Annotation
- Introduction
- Comprendre les services de transcription audio
- Composants de l'infrastructure de base
- Interface du site web et expérience utilisateur
- Architecture de production et flux de travail
- Structure du codebase et dépôt GitHub
- Défis de développement dans le monde réel
- Conteneurisation et améliorations futures
- Conception de la base de données et suivi des travaux
- Avantages et inconvénients
- Conclusion
- Questions fréquemment posées
Construire un Service de Transcription Audio : Guide Kubernetes, RabbitMQ
Apprenez à construire un service de transcription audio évolutif avec Kubernetes et RabbitMQ. Ce guide couvre l'architecture, le flux de travail et la mise en œuvre

Introduction
La construction d'un service de transcription audio nécessite une planification minutieuse de l'infrastructure, des flux de traitement et de l'expérience utilisateur. Ce guide complet vous accompagne dans la création de Phonic Tonic – un prototype fonctionnel démontrant comment convertir la parole en texte à grande échelle. Nous explorerons la pile technique complète, de l'orchestration de conteneurs à la mise en file d'attente des messages, en fournissant des insights pratiques pour les développeurs construisant des services similaires.
Comprendre les services de transcription audio
La conversion audio en texte est devenue essentielle dans de multiples industries, y compris la production médiatique, la recherche académique, la documentation juridique et les communications d'entreprise. Les services de transcription modernes exploitent des algorithmes avancés de reconnaissance vocale pour fournir des sorties textuelles précises à partir de divers formats audio. La demande croissante provient des exigences améliorées d'accessibilité, de la recherche de contenu améliorée et des capacités d'analyse de données efficaces. Pour les développeurs, la construction de tels services présente des défis uniques autour de l'évolutivité, de la précision et de l'optimisation des coûts.
Phonic Tonic sert de prototype éducatif qui démontre les défis de mise en œuvre réels plutôt que de présenter un code d'entreprise poli. Cette approche fournit des insights précieux sur les aspects pratiques du développement, y compris les décisions d'infrastructure, la conception des flux de travail et les considérations opérationnelles que de nombreux tutoriels négligent.
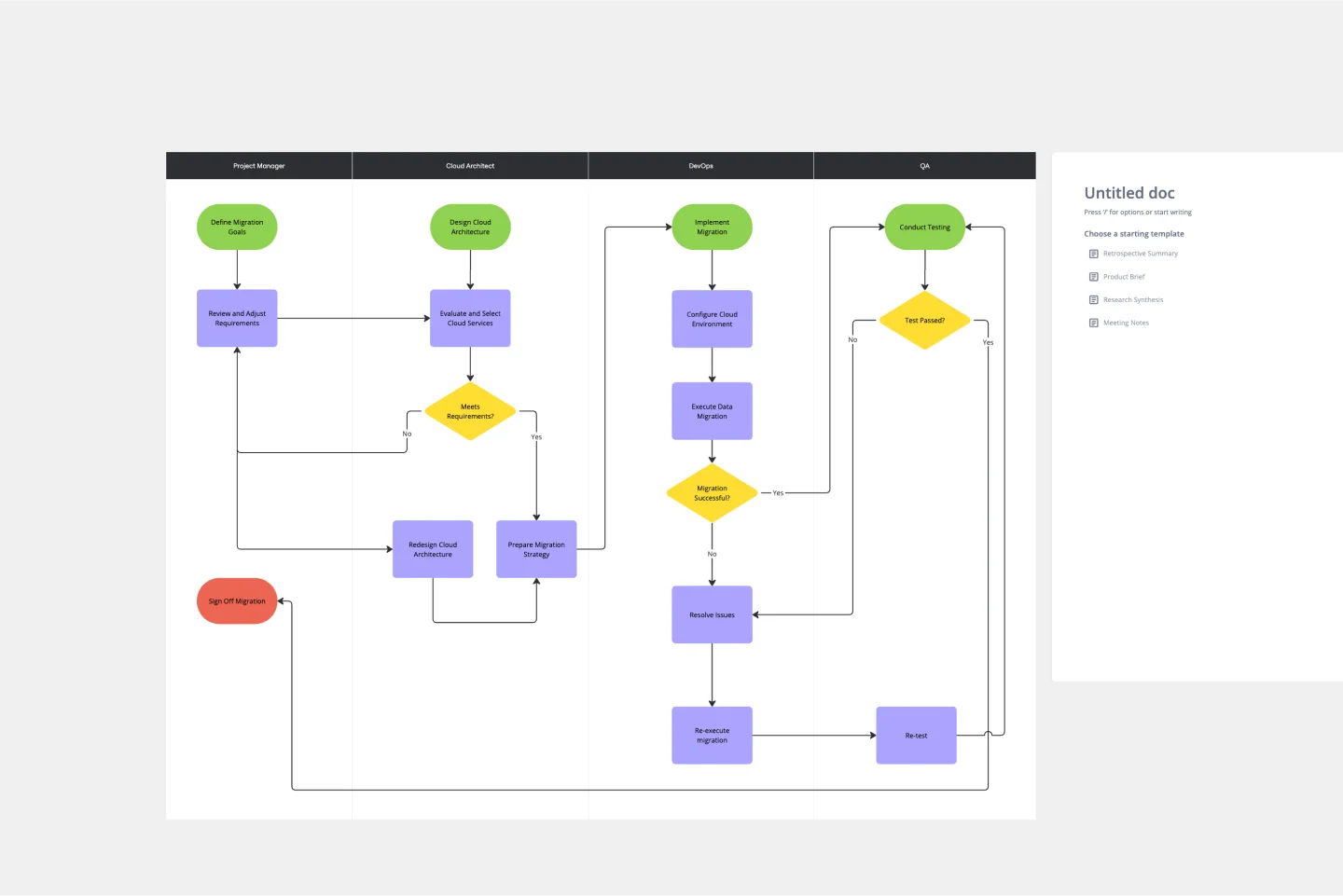
Composants de l'infrastructure de base
Le fondement de tout service de transcription fiable réside dans son architecture d'infrastructure. Phonic Tonic adopte une approche microservices utilisant plusieurs technologies clés qui fonctionnent ensemble de manière transparente. Kubernetes gère l'orchestration des conteneurs, garantissant que les différents composants peuvent évoluer indépendamment en fonction des demandes de charge de travail. Ceci est particulièrement important pour gérer les volumes variables de demandes de transcription tout au long de la journée.
La mise en file d'attente des messages avec RabbitMQ permet un traitement asynchrone, empêchant la surcharge du système pendant les périodes de pointe. Lorsque les utilisateurs téléchargent plusieurs fichiers audio volumineux simultanément, la file d'attente gère la distribution de la charge de travail entre les workers disponibles. Les solutions de stockage cloud comme Google Cloud Storage fournissent un stockage de fichiers durable et évolutif pour les fichiers audio originaux et les transcriptions générées, tandis que les bases de données MySQL suivent l'état des travaux et les informations utilisateur tout au long du pipeline de traitement.
Interface du site web et expérience utilisateur
Le composant orienté utilisateur de Phonic Tonic se concentre sur la simplicité et la fonctionnalité. Les utilisateurs interagissent avec une interface web épurée où ils peuvent télécharger des fichiers audio dans des formats courants comme MP3, WAV et M4A. Le système inclut une validation complète des fichiers pour s'assurer que le contenu téléchargé répond aux exigences de traitement avant d'entrer dans la file d'attente de transcription. La collecte d'e-mails permet la livraison de notifications une fois la transcription terminée, créant une expérience utilisateur fluide sans nécessiter la création de compte.
En arrière-plan, le site web gère le traitement initial des fichiers et coordonne avec les services backend via des API bien définies. Cette séparation des préoccupations permet au développement frontend et backend de progresser indépendamment tout en maintenant la fiabilité du système. La conception de l'interface privilégie la clarté et la facilité d'utilisation, reconnaissant que de nombreux utilisateurs peuvent ne pas avoir de formation technique mais nécessitent toujours des services de transcription précis.
Architecture de production et flux de travail
Le flux de travail de transcription suit une séquence soigneusement orchestrée du téléchargement du fichier à la livraison du texte. Lorsqu'un utilisateur soumet un fichier audio, le système valide d'abord le format et le stocke dans le stockage cloud. Un enregistrement de base de données crée une entrée de travail avec un identifiant unique et les informations de contact de l'utilisateur. Le système place ensuite une demande de transcription dans la file d'attente de messages, où les workers disponibles peuvent réclamer des tâches en fonction de la capacité actuelle.
Cette approche distribuée évite les points de défaillance uniques et permet une mise à l'échelle horizontale pendant les périodes de forte demande. L'architecture sépare le transcodage (conversion de format) de la reconnaissance vocale réelle, permettant une optimisation spécialisée pour chaque tâche. Les transcriptions terminées déclenchent des notifications par e-mail aux utilisateurs avec des liens de téléchargement, tandis que le système maintient des pistes d'audit pour le dépannage et les analyses.
Structure du codebase et dépôt GitHub
Le codebase de Phonic Tonic, disponible publiquement sur GitHub, démontre des modèles de mise en œuvre pratiques pour des projets similaires. Le dépôt contient des configurations Docker pour le déploiement conteneurisé, des fichiers YAML Kubernetes pour l'orchestration et le code source pour tous les composants majeurs. Le service web gère les interactions utilisateur et le traitement initial, tandis que des workers spécialisés gèrent des tâches spécifiques comme le transcodage audio, la reconnaissance vocale et les notifications par e-mail.
Chaque composant suit des principes de conception modulaire, rendant le système plus facile à maintenir et à étendre. Le worker de transcription s'intègre avec les API de reconnaissance vocale cloud, gérant l'authentification, le formatage des demandes et le traitement des réponses. Le code inclut une gestion complète des erreurs pour des scénarios courants comme les timeouts réseau, les formats audio invalides et les limitations de quota d'API – des considérations essentielles pour la préparation à la production.
Défis de développement dans le monde réel
Construire des services de transcription prêts pour la production implique de relever de nombreux défis pratiques au-delà de la fonctionnalité de base. Phonic Tonic montre intentionnellement des compromis de démarrage courants, y compris des informations d'identification codées en dur qui devraient utiliser des variables d'environnement ou des secrets Kubernetes dans les environnements de production. Le prototype manque de systèmes complets de surveillance et d'alerte, qui seraient essentiels pour identifier les problèmes de performance ou les interruptions de service en déploiement réel.
Les considérations de sécurité vont au-delà de la gestion des identifiants pour inclure la validation des entrées, les contrôles d'accès et le chiffrement des données. La nature éducative de ce projet signifie que ces aspects sont simplifiés, mais les systèmes de production nécessiteraient des revues de sécurité rigoureuses et la conformité aux réglementations de protection des données. L'optimisation des performances représente un autre domaine d'amélioration, particulièrement autour de la gestion des fichiers audio volumineux et de la minimisation de la latence de transcription.
Conteneurisation et améliorations futures
La stratégie de conteneurisation permet un déploiement cohérent à travers différents environnements tout en simplifiant la gestion des dépendances. Les améliorations futures se concentreraient sur l'excellence opérationnelle grâce à une journalisation complète utilisant des implémentations de pile ELK et une surveillance des métriques avec Prometheus et Grafana. Ces outils fournissent une visibilité sur la performance du système et aident à identifier les goulots d'étranglement avant qu'ils n'affectent les utilisateurs.
Les mécanismes d'alerte notifieraient les administrateurs des problèmes critiques comme les retards de file d'attente, les échecs de workers ou les limites de capacité de stockage. Les tests de charge valideraient le comportement du système sous les charges de pointe attendues, assurant une performance fiable pendant les pics d'utilisation. Ces améliorations représentent l'évolution d'un prototype fonctionnel vers un service prêt pour la production capable de gérer le trafic utilisateur réel.
Conception de la base de données et suivi des travaux
Le schéma de base de données pour Phonic Tonic met l'accent sur la simplicité et l'efficacité pour le suivi des travaux. Deux tables principales gèrent le flux de travail central : la table Jobs stocke les informations de haut niveau incluant les adresses e-mail des utilisateurs et les identifiants uniques, tandis que la table Tasks suit les étapes de traitement individuelles avec des mises à jour de statut, des métadonnées de fichiers et les résultats de transcription finaux. Cette séparation permet une gestion flexible des pipelines de traitement complexes tout en maintenant l'intégrité des données.
La conception prend en charge les pistes d'audit et le dépannage en préservant les informations historiques des travaux et les délais de traitement. Les améliorations futures pourraient inclure des tables supplémentaires pour la gestion des utilisateurs, les informations de facturation et les données d'analyse, mais l'implémentation actuelle se concentre sur les exigences essentielles pour un produit minimum viable.
Avantages et inconvénients
Avantages
- Architecture évolutive utilisant l'orchestration de conteneurs Kubernetes
- Le traitement asynchrone empêche la surcharge du système pendant les pics
- Conception modulaire permet un développement indépendant des composants
- Le stockage cloud fournit une gestion de fichiers durable et économique
- Le codebase open source facilite l'apprentissage et la personnalisation
- Gestion complète des erreurs pour les scénarios d'échec courants
- Interface utilisateur simple réduit les barrières à l'adoption
Inconvénients
- Les identifiants codés en dur posent des risques de sécurité significatifs
- Manque de surveillance et d'alerte pour les environnements de production
- Données de test de charge limitées pour la validation des performances
- Journalisation insuffisante pour un dépannage efficace
- Authentification de base sans support multi-utilisateur
Conclusion
Construire un service de transcription audio comme Phonic Tonic démontre l'intersection des pratiques de développement modernes et des exigences commerciales pratiques. Bien que le prototype montre une implémentation fonctionnelle, le déploiement en production nécessiterait de traiter les considérations de sécurité, de surveillance et d'évolutivité. L'architecture modulaire fournit une base solide pour l'extension, qu'il s'agisse d'ajouter le support de langues supplémentaires, de mettre en œuvre la transcription en temps réel ou de s'intégrer avec des systèmes de gestion de contenu. Pour les développeurs entreprenant des projets similaires, ce guide offre à la fois des modèles techniques et des insights précieux sur les réalités de l'amener des services de transcription du concept à l'état opérationnel.
Questions fréquemment posées
Quelles technologies alimentent le service de transcription Phonic Tonic ?
Phonic Tonic utilise Kubernetes pour l'orchestration de conteneurs, RabbitMQ pour la file d'attente de messages, Google Cloud Storage pour la gestion des fichiers et MySQL pour le suivi des travaux, créant une architecture de microservices évolutive.
Le code de Phonic Tonic est-il prêt pour la production ?
Non, c'est un prototype éducatif nécessitant des améliorations de sécurité, des systèmes de surveillance et des tests de charge avant le déploiement en production, mais fournissant une excellente base d'apprentissage.
Comment la file d'attente de messages améliore-t-elle les services de transcription ?
RabbitMQ permet un traitement asynchrone, empêchant la surcharge du système pendant les pics d'utilisation en répartissant les charges de travail entre les travailleurs disponibles et en assurant la persistance des travaux jusqu'à leur achèvement.
Quelles sont les principales considérations de sécurité pour les services de transcription ?
Les mesures de sécurité essentielles incluent l'utilisation de variables d'environnement pour les identifiants, la mise en œuvre de contrôles d'accès appropriés, le chiffrement des données sensibles et la réalisation d'audits de sécurité réguliers.
Quels formats audio sont pris en charge par Phonic Tonic ?
Phonic Tonic prend en charge les formats audio courants, y compris MP3, WAV et M4A, avec une validation intégrée pour garantir la compatibilité des fichiers avant le traitement.
Articles pertinents sur l'IA et les tendances technologiques
Restez à jour avec les dernières informations, outils et innovations qui façonnent l'avenir de l'IA et de la technologie.
Grok AI : Génération Illimitée de Vidéos Gratuite à partir de Texte et d'Images | Guide 2024
Grok AI propose une génération illimitée de vidéos gratuite à partir de texte et d'images, rendant la création de vidéos professionnelles accessible à tous sans compétences en montage.
Configuration de Grok 4 Fast sur Janitor AI : Guide Complet de Jeu de Rôle Sans Filtre
Guide étape par étape pour configurer Grok 4 Fast sur Janitor AI pour un jeu de rôle sans restriction, incluant la configuration de l'API, les paramètres de confidentialité et les conseils d'optimisation
Top 3 des extensions de codage IA gratuites pour VS Code 2025 - Boostez votre productivité
Découvrez les meilleures extensions d'agents de codage IA gratuites pour Visual Studio Code en 2025, y compris Gemini Code Assist, Tabnine et Cline, pour améliorer votre