Annotation
- Introduction
- La puissance du langage écrit et des décisions basées sur les données
- Le défi des données non structurées
- Une perspective historique sur l'enregistrement des données
- De l'OCR à l'intelligence documentaire : Évolution et défis
- Modèles GPT : Une percée dans la compréhension des documents
- Exploiter les LLM et les agents IA pour l'intelligence documentaire
- Avantages et inconvénients
- Conclusion
- Questions fréquemment posées
Intelligence documentaire IA : Transformez les données non structurées en informations commerciales
L'intelligence documentaire IA utilise des modèles GPT et l'apprentissage automatique pour extraire des informations de données non structurées comme les contrats et les rapports, permettant
Introduction
Dans le paysage commercial axé sur les données d'aujourd'hui, les organisations font face à un défi crucial : extraire des insights significatifs des vastes quantités de données non structurées enfermées dans les documents. Des contrats et rapports aux e-mails et factures, ces informations représentent un potentiel inexploité pour une prise de décision éclairée. Les solutions d'intelligence documentaire alimentées par l'IA révolutionnent la façon dont les entreprises traitent, analysent et exploitent ces données, transformant le texte chaotique en intelligence structurée et actionnable qui stimule l'efficacité opérationnelle et l'avantage stratégique.
La puissance du langage écrit et des décisions basées sur les données
Le langage écrit représente l'une des réalisations technologiques les plus significatives de l'humanité, évoluant des peintures rupestres anciennes aux documents numériques d'aujourd'hui. Eric Pritchett, Président/COO de Terzo, souligne que la communication écrite sert de fondement pour enregistrer l'histoire, partager les connaissances et s'appuyer sur la sagesse collective. Chaque avancée – des hiéroglyphes à la presse de Gutenberg en passant par les formats numériques modernes – a progressivement amélioré notre capacité à communiquer des idées complexes et à préserver la connaissance institutionnelle. Dans les environnements commerciaux contemporains, le défi est passé de simplement enregistrer l'information à en extraire efficacement de la valeur. Les organisations génèrent des millions de documents annuellement, mais la plupart restent sous-utilisés en raison de leur nature non structurée. Cela représente une opportunité massive pour les plateformes d'automatisation IA de transformer la façon dont les entreprises exploitent leurs actifs de connaissance documentés.
Le défi des données non structurées
Les documents non structurés présentent un paysage complexe pour les systèmes de traitement de données traditionnels. Contrairement aux bases de données structurées avec des champs et des relations prédéfinis, les documents contiennent du texte libre, des formats variés, des tableaux et des informations contextuelles que les machines ont du mal à interpréter de manière cohérente. Ces données non structurées englobent tout, des contrats juridiques avec une terminologie spécialisée aux rapports financiers contenant des relations numériques complexes. La diversité des types de documents crée des défis de traitement significatifs, y compris des contrats avec des clauses juridiques variables, des états financiers avec des tableaux intégrés, de la documentation technique avec un vocabulaire spécialisé et des communications clients avec des modèles de langage informels. Les approches traditionnelles nécessitent un examen manuel approfondi et une saisie de données, créant des goulots d'étranglement et augmentant le risque d'erreur humaine. C'est là que les agents et assistants IA démontrent leur valeur en automatisant le processus d'extraction et de structuration.
Une perspective historique sur l'enregistrement des données
Le parcours de l'humanité avec l'enregistrement des données révèle un schéma constant d'innovation technologique visant à préserver et partager l'information. Les premières civilisations utilisaient des peintures rupestres pour documenter les succès de chasse et les schémas saisonniers, tandis que les anciens Égyptiens développaient les hiéroglyphes pour enregistrer des textes administratifs et religieux. Ces premiers systèmes ont établi le besoin fondamental de documentation fiable qui persiste dans les contextes commerciaux modernes. La révolution de l'imprimerie a démocratisé l'accès à la connaissance écrite, tandis que la photocopie et les formats numériques ont encore accéléré la distribution de l'information. Aujourd'hui, nous sommes à un autre point d'inflexion où les systèmes alimentés par l'IA peuvent non seulement stocker et distribuer des documents, mais comprendre leur contenu et extraire automatiquement des insights significatifs. Les outils d'édition de documents modernes intègrent ces capacités intelligentes directement dans les processus de workflow.
De l'OCR à l'intelligence documentaire : Évolution et défis
La technologie de reconnaissance optique de caractères a représenté une étape importante dans la numérisation des documents, permettant la conversion d'images scannées en texte lisible par machine. Cependant, l'OCR opère à un niveau superficiel – elle reconnaît les caractères et les mots mais manque de compréhension de leur sens ou de leurs relations. Lors du traitement de documents complexes comme des factures ou des contrats, l'OCR génère du texte brut sans comprendre les connexions sémantiques entre les points de données. Considérez comment l'OCR traite un tableau financier : il identifie avec précision les chiffres et les étiquettes mais ne reconnaît pas que « Revenus T3 » est lié à « 2,4 M$ » dans la cellule adjacente. Cette limitation devient particulièrement problématique avec les mises en page à plusieurs colonnes, les annotations manuscrites, les scans basse résolution et les documents en langues mixtes. Ces contraintes soulignent le besoin de solutions plus sophistiquées qui vont au-delà de la reconnaissance de caractères vers une véritable compréhension des documents. Les plateformes d'intelligence documentaire modernes représentent un saut quantique au-delà de la technologie OCR de base. En combinant le traitement du langage naturel, l'apprentissage automatique et la vision par ordinateur, ces systèmes peuvent comprendre le contenu des documents à un niveau conceptuel. Ils ne font pas que lire le texte – ils comprennent le contexte, identifient les entités, extraient les relations et classent les informations selon les règles commerciales. Les capacités incluent la compréhension sémantique, l'extraction intelligente de données, la classification des documents, la cartographie des relations et la validation de la qualité. Ces capacités rendent l'intelligence documentaire particulièrement précieuse pour les workflows d'édition et de traitement PDF où les documents contiennent souvent des informations commerciales critiques.
Modèles GPT : Une percée dans la compréhension des documents
Les Transformers Pré-entraînés Génératifs ont révolutionné l'intelligence documentaire en apportant une compréhension quasi humaine aux systèmes automatisés. Ces grands modèles de langage, entraînés sur d'immenses corpus de texte, démontrent une capacité remarquable à comprendre la nuance, le contexte et les modèles linguistiques subtils qui échappaient aux technologies précédentes. Les modèles GPT excellent dans la compréhension contextuelle de la terminologie spécialisée, l'identification des relations implicites, la synthèse de documents complexes, l'adaptation à différents styles d'écriture et la génération de sorties structurées à partir d'entrées non structurées. L'architecture technique implique des couches d'embedding, des mécanismes d'attention, des blocs de transformateurs, des couches de normalisation et des projections de sortie qui travaillent de concert pour traiter l'information efficacement.
Exploiter les LLM et les agents IA pour l'intelligence documentaire
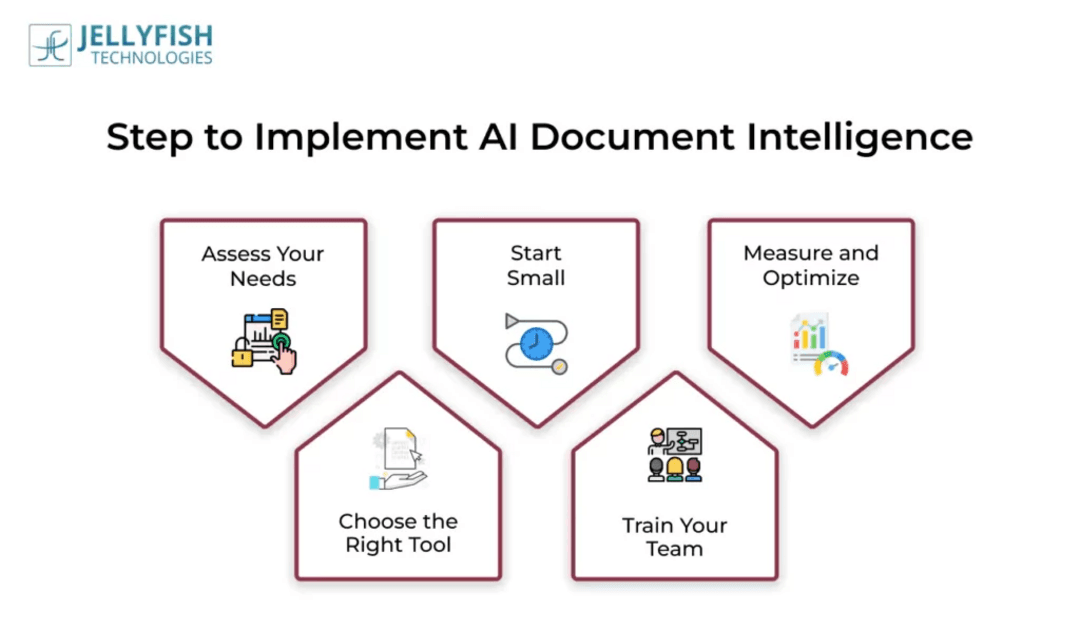
La mise en œuvre d'un système d'intelligence documentaire efficace nécessite une planification minutieuse et une exécution stratégique. Les organisations devraient aborder cette transformation méthodiquement pour garantir une adoption réussie et un retour sur investissement maximal. Les étapes clés incluent la définition d'objectifs clairs, la sélection de la technologie appropriée, la préparation des données, la mise en œuvre d'une automatisation progressive, l'intégration avec les systèmes commerciaux, l'établissement de protocoles de surveillance et la planification de l'évolution. Une mise en œuvre réussie implique souvent de tirer parti des API et SDK IA pour construire des intégrations personnalisées qui répondent aux besoins organisationnels spécifiques. Le paysage tarifaire pour les solutions d'intelligence documentaire varie en fonction du modèle de déploiement, de l'ensemble de fonctionnalités et des exigences d'échelle, avec des facteurs comme la tarification basée sur le volume, les niveaux de fonctionnalités, les options de déploiement et les services de support influençant les coûts. De nombreux fournisseurs offrent des modèles flexibles incluant des frais par document, des abonnements mensuels et des accords d'entreprise.
Avantages et inconvénients
Avantages
- Réduit significativement le temps de saisie et de traitement manuel des données
- Améliore la précision et la cohérence des données à travers les types de documents
- Permet une prise de décision plus rapide avec l'extraction de données en temps réel
- Évolue efficacement pour gérer les volumes croissants de documents
- Identifie des modèles et des insights cachés dans les données non structurées
- Réduit les coûts opérationnels grâce à l'automatisation des tâches répétitives
- Améliore la conformité grâce à un traitement cohérent des documents
Inconvénients
- Nécessite un investissement initial en technologie et en mise en œuvre
- Peut produire des erreurs lors du déploiement initial et de la formation
- Nécessite une maintenance continue et un raffinement des modèles
- Pourrait introduire des biais si les données d'entraînement ne sont pas représentatives
- Exige une expertise technique pour une configuration optimale
Conclusion
L'intelligence documentaire alimentée par l'IA représente une technologie transformative qui aborde l'un des défis les plus persistants des entreprises : débloquer la valeur piégée dans les documents non structurés. En allant au-delà de la simple reconnaissance de caractères vers une véritable compréhension, ces systèmes permettent aux organisations d'automatiser les workflows complexes de traitement des documents, d'extraire des insights actionnables et de prendre des décisions basées sur les données avec une rapidité et une précision sans précédent. Alors que la technologie continue d'évoluer, les entreprises qui adoptent l'intelligence documentaire gagneront des avantages concurrentiels significatifs grâce à une efficacité améliorée, des coûts réduits et des capacités de prise de décision renforcées dans tous les domaines opérationnels.
Questions fréquemment posées
Qu'est-ce que l'intelligence documentaire et en quoi diffère-t-elle de l'OCR de base ?
L'intelligence documentaire va au-delà de l'OCR simple en utilisant des technologies d'IA comme le traitement du langage naturel et l'apprentissage automatique pour comprendre le contenu des documents, extraire des points de données spécifiques, identifier des relations et automatiser la prise de décision basée sur une analyse documentaire complète.
Comment les modèles GPT améliorent-ils les capacités d'intelligence documentaire ?
Les modèles GPT apportent une compréhension quasi humaine à l'intelligence documentaire en comprenant le contexte, les nuances et la terminologie spécialisée. Ils peuvent identifier des relations implicites, résumer des documents complexes et s'adapter à divers styles d'écriture qui défient les méthodes de traitement traditionnelles.
Quelles étapes les organisations doivent-elles suivre lors de la mise en œuvre de l'intelligence documentaire ?
La mise en œuvre réussie commence par la définition des objectifs commerciaux, la sélection de la technologie appropriée, la préparation des données, la mise en œuvre progressive de l'automatisation, l'intégration avec les systèmes commerciaux, l'établissement de protocoles de surveillance et la planification de l'évolution pour assurer le succès à long terme.
Quels sont les principaux avantages de l'intelligence documentaire IA pour les entreprises ?
L'intelligence documentaire IA réduit la saisie manuelle des données, améliore la précision, permet des décisions plus rapides, s'adapte efficacement, identifie des informations cachées, réduit les coûts opérationnels et améliore la conformité grâce au traitement automatisé et cohérent des documents.
Quelle est la précision du traitement de documents basé sur l'IA par rapport aux méthodes manuelles ?
Le traitement de documents basé sur l'IA peut atteindre des taux de précision élevés, dépassant souvent les méthodes manuelles, en particulier pour les tâches répétitives, mais il nécessite une formation appropriée, des données de qualité et un affinement continu pour minimiser les erreurs et s'adapter aux documents complexes.
Articles pertinents sur l'IA et les tendances technologiques
Restez à jour avec les dernières informations, outils et innovations qui façonnent l'avenir de l'IA et de la technologie.
Configuration de Grok 4 Fast sur Janitor AI : Guide Complet de Jeu de Rôle Sans Filtre
Guide étape par étape pour configurer Grok 4 Fast sur Janitor AI pour un jeu de rôle sans restriction, incluant la configuration de l'API, les paramètres de confidentialité et les conseils d'optimisation
Grok AI : Génération Illimitée de Vidéos Gratuite à partir de Texte et d'Images | Guide 2024
Grok AI propose une génération illimitée de vidéos gratuite à partir de texte et d'images, rendant la création de vidéos professionnelles accessible à tous sans compétences en montage.
Top 3 des extensions de codage IA gratuites pour VS Code 2025 - Boostez votre productivité
Découvrez les meilleures extensions d'agents de codage IA gratuites pour Visual Studio Code en 2025, y compris Gemini Code Assist, Tabnine et Cline, pour améliorer votre