Annotation
- 引言
- 理解零样本学习基础
- 潜在嵌入:技术基础
- TARS模型:高级零样本分类
- 提示工程以优化性能
- 开源解决方案与实施
- 实际业务应用
- 优缺点
- 结论
- 常见问题
零样本学习:无需标注训练数据的文本分类
零样本学习使AI能够使用语义嵌入和知识迁移对未见过的类别进行文本分类,无需标注数据

引言
在快速发展的自然语言处理领域,零样本学习代表了机器理解和分类文本方式的突破性转变。这种创新方法使AI模型无需大量标注训练数据集即可对文档、情感和主题进行分类——这一限制传统上制约了机器学习应用。通过利用语义理解和知识迁移,零样本学习为处理动态内容和不断变化的分类需求的组织开辟了新的可能性,涵盖各种AI聊天机器人和自动化平台。
理解零样本学习基础
零样本学习代表了从传统监督学习方法向范式的转变。虽然常规方法需要每个分类类别的大量标注示例,但零样本学习使模型能够将文本分类到训练中从未遇到过的类别中。这种能力源于模型理解语义关系和从相关领域迁移知识的能力。
核心机制涉及将文本输入和类别标签投影到一个共享语义空间中,通过相似性度量来测量它们的关系。这种方法模拟了人类推理——我们通常可以基于对相关概念的理解对新概念进行分类,而无需显式示例。
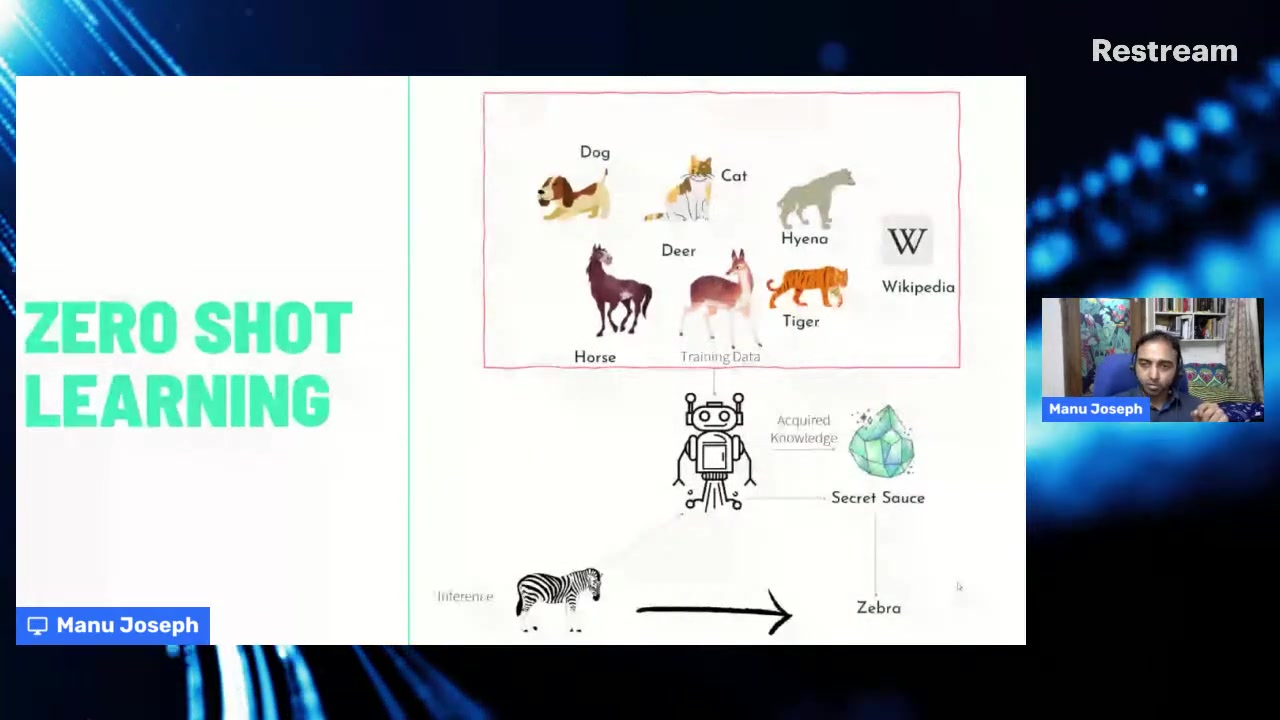
潜在嵌入:技术基础
潜在嵌入构成了有效零样本分类系统的技术支柱。这些嵌入创建了一个多维空间,文本内容和类别标签都可以用数字表示,从而实现精确的相似性计算。像Sentence-BERT(S-BERT)这样的高级模型擅长通过捕捉超越简单关键词匹配的细微语义含义来生成这些嵌入。
嵌入过程通常遵循以下步骤:
- 文本编码:输入文本通过基于Transformer的编码器处理,创建密集向量表示。
- 标签表示:使用相同模型架构对类别标签进行类似编码。
- 相似性评估:使用余弦相似度或其他度量计算文本和标签之间的对齐度。
- 分类决策:系统将文本分配给相似度得分最高的类别。
这种方法对于需要分类多样化内容类型而无需持续重新训练的AI写作工具非常有价值。
TARS模型:高级零样本分类
文本感知句子表示(TARS)模型代表了零样本学习能力的重大进步。这些专门架构建立在像BERT这样的基础模型之上,但结合了额外机制来处理无需特定任务训练的分类任务。TARS模型在适应新分类方案的同时保持稳健性能方面表现出灵活性。
TARS的优势在于其理解文本和潜在标签之间上下文关系的能力。这种细致的方法实现了更准确的分类,尤其适用于复杂任务。实施涉及将预训练模型应用于新领域,只需最小调整,非常适合快速部署。这与需要动态内容理解的现代对话AI工具非常契合。
提示工程以优化性能
有效的提示工程在最大化零样本学习性能中起着关键作用。由于模型依赖于标签表示,标签的表述方式会影响准确性。精心设计的提示为理解类别边界提供了上下文。
最佳实践包括使用描述性、明确的标签名称。对于情感分析,像“表达满意度的文本”和“表达批评的文本”这样的提示能产生更好的结果。高级技术使用多种提示变体和集成方法来提高可靠性,这对于性能一致性至关重要的AI API和SDK非常有价值。
开源解决方案与实施
零样本学习生态系统受益于强大的开源实现。像Hugging Face的Transformers这样的库为零样本任务提供了预训练模型,而像SetFit这样的框架以最小的计算需求提供高效能力。
这些解决方案包括预配置模型、标准化API、文档和更新。对于使用AI自动化平台的开发人员来说,这些降低了实施障碍,并为定制提供了坚实基础。
实际业务应用
零样本学习在传统分类不切实际的场景中提供价值。客户服务将支持工单分类到新问题中而无需重新训练。营销分析新产品的反馈,合规监控未知风险。
对于AI代理和助手,零样本能力通过理解训练领域外的用户请求实现自适应交互。它还通过基于语义相似性识别新的不当内容来辅助内容审核。
优缺点
优点
- 消除对大量标注训练数据集的需求
- 能够对完全新的、未见过的类别进行分类
- 促进快速适应不断变化的业务需求
- 减少数据准备时间及相关成本
- 支持相关领域间的知识迁移
缺点
- 在数据充足的情况下,可能比监督学习准确性低
- 性能高度依赖于嵌入质量和提示设计
- 可能难以处理高度专业化或技术性的领域类别
结论
零样本学习代表了使文本分类更易访问和高效的重要飞跃。通过减少对标注数据集的依赖,它为具有动态需求的组织开启了机器学习。虽然不完全取代监督学习,但它为灵活性和快速适应提供了强大替代方案,特别是在涉及文本编辑器和内容管理系统的应用中。
常见问题
用简单的话来说,什么是零样本学习?
零样本学习允许AI模型通过理解语义关系而不是依赖每个特定类别的标注示例,将文本分类到训练中从未见过的类别。
零样本学习与传统分类有何不同?
传统分类需要每个类别的大量标注数据,而零样本学习使用语义理解来对未见过的类别进行分类,无需特定的训练示例。
零样本学习的主要商业优势是什么?
主要优势包括降低数据标注成本、更快适应新类别、处理动态分类需求以及在标注数据稀缺时实现分类。
哪些行业从零样本文本分类中受益最多?
客户服务、内容审核、市场研究、合规监控以及任何类别不断变化或出现新主题且标注数据具有挑战性的领域。
零样本学习的局限性是什么?
局限性包括可能比监督学习准确率较低、依赖嵌入质量和提示设计,以及处理模糊或高度技术性内容的挑战。
相关AI和技术趋势文章
了解塑造AI和技术未来的最新见解、工具和创新。
Grok AI:从文本和图像免费无限生成视频 | 2024指南
Grok AI 提供从文本和图像免费无限生成视频,使每个人无需编辑技能即可进行专业视频创作。
Grok 4 Fast Janitor AI 设置:完整无过滤角色扮演指南
逐步指南:在 Janitor AI 上配置 Grok 4 Fast 进行无限制角色扮演,包括 API 设置、隐私设置和优化技巧
2025年VS Code三大免费AI编程扩展 - 提升生产力
探索2025年Visual Studio Code的最佳免费AI编程助手扩展,包括Gemini Code Assist、Tabnine和Cline,以提升您的