Annotation
- Introduction
- Comprendre les modèles de langue de grande taille multilingues
- Que sont les modèles de langue de grande taille multilingues ?
- Contributions clés de la recherche sur les MLLM
- L'importance des modèles de langue multilingues
- Progrès récents et défis mondiaux
- Stratégies d'alignement des paramètres dans les MLLM
- Ressources de données pour l'entraînement des MLLM
- Méthodes d'alignement par ajustement des paramètres
- Directions et défis futurs de la recherche
- Avantages et inconvénients
- Conclusion
- Questions fréquemment posées
Modèles de Langage de Grande Taille Multilingues : Guide Complet des Ressources et Tendances Futures
Les modèles de langage de grande taille multilingues (MLLM) permettent la communication IA cross-linguale avec des ressources complètes, une taxonomie et des tendances futures pour le mondial
Introduction
Les modèles de langue de grande taille multilingues (MLLM) représentent une avancée transformatrice dans l'intelligence artificielle, permettant une communication transparente à travers des paysages linguistiques divers. Ces systèmes d'IA sophistiqués peuvent traiter, comprendre et générer du texte en plusieurs langues simultanément, éliminant les barrières linguistiques traditionnelles qui ont longtemps entravé la collaboration mondiale et l'échange d'informations. Alors que les organisations opèrent de plus en plus au-delà des frontières internationales, la demande de capacités d'IA multilingues robustes continue de croître de manière exponentielle.
Comprendre les modèles de langue de grande taille multilingues
Que sont les modèles de langue de grande taille multilingues ?
Les modèles de langue de grande taille multilingues (MLLM) constituent une étape évolutive significative au-delà des systèmes d'IA monolingues traditionnels. Contrairement à leurs homologues monolingues, les MLLM sont spécifiquement conçus pour gérer plusieurs langues dans une architecture unifiée, permettant une compréhension et une génération translinguistiques sans nécessiter des modèles séparés pour chaque langue. Cette approche intégrée permet une utilisation plus efficace des ressources et facilite de véritables capacités multilingues qui reflètent la flexibilité linguistique humaine.
L'innovation centrale des MLLM réside dans leur capacité à apprendre des représentations partagées entre les langues, capturant des motifs linguistiques et des relations sémantiques qui transcendent les frontières linguistiques individuelles. Cette compréhension translinguistique permet des applications allant des services de traduction en temps réel aux systèmes de support client multinational alimentés par des chatbots IA avancés et des outils d'IA conversationnelle.
Contributions clés de la recherche sur les MLLM
L'article de synthèse révolutionnaire « Multilingual Large Language Model : A Survey of Resources, Taxonomy and Frontiers » par Libo Qin et ses collègues représente une étape importante dans la recherche sur l'IA multilingue. Ce travail complet fournit le premier examen systématique du développement des MLLM, offrant aux chercheurs et aux praticiens un cadre unifié pour comprendre ce domaine en évolution rapide. La signification de l'article va au-delà des cercles académiques, fournissant des insights pratiques aux développeurs travaillant avec des API et SDK d'IA pour mettre en œuvre des capacités multilingues.
Parmi ses contributions les plus précieuses figure la collecte de ressources open-source étendues, incluant des ensembles de données organisés, des articles de recherche et des benchmarks de performance. Cette compilation de ressources comble une lacune critique dans le domaine, fournissant aux développeurs les outils nécessaires pour accélérer la mise en œuvre et l'évaluation des MLLM dans divers contextes linguistiques.
L'importance des modèles de langue multilingues
Progrès récents et défis mondiaux
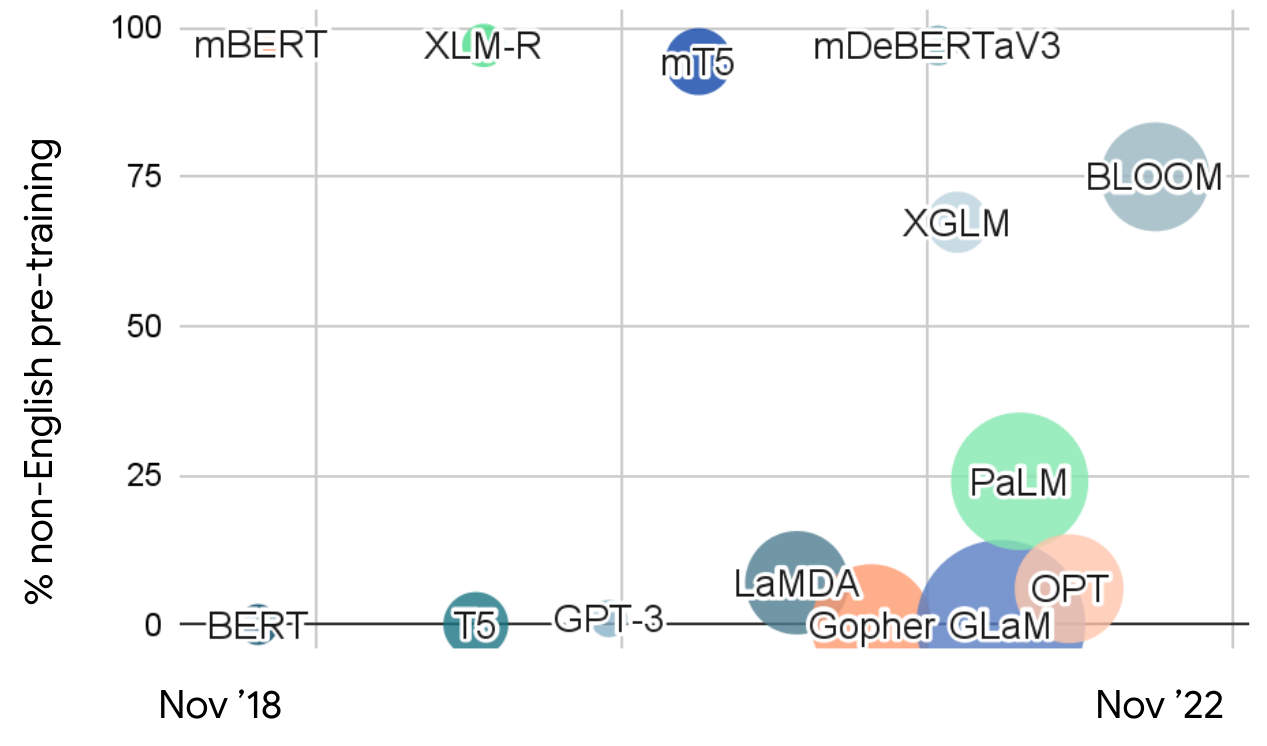
Les avancées récentes dans les modèles de langue de grande taille ont démontré des capacités remarquables en compréhension et génération du langage naturel. Cependant, l'accent prédominant sur l'entraînement en anglais a créé des limitations significatives pour le déploiement mondial. Avec plus de 7 000 langues parlées dans le monde et des demandes croissantes de mondialisation, le besoin de systèmes d'IA véritablement multilingues n'a jamais été aussi urgent. Cet écart est particulièrement prononcé dans les scénarios de langues à faibles ressources, où des données d'entraînement limitées et des ressources computationnelles présentent des défis substantiels.
Le biais centré sur l'anglais dans la plupart des LLM actuels crée des disparités dans l'accessibilité et la performance de l'IA à travers différentes communautés linguistiques. Les MLLM abordent ce déséquilibre en fournissant un accès plus équitable à la technologie linguistique, permettant aux organisations de déployer des capacités d'IA cohérentes à travers les marchés mondiaux via des plateformes d'automatisation IA et des systèmes de service multilingues.
Stratégies d'alignement des paramètres dans les MLLM
L'alignement des paramètres représente un défi technique fondamental dans le développement des MLLM, déterminant l'efficacité avec laquelle les modèles peuvent transférer des connaissances et des capacités entre les langues. Les deux méthodologies d'alignement principales – les approches d'ajustement des paramètres et de paramètres gelés – offrent des avantages et des compromis distincts pour différents scénarios de déploiement.
L'alignement par ajustement des paramètres implique d'ajuster activement les paramètres du modèle pendant l'entraînement pour optimiser les performances translinguistiques. Cette méthode donne généralement des résultats supérieurs mais nécessite des ressources computationnelles substantielles et un réglage minutieux pour éviter le surapprentissage ou l'interférence linguistique. En revanche, l'alignement par paramètres gelés exploite les capacités existantes du modèle grâce à des techniques de prompting stratégiques, offrant une plus grande efficacité et un déploiement plus rapide pour les organisations utilisant des agents et assistants IA.
Ressources de données pour l'entraînement des MLLM
L'efficacité des modèles multilingues dépend de manière critique de la qualité et de la diversité des données d'entraînement à travers différentes étapes linguistiques. Les données de pré-entraînement provenant de modèles comme GPT-3, mT5 et ERNIE 3.0 fournissent la compréhension linguistique fondamentale, tandis que les données de réglage fin provenant de ressources telles que Flan-PaLM et BLOOMZ permettent une optimisation spécifique aux tâches. L'apprentissage par renforcement à partir de retours humains (RLHF) affine davantage le comportement du modèle basé sur les préférences humaines, créant des interactions multilingues plus naturelles et contextuellement appropriées.
Chaque catégorie de données sert des objectifs distincts dans le pipeline de développement du modèle, avec le pré-entraînement multilingue établissant des capacités linguistiques larges et le réglage fin supervisé spécialisant les modèles pour des applications spécifiques. La curation et l'équilibrage minutieux de ces ensembles de données à travers les langues sont essentiels pour atteindre des performances translinguistiques robustes, en particulier pour les développeurs travaillant avec des services d'hébergement de modèles IA.
Méthodes d'alignement par ajustement des paramètres
L'alignement par ajustement des paramètres utilise une approche systématique et multi-étapes pour optimiser les performances des MLLM à travers les langues. Le processus commence par l'alignement de pré-entraînement, où les modèles apprennent des motifs linguistiques fondamentaux à partir d'ensembles de données multilingues divers. Cette étape fondamentale établit les capacités translinguistiques de base du modèle et les représentations partagées.
L'alignement par réglage fin supervisé affine ensuite ces capacités pour des tâches et applications spécifiques, incorporant des données formatées en instructions pour améliorer les performances sur des cas d'utilisation ciblés. L'alignement par apprentissage par renforcement à partir de retours humains améliore davantage le comportement du modèle en incorporant les préférences humaines et les considérations de sécurité. Enfin, l'alignement par réglage fin en aval adapte les modèles pour des scénarios de déploiement spécifiques, avec des techniques paramétriquement efficaces comme LoRA (Low-Rank Adaptation) optimisant l'utilisation des ressources.
Directions et défis futurs de la recherche
L'évolution continue des MLLM fait face à plusieurs défis de recherche critiques qui nécessitent une attention ciblée. La détection et l'atténuation des hallucinations multilingues représentent un domaine particulièrement urgent, car les modèles doivent maintenir une précision et une fiabilité à travers divers contextes linguistiques. L'édition des connaissances présente un autre défi significatif, nécessitant des méthodes pour mettre à jour et corriger continuellement les informations dans toutes les langues prises en charge tout en maintenant la cohérence.
Les considérations de sécurité et d'équité vont au-delà des performances techniques pour englober un déploiement éthique à travers les contextes mondiaux. Établir des benchmarks de sécurité complets, développer des mécanismes efficaces de filtrage du contenu non sécurisé et assurer des performances équitables à travers les langues à faibles ressources sont essentiels pour un développement responsable des MLLM. Ces efforts s'alignent avec des initiatives plus larges dans la technologie d'apprentissage des langues et les applications d'actualités multilingues qui servent des audiences mondiales diversifiées.
Avantages et inconvénients
Avantages
- Permet une communication transparente à travers plusieurs langues simultanément
- Facilite la compréhension interculturelle et la collaboration mondiale
- Soutient le développement d'applications et de services internationaux
- Améliore la précision dans les tâches de traitement du langage naturel multilingues
- Réduit le besoin de multiples systèmes d'IA monolingues
- Améliore l'accessibilité pour les populations non anglophones
- Soutient les marchés émergents et les communautés de langues à faibles ressources
Inconvénients
- Nécessite des ensembles de données multilingues étendus et des ressources computationnelles
- Difficile d'optimiser les performances dans toutes les langues prises en charge
- Risque de biais et d'inexactitudes dans les langues à faibles ressources
- Considérations complexes de sécurité et d'éthique à travers les cultures
- Coûts de développement et de maintenance plus élevés que les systèmes monolingues
Conclusion
Les modèles de langue de grande taille multilingues représentent une avancée charnière dans l'intelligence artificielle, offrant des capacités sans précédent pour la communication translinguistique et la collaboration mondiale. Alors que la recherche continue de s'attaquer aux limitations actuelles en matière d'atténuation des hallucinations, d'édition des connaissances et d'assurance de sécurité, les MLLM joueront un rôle de plus en plus vital dans le rapprochement des divisions linguistiques et l'activation de systèmes d'IA plus inclusifs. La taxonomie complète et la compilation de ressources fournies par les synthèses récentes établissent une base solide pour l'innovation future, guidant les chercheurs et les praticiens vers des solutions d'IA multilingues plus efficaces et équitables qui servent des communautés mondiales diversifiées.
Questions fréquemment posées
Quels sont les principaux défis dans le développement de modèles de langage de grande taille multilingues ?
Les défis clés incluent la gestion de plus de 7 000 langues avec une disponibilité de données variable, la satisfaction des demandes de mondialisation pour la communication cross-linguale et la résolution des scénarios à faibles ressources où les données et les ressources informatiques sont limitées, en particulier pour les langues sous-représentées.
Quels sont les principaux avantages de l'utilisation de modèles de langage de grande taille multilingues ?
Les MLLM permettent une communication transparente à travers plusieurs langues, facilitent la compréhension cross-culturelle, soutiennent le développement d'applications mondiales, améliorent la précision des tâches TAL multilingues et réduisent le besoin de maintenir des systèmes d'IA séparés pour une seule langue.
Quels domaines de recherche futurs sont importants pour le développement des MLLM ?
Les domaines de recherche critiques incluent la résolution des problèmes d'hallucination multilingue, l'amélioration des capacités d'édition des connaissances à travers les langues, l'établissement de repères de sécurité complets, la garantie de l'équité dans les langues à faibles ressources et le développement de stratégies d'alignement plus efficaces.
Quelles sont les principales stratégies d'alignement des paramètres dans les MLLM ?
Les MLLM utilisent principalement des stratégies d'alignement par réglage des paramètres et paramètres gelés. Le réglage des paramètres implique l'ajustement des paramètres du modèle pour l'optimisation cross-linguale, tandis que les paramètres gelés exploitent les capacités existantes via l'invite pour une plus grande efficacité.
Comment les MLLM impactent-ils l'accessibilité et l'équité mondiales de l'IA ?
Les MLLM améliorent l'accessibilité mondiale de l'IA en fournissant une technologie linguistique équitable à travers diverses communautés, en réduisant les biais centrés sur l'anglais et en soutenant les langues à faibles ressources, favorisant ainsi l'équité dans le déploiement de l'IA dans le monde entier.
Articles pertinents sur l'IA et les tendances technologiques
Restez à jour avec les dernières informations, outils et innovations qui façonnent l'avenir de l'IA et de la technologie.
Grok AI : Génération Illimitée de Vidéos Gratuite à partir de Texte et d'Images | Guide 2024
Grok AI propose une génération illimitée de vidéos gratuite à partir de texte et d'images, rendant la création de vidéos professionnelles accessible à tous sans compétences en montage.
Configuration de Grok 4 Fast sur Janitor AI : Guide Complet de Jeu de Rôle Sans Filtre
Guide étape par étape pour configurer Grok 4 Fast sur Janitor AI pour un jeu de rôle sans restriction, incluant la configuration de l'API, les paramètres de confidentialité et les conseils d'optimisation
Top 3 des extensions de codage IA gratuites pour VS Code 2025 - Boostez votre productivité
Découvrez les meilleures extensions d'agents de codage IA gratuites pour Visual Studio Code en 2025, y compris Gemini Code Assist, Tabnine et Cline, pour améliorer votre