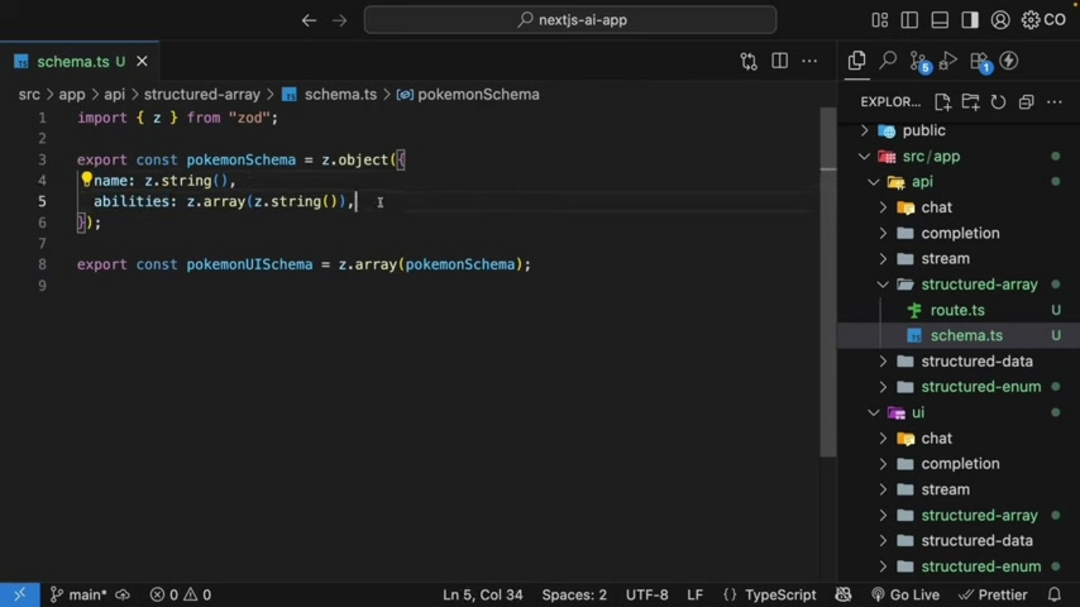
Las consideraciones clave de implementación incluyen una validación adecuada del esquema, la especificación de salida en los manejadores de ruta y asegurar que la IA comprenda el contexto del arreglo. Este enfoque demuestra cómo los arreglos pueden organizar colecciones complejas de datos para aplicaciones que requieren múltiples objetos similares, haciéndolo particularmente útil para plataformas de automatización de IA que manejan tareas repetitivas de generación de datos.
Creando un Clasificador de Sentimiento: Aprovechando Enumeraciones
Las enumeraciones proporcionan un enfoque estructurado para tareas de clasificación donde las salidas deben caer dentro de categorías predefinidas. Un clasificador de análisis de sentimiento ilustra perfectamente este concepto, donde el texto debe ser categorizado como positivo, negativo o neutral. A diferencia de los arreglos, las enumeraciones no requieren definiciones complejas de esquema; en cambio, los desarrolladores especifican directamente los valores posibles dentro del manejador de ruta.
La implementación típicamente usa la función generateObject en lugar de enfoques de streaming:
import { generateObject } from "ai";
import { openAI } from "@ai-sdk/openai";
export async function POST(req: Request) {
try {
const { text } = await req.json();
const result = await generateObject({
model: openAI("gpt-4.1-mini"),
output: "enum",
enum: ["positive", "negative", "neutral"],
prompt: `Clasifica el sentimiento en este texto: ${text}`,
});
return result.toJsonResponse();
} catch (error) {
console.error("Error generando sentimiento", error);
return new Response("Error al generar sentimiento", { status: 500 });
}
}
Los factores críticos para una implementación exitosa de enumeraciones incluyen la selección del modelo – modelos más capaces como GPT-4.1-mini proporcionan mejor consistencia – y una definición clara de los valores de enumeración. Este enfoque asegura que las salidas de IA permanezcan dentro de los límites esperados, haciéndolo invaluable para agentes y asistentes de IA que requieren capacidades de clasificación confiables.
Comparando la Generación de Arreglos y Enumeraciones
Comprender las distinciones entre la generación de arreglos y enumeraciones ayuda a los desarrolladores a seleccionar la estructura de datos apropiada para casos de uso específicos. Los arreglos sobresalen en la gestión de colecciones de objetos, mientras que las enumeraciones se especializan en tareas de clasificación donde las salidas deben conformarse a categorías predefinidas. Las diferencias de implementación se extienden más allá de los requisitos de esquema para incluir las funciones del SDK de IA utilizadas y cómo se procesan los datos.
Los arreglos típicamente funcionan con streamObject para la generación progresiva de datos, haciéndolos adecuados para grandes conjuntos de datos o aplicaciones en tiempo real. Las enumeraciones, sin embargo, funcionan mejor con generateObject ya que producen valores de clasificación únicos. La tabla siguiente destaca las diferencias clave:
| Característica | Arreglos | Enumeraciones |
|---|---|---|
| Estructura de Datos | Lista de objetos | Categorías predefinidas |
| Esquema Requerido | Sí, define la estructura del objeto | No, los valores se definen en el manejador |
| Tipo de Salida | array | enum |
| Función del SDK de IA | streamObject | generateObject |
| Caso de Uso | Colecciones de objetos similares | Clasificación y categorización |
| Procesamiento de Datos | Retorna un arreglo de objetos | Retorna un único valor clasificado |
Estas diferencias estructurales impactan cómo los desarrolladores abordan la ingeniería de prompts de IA y el manejo de salidas, haciendo que la selección adecuada sea crucial para el éxito de la aplicación.
Personalizando la Salida de Datos de IA con Zod
Zod proporciona capacidades extensas para definir y validar esquemas en aplicaciones TypeScript, ofreciendo validación con seguridad de tipos que asegura que los datos generados por IA cumplan con requisitos estructurales específicos. Más allá de las implementaciones básicas de arreglos y enumeraciones, Zod admite escenarios de validación complejos que mejoran la confiabilidad de los datos y la robustez de la aplicación.
Las características avanzadas de Zod incluyen validación de objetos complejos para estructuras de datos anidadas, funciones de validación personalizadas para reglas específicas de la aplicación, y transformaciones de datos que modifican las salidas para adaptarse mejor a las necesidades de la aplicación. Estas capacidades se vuelven particularmente valiosas al trabajar con herramientas de escritura de IA que generan contenido estructurado o al implementar reglas de formateo de código para salidas generadas.
Al combinar el poder de validación de Zod con la generación de datos de IA, los desarrolladores pueden crear aplicaciones más confiables que manejen datos estructurados efectivamente mientras mantienen la seguridad de tipos y la integridad de los datos a lo largo de la canalización de procesamiento.
Pros y Contras
Ventajas
- Mejor consistencia y predictibilidad de los datos en las salidas de IA
- Seguridad de tipos mejorada y reducción de errores en tiempo de ejecución
- Organización estructurada de datos para una mejor arquitectura de aplicación
- Flujos de trabajo de validación y procesamiento de datos más fáciles
- Mejor integración con herramientas y bibliotecas de desarrollo existentes
- Código de aplicación de IA más mantenible y escalable
- Separación clara entre la estructura de datos y la lógica de negocio
Desventajas
- Complejidad adicional en la definición y validación del esquema
- Sobrecarga potencial de rendimiento con validaciones complejas
- Curva de aprendizaje para desarrolladores nuevos en datos estructurados de IA
- Flexibilidad limitada para patrones de datos dinámicos o impredecibles
- Dependencia de modelos específicos de IA para la consistencia de las enumeraciones
Conclusión
Dominar arreglos y enumeraciones para la generación de datos estructurados de IA representa un avance significativo en el desarrollo de software moderno. Estas estructuras de datos proporcionan la base para construir aplicaciones de IA confiables y mantenibles que producen salidas consistentes y validadas. Al comprender cuándo usar arreglos para colecciones de objetos y enumeraciones para tareas de clasificación, los desarrolladores pueden crear aplicaciones más robustas que aprovechen las capacidades de IA de manera efectiva. La integración con bibliotecas de validación como Zod mejora aún más la confiabilidad de los datos, mientras que las consideraciones de implementación adecuadas aseguran un rendimiento óptimo y una experiencia de usuario en varias aplicaciones impulsadas por IA.
Preguntas frecuentes
¿Cuál es el principal beneficio de usar arreglos para datos generados por IA?
Los arreglos proporcionan organización estructurada para listas de puntos de datos relacionados, permitiendo iteración predecible y procesamiento de múltiples elementos. Esto es esencial cuando la IA genera colecciones de objetos similares como productos o resultados de búsqueda, mejorando la gestión de datos y la confiabilidad de la aplicación.
¿Cuándo deben los desarrolladores elegir enumeraciones sobre otras estructuras de datos?
Las enumeraciones son ideales para tareas de clasificación donde las salidas deben ajustarse a categorías predefinidas. Restringen las respuestas de IA a valores específicos, asegurando consistencia en análisis de sentimientos, clasificación de estados y procesos de toma de decisiones, mejorando la robustez de la aplicación.
¿Pueden las enumeraciones funcionar con streamObject en SDKs de IA?
No, las enumeraciones están diseñadas específicamente para generateObject, que devuelve valores de clasificación únicos. Para datos en flujo, los desarrolladores deben usar arreglos u otras estructuras que admitan generación de salida progresiva y procesamiento en tiempo real.
¿Por qué la selección del modelo importa para la generación de enumeraciones?
Los modelos de IA más capaces proporcionan mejor consistencia en la generación de valores de enumeración correctos. Los modelos menos avanzados pueden tener dificultades con categorías predefinidas, lo que lleva a resultados impredecibles. Seleccionar modelos apropiados garantiza una salida de clasificación confiable.
¿Cómo mejora Zod la validación de datos de IA?
Zod proporciona validación de esquemas con seguridad de tipos que garantiza que los datos generados por IA cumplan con los requisitos estructurales, reduciendo errores y mejorando la confiabilidad de la aplicación mediante esquemas definidos para arreglos, enumeraciones y objetos complejos.
Artículos relevantes sobre IA y tendencias tecnológicas
Mantente al día con las últimas ideas, herramientas e innovaciones que dan forma al futuro de la IA y la tecnología.
Grok AI: Generación Ilimitada de Videos Gratuita a partir de Texto e Imágenes | Guía 2024
Grok AI ofrece generación ilimitada de videos gratuita a partir de texto e imágenes, haciendo accesible la creación de videos profesionales para todos sin necesidad de habilidades de edición.
Configuración de Grok 4 Fast en Janitor AI: Guía Completa de Juego de Roles Sin Filtros
Guía paso a paso para configurar Grok 4 Fast en Janitor AI para juego de roles sin restricciones, incluyendo configuración de API, ajustes de privacidad y consejos de optimización
Las 3 mejores extensiones gratuitas de IA para programar en VS Code 2025 - Aumenta la productividad
Descubre las mejores extensiones gratuitas de agentes de IA para programar en Visual Studio Code en 2025, incluyendo Gemini Code Assist, Tabnine y Cline, para mejorar tu