Annotation
- Introduction
- Pourquoi choisir l'open source pour l'IA ?
- Présentation de Docling : Un héros open source
- Comparaison de Docling aux alternatives closed source
- Techniques essentielles : Extraction, Analyse, Segmentation, Incorporation et Récupération
- Exécution de l'exemple Docling
- Avantages et Inconvénients
- Conclusion
- Questions fréquemment posées
Docling Analyse de Documents Open Source : Guide Complet d'Implémentation IA
Guide d'analyse de documents open source Docling pour l'IA : implémentez localement le traitement PDF, le découpage, l'incorporation et les pipelines RAG.

Introduction
Dans l'environnement commercial axé sur les données d'aujourd'hui, les agents IA sont devenus des outils essentiels pour le support client et l'analyse de données. La base des systèmes IA efficaces réside dans leur capacité à accéder et à comprendre les informations spécifiques à l'entreprise, qui se trouvent souvent dans des documents, des PDF et des sites web. Bien qu'il existe de nombreux outils commerciaux pour l'analyse de documents, beaucoup entraînent des coûts d'API et des limitations de code fermé. Docling émerge comme une alternative open-source puissante qui offre un contrôle complet sur votre pipeline de traitement de documents tout en préservant la confidentialité des données et la flexibilité de personnalisation.
Pourquoi choisir l'open source pour l'IA ?
Lors du développement d'agents IA, l'accès aux données propriétaires est crucial pour obtenir des résultats significatifs. Ces données incluent généralement des documents internes, des rapports PDF et des sites web d'entreprise qui contiennent des connaissances spécifiques sur votre organisation. Les solutions d'analyse traditionnelles nécessitent souvent d'envoyer des données sensibles à des plateformes tierces, créant des vulnérabilités potentielles en matière de sécurité et des dépenses de licence continues. Les alternatives open source comme Docling éliminent ces préoccupations en permettant un traitement local au sein de votre propre infrastructure.
Les avantages de l'analyse de documents open source vont au-delà des économies de coûts. Vous bénéficiez d'une transparence complète sur la façon dont vos données sont traitées, de la capacité de personnaliser la logique d'analyse pour des structures de documents uniques, et de la liberté vis-à-vis de l'enfermement propriétaire. Cette approche s'aligne particulièrement bien avec les exigences des entreprises en matière de gouvernance des données et de conformité. Pour les organisations explorant des solutions d'extraction de documents IA, l'open source offre des avantages à la fois techniques et stratégiques.

Les outils open source offrent une valeur significative grâce à plusieurs avantages clés : un contrôle complet sur les pipelines de traitement des données, des possibilités de personnalisation illimitées, des opérations transparentes qui améliorent la sécurité, un support communautaire actif, et des réductions de coûts substantielles par rapport aux alternatives propriétaires. Ces avantages rendent l'open source particulièrement attrayant pour les organisations construisant des plateformes d'automatisation IA complètes qui nécessitent des capacités de traitement de documents fiables.
Présentation de Docling : Un héros open source
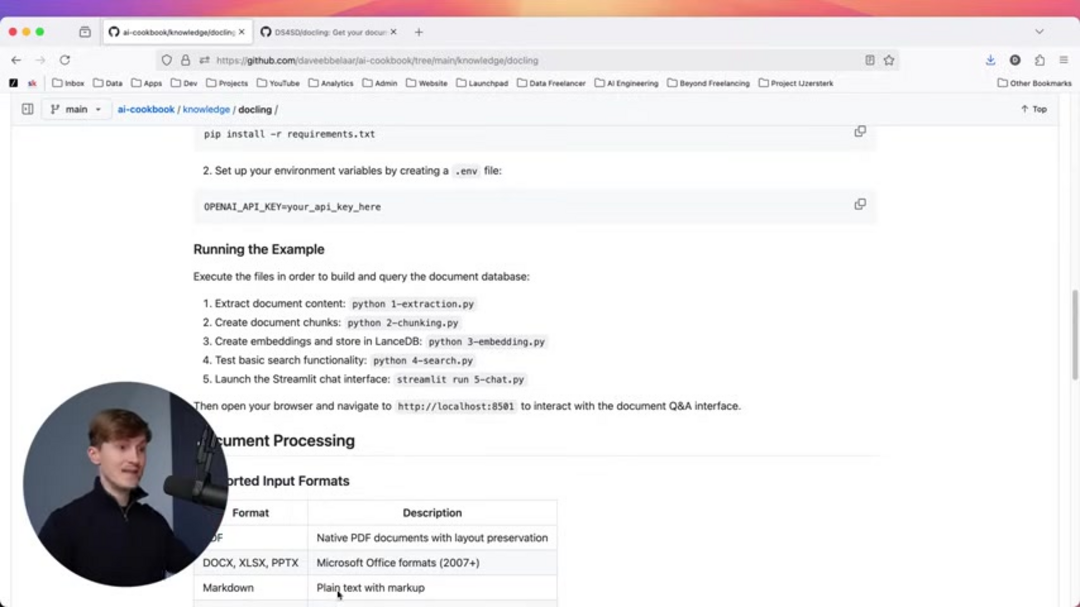
Docling représente une bibliothèque de traitement de documents open source sophistiquée qui transforme divers formats de documents en données structurées unifiées. Construite avec des capacités IA avancées, elle excelle dans l'analyse de mise en page et la reconnaissance de structure de tableaux tout en maintenant une efficacité de traitement local. La bibliothèque supporte une vaste gamme de formats incluant les PDF, les fichiers DOCX, les feuilles de calcul XLSX, les présentations PPTX, les documents Markdown, les pages HTML, et divers formats d'image.

Ce qui distingue Docling, ce sont ses options de sortie flexibles, permettant aux développeurs d'exporter le contenu traité vers des formats HTML, Markdown, JSON ou texte brut. Cette versatilité le rend idéal pour l'intégration dans des workflows et applications existantes. Le système fonctionne efficacement sur du matériel standard et présente une architecture extensible qui permet aux développeurs d'incorporer des modèles personnalisés ou de modifier les pipelines de traitement pour des besoins spécifiques. Cela rend Docling particulièrement précieux pour les systèmes de recherche de documents d'entreprise, les implémentations de récupération de passages, et les projets d'extraction de connaissances.
Pour les développeurs travaillant avec des API et SDK IA, Docling fournit une base robuste pour construire des pipelines de Génération Augmentée par Récupération (RAG). Ses capacités avancées de segmentation et ses optimisations de traitement assurent que les applications GenAI reçoivent des entrées de connaissances bien structurées, améliorant significativement la qualité et la précision des réponses dans les systèmes de questions-réponses basés sur des documents.
Comparaison de Docling aux alternatives closed source
Lors de l'évaluation des solutions d'analyse de documents, il est essentiel de comprendre comment Docling se compare aux alternatives commerciales comme Microsoft Azure AI Document Intelligence, Amazon Textract, et divers services propriétaires. La distinction fondamentale réside dans la nature open-source de Docling par rapport à l'approche closed-source et dépendante des API des offres commerciales.
Les services commerciaux d'analyse de documents fonctionnent généralement sur des modèles de tarification basés sur l'utilisation, qui peuvent devenir coûteux à grande échelle. Chaque document traité engendre des coûts, et les opérations à volume élevé peuvent rapidement accumuler des dépenses significatives. De plus, ces services nécessitent d'envoyer des documents sensibles à des serveurs externes, soulevant des préoccupations de confidentialité des données et des problèmes potentiels de conformité pour les organisations manipulant des informations confidentielles.
Docling élimine ces préoccupations en permettant un traitement local complet sans dépendances externes. Vos données ne quittent jamais votre infrastructure, assurant une sécurité maximale et la conformité avec les réglementations de protection des données. Le modèle open-source offre également des opportunités de personnalisation illimitées – vous pouvez modifier la logique d'analyse, ajouter le support pour des types de documents spécialisés, ou intégrer des modèles IA personnalisés adaptés à vos besoins spécifiques. Ce niveau de flexibilité est typiquement indisponible dans les solutions commerciales d'éditeur PDF et d'analyse qui offrent des options de configuration limitées.
Techniques essentielles : Extraction, Analyse, Segmentation, Incorporation et Récupération
La construction d'un pipeline d'extraction de connaissances efficace implique plusieurs étapes interconnectées qui transforment les documents bruts en informations contextuelles et consultables. Chaque étape joue un rôle critique pour s'assurer que vos agents IA peuvent accéder et utiliser efficacement le contenu des documents.
Avant de commencer l'implémentation, assurez-vous d'avoir les prérequis nécessaires installés. Commencez par installer les packages requis en utilisant pip install -r requirements.txt, qui devrait inclure Docling et toute dépendance supplémentaire. Créez un fichier .env pour stocker les variables d'environnement, incluant votre clé API OpenAI pour la génération d'incorporations si vous utilisez des modèles externes.
La construction du pipeline suit ces étapes clés :
- Extraction : Commencez par extraire le contenu des documents source en utilisant le convertisseur de documents de Docling. Après l'installation via pip install docling, vous pouvez traiter les PDF, les URL, et divers formats de fichiers en contenu structuré lisible. Cette étape initiale gère la détection de format et l'extraction de contenu tout en préservant la structure du document.
- Analyse : La phase d'analyse identifie et catégorise les éléments du document incluant les paragraphes de texte, les listes, les tableaux, et les composants structurels. Docling convertit le contenu en format Markdown tout en maintenant les relations sémantiques entre les éléments, rendant le contenu plus facile à manipuler et à traiter dans les étapes suivantes.
- Segmentation : La segmentation de documents segmente logiquement le contenu pour un traitement optimal. Le segmenteur hybride de Docling ajuste automatiquement la taille des segments basée sur la structure du contenu, empêchant des fragments trop petits tout en divisant les grandes sections selon les paramètres d'ajustement du texte. Cela assure la préservation du contexte tout en maintenant des unités de traitement gérables.
- Incorporation : L'étape d'incorporation convertit les segments de texte traités en vecteurs numériques en utilisant des modèles d'incorporation. Vous pouvez utiliser divers modèles incluant les incorporations d'OpenAI ou des alternatives open-source, créant des représentations vectorielles qui capturent la signification sémantique pour des opérations de recherche de similarité efficaces.
- Récupération : L'étape finale implique de stocker les incorporations dans une base de données vectorielle comme LanceDB, permettant une recherche de similarité et une récupération de contexte efficaces. Cela permet aux agents et assistants IA de localiser rapidement les sections de documents pertinentes lorsqu'ils répondent à des questions ou fournissent des informations.
Exécution de l'exemple Docling
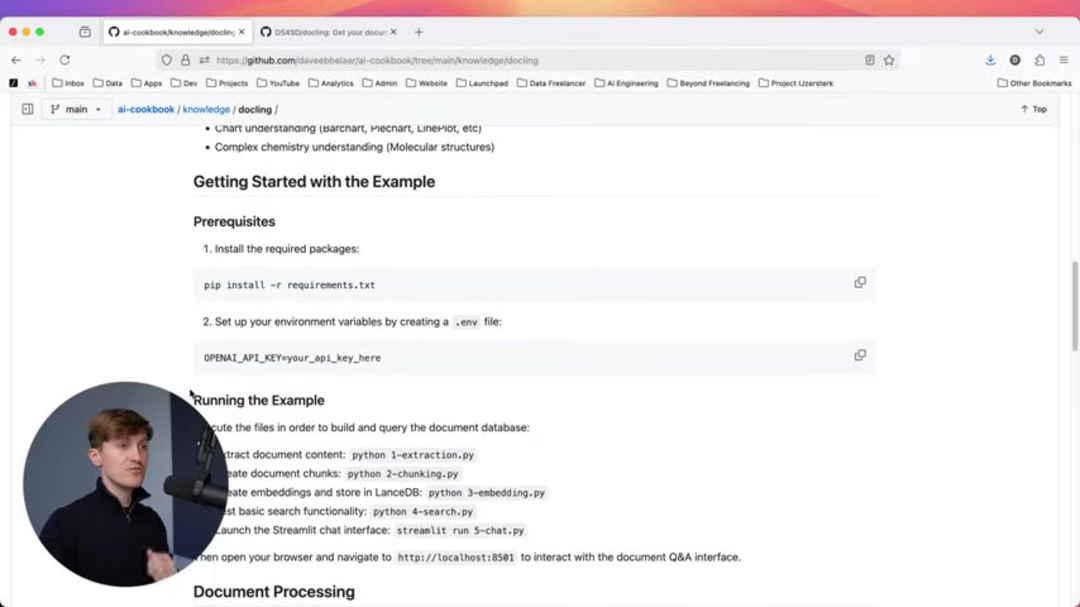
Pour démontrer une implémentation pratique, suivez ces étapes séquentielles pour construire et tester un pipeline complet de traitement de documents. Assurez-vous que chaque étape se termine avec succès avant de passer à la suivante, et maintenez une sécurité appropriée pour vos fichiers de configuration d'environnement.
- Exécutez python 1-extraction.py pour extraire le contenu du document de vos fichiers source ou URL, générant une sortie structurée prête pour un traitement ultérieur.
- Exécutez python 2-chunking.py pour créer des segments de documents de taille optimale en utilisant les algorithmes de segmentation intelligents de Docling, préparant le contenu pour la génération d'incorporations.
- Traitez python 3-embedding.py pour générer des incorporations et les stocker dans la base de données vectorielle LanceDB, créant l'index de recherche pour votre contenu documentaire.
- Testez la fonctionnalité de recherche de base avec python 4-search.py pour vérifier que votre pipeline fonctionne correctement et retourne des résultats pertinents pour des requêtes d'échantillon.
- Lancez l'interface de chat Streamlit interactive en utilisant streamlit run 5-chat.py, fournissant une manière conviviale d'interroger votre base de connaissances documentaire.
Après avoir complété ces étapes, ouvrez votre navigateur web et naviguez vers localhost:8501 pour accéder à l'interface Q&A de documents. Cela fournit une démonstration pratique de comment Docling permet une interaction intelligente avec les documents grâce à des capacités d'éditeur de documents et de recherche intégrées dans des interfaces conversationnelles.
Avantages et Inconvénients
Avantages
- Solution open-source complète avec licence MIT
- Le traitement local assure une confidentialité maximale des données
- Support étendu de formats incluant PDF et DOCX
- Analyse de mise en page avancée et reconnaissance de tableaux
- Formats de sortie flexibles pour l'intégration
- Pipeline d'analyse personnalisable pour des besoins uniques
- Support communautaire actif et documentation
Inconvénients
- Nécessite une expertise technique pour l'implémentation
- Intégration limitée des modèles de langage visuel
- Compréhension complexe des documents de chimie
- Limitations matérielles locales pour les grands volumes
Conclusion
Docling représente une avancée significative dans le traitement de documents open-source, fournissant aux organisations une alternative puissante aux services d'analyse commerciaux. Son support complet de formats, ses capacités IA avancées, et son architecture flexible le rendent idéal pour construire des systèmes d'extraction de connaissances sophistiqués. En permettant un traitement local et une personnalisation complète, Docling adresse des préoccupations critiques autour de la confidentialité des données, du contrôle des coûts, et de la flexibilité d'intégration. Que vous développiez des agents IA, construisiez des pipelines RAG, ou créiez des solutions de recherche d'entreprise, Docling offre les outils et capacités nécessaires pour transformer le contenu des documents en intelligence actionnable tout en maintenant un contrôle complet sur vos données et workflows de traitement.
Questions fréquemment posées
Quels formats de fichiers Docling prend-il en charge ?
Docling prend en charge de nombreux formats de documents, notamment PDF, DOCX, XLSX, PPTX, Markdown, HTML et divers formats d'image, le rendant polyvalent pour divers besoins de traitement de documents.
Docling est-il vraiment open source ?
Oui, Docling utilise la licence MIT, offrant un accès open source complet sans restrictions ni frais de licence pour un usage commercial ou personnel.
Comment Docling améliore-t-il les pipelines RAG ?
Docling optimise les pipelines RAG grâce à un découpage avancé, une analyse de mise en page et une reconnaissance de tableaux, fournissant aux applications GenAI des connaissances structurées et contextuelles issues des documents.
Docling peut-il traiter les documents localement ?
Oui, Docling fonctionne entièrement localement sur du matériel standard, garantissant la confidentialité des données et éliminant la dépendance aux API externes ou aux services cloud.
Quel matériel est recommandé pour Docling ?
Docling fonctionne sur du matériel standard, mais pour de grands volumes, recommandez des CPU multicœurs et une RAM suffisante ; le GPU peut accélérer certains modèles s'il est intégré.
Articles pertinents sur l'IA et les tendances technologiques
Restez à jour avec les dernières informations, outils et innovations qui façonnent l'avenir de l'IA et de la technologie.
Grok AI : Génération Illimitée de Vidéos Gratuite à partir de Texte et d'Images | Guide 2024
Grok AI propose une génération illimitée de vidéos gratuite à partir de texte et d'images, rendant la création de vidéos professionnelles accessible à tous sans compétences en montage.
Top 3 des extensions de codage IA gratuites pour VS Code 2025 - Boostez votre productivité
Découvrez les meilleures extensions d'agents de codage IA gratuites pour Visual Studio Code en 2025, y compris Gemini Code Assist, Tabnine et Cline, pour améliorer votre
Configuration de Grok 4 Fast sur Janitor AI : Guide Complet de Jeu de Rôle Sans Filtre
Guide étape par étape pour configurer Grok 4 Fast sur Janitor AI pour un jeu de rôle sans restriction, incluant la configuration de l'API, les paramètres de confidentialité et les conseils d'optimisation