Annotation
- Introducción
- Comprensión de los Sistemas Modernos de Reconocimiento Facial
- El Desafío Técnico del Reconocimiento Facial Enmascarado
- Abordando el Sesgo en los Sistemas de Reconocimiento Facial
- Construyendo un Modelo de Reconocimiento Facial Enmascarado
- Aplicaciones en el Mundo Real y Consideraciones de Implementación
- Consideraciones Éticas y Despliegue Responsable
- Pros y Contras
- Conclusión
- Preguntas frecuentes
Guía de Reconocimiento Facial con Mascarillas: Construir Sistemas de IA que Funcionen con Coberturas Faciales
Guía completa sobre el desarrollo de sistemas de IA para un reconocimiento facial preciso con mascarillas, que cubre la implementación técnica, la mitigación de sesgos y

Introducción
En el panorama de seguridad en evolución actual, la tecnología de reconocimiento facial enfrenta desafíos sin precedentes con la adopción generalizada de cubiertas faciales. Esta guía integral explora cómo construir sistemas de IA robustos capaces de identificar con precisión a individuos incluso cuando llevan máscaras. Recorreremos pasos prácticos utilizando modelos preentrenados y conjuntos de datos accesibles, proporcionando tanto profundidad técnica como aplicabilidad en el mundo real para desarrolladores y profesionales de seguridad que trabajan con tecnologías de visión por computadora.
Comprensión de los Sistemas Modernos de Reconocimiento Facial
El reconocimiento facial representa una tecnología biométrica sofisticada que identifica o verifica individuos a partir de imágenes digitales o fotogramas de video. El proceso involucra múltiples etapas: detección de rostros, extracción de características y clasificación. Estos sistemas analizan patrones y características faciales únicos para crear firmas digitales que distinguen a una persona de otra. La tecnología se ha vuelto cada vez más prevalente en sistemas de seguridad, autenticación de dispositivos móviles y aplicaciones de control de acceso. La aparición de rostros enmascarados presenta obstáculos técnicos significativos, ya que los sistemas tradicionales dependen de la visibilidad facial completa para un rendimiento óptimo. Las soluciones modernas deben adaptarse para manejar oclusiones parciales mientras mantienen la precisión y confiabilidad en escenarios del mundo real.

El desafío fundamental radica en desarrollar algoritmos que puedan extraer características significativas de regiones faciales visibles limitadas. Los sistemas avanzados ahora incorporan técnicas de entrenamiento especializadas utilizando conjuntos de datos diversos que contienen rostros enmascarados y no enmascarados. Este enfoque permite a los modelos aprender representaciones robustas que permanecen efectivas incluso cuando porciones significativas del rostro están oscurecidas. Comprender estos principios básicos es esencial para cualquiera que implemente herramientas de visión por computadora en aplicaciones de seguridad o identificación.
El Desafío Técnico del Reconocimiento Facial Enmascarado
Los sistemas tradicionales de reconocimiento facial dependen en gran medida de la visibilidad completa de las características faciales para una identificación precisa. Las máscaras oscurecen regiones críticas, incluyendo la nariz, la boca y las mejillas inferiores, áreas que contienen características distintivas de identificación. Esta oclusión interrumpe los patrones de características que los algoritmos convencionales están entrenados para reconocer, lo que lleva a una posible degradación del rendimiento. Abordar este desafío requiere enfoques innovadores que reconstruyan las características faciales faltantes o se centren más intensamente en las áreas visibles restantes. Una estrategia efectiva implica entrenar modelos específicamente en conjuntos de datos que contengan rostros enmascarados, permitiéndoles aprender qué características visibles permanecen más discriminatorias. Métodos alternativos emplean modelos generativos que pueden inferir inteligentemente regiones ocluidas basándose en información contextual de áreas visibles. Mecanismos avanzados de atención permiten a los modelos priorizar dinámicamente las regiones faciales más informativas, minimizando el impacto de las áreas cubiertas. Superar con éxito los desafíos del reconocimiento facial enmascarado asegura la relevancia continua de esta tecnología en entornos donde las cubiertas faciales son comunes, desde entornos de atención médica hasta puntos de control de seguridad.
Abordando el Sesgo en los Sistemas de Reconocimiento Facial
El sesgo en el reconocimiento facial representa una preocupación ética y técnica crítica que puede llevar a resultados discriminatorios. La investigación ha demostrado que muchos sistemas exhiben una precisión reducida para ciertos grupos demográficos, incluyendo personas de color, mujeres y adultos mayores. Estas disparidades provienen de múltiples fuentes: datos de entrenamiento desequilibrados, elecciones de diseño algorítmico y metodologías de evaluación. Para construir sistemas más justos, los desarrolladores deberían implementar estrategias integrales de mitigación de sesgos. Utilizar datos de entrenamiento diversos y representativos que reflejen con precisión a las poblaciones objetivo es fundamental. Esto requiere una recolección intencional de datos de fuentes variadas a través de diferentes demografías. Además, emplear algoritmos conscientes de la equidad específicamente diseñados para reducir el sesgo mediante técnicas como re-ponderación de datos, regularización o entrenamiento adversarial puede mejorar significativamente la equidad. La evaluación regular utilizando métricas de equidad, incluyendo igualdad de oportunidades, probabilidades igualadas y paridad demográfica, proporciona medidas cuantitativas del rendimiento del sistema en diferentes grupos. El monitoreo y auditoría continuos aseguran que los sistemas mantengan la equidad a medida que encuentran nuevos datos y escenarios en entornos de producción.
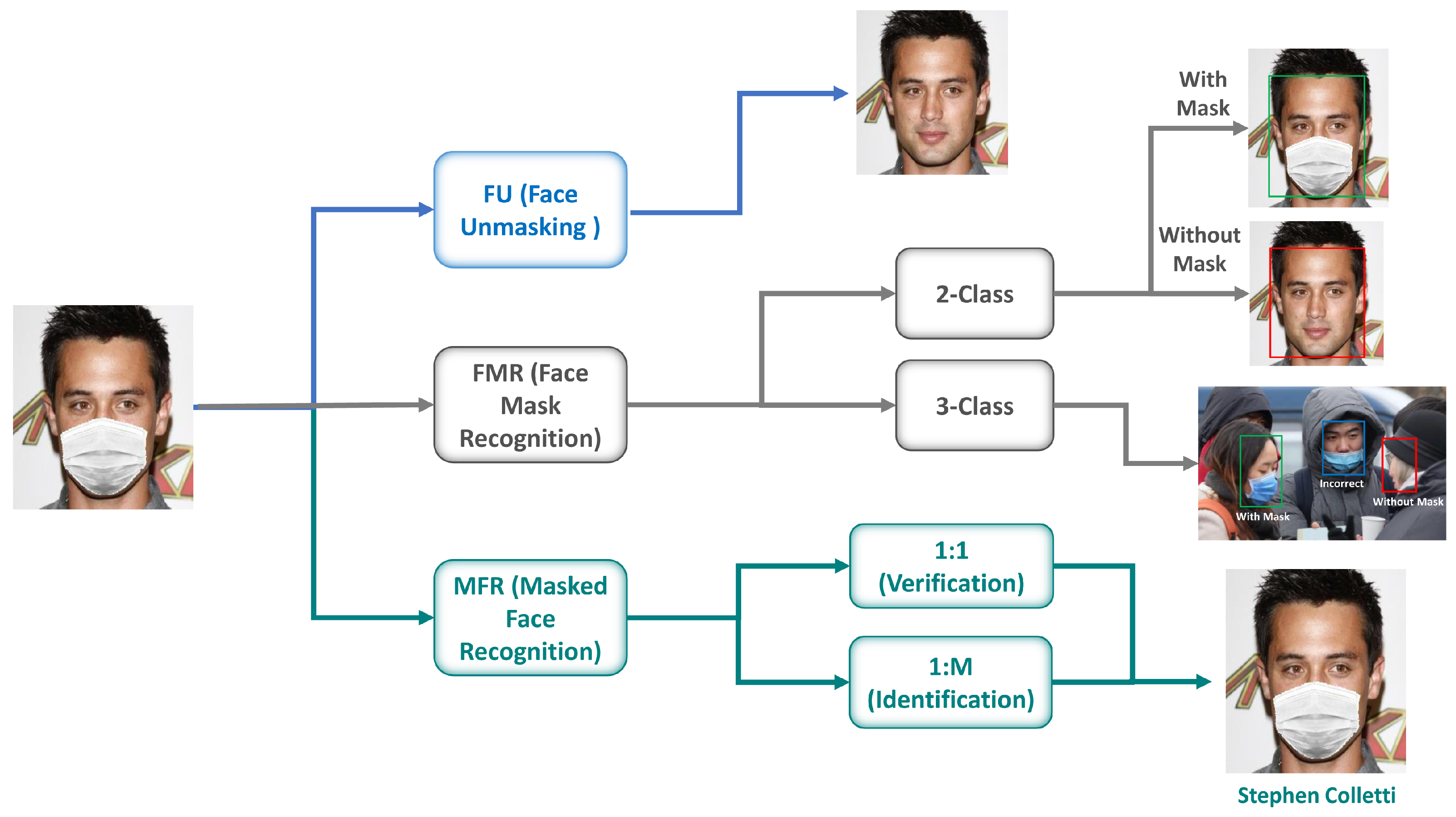
Construyendo un Modelo de Reconocimiento Facial Enmascarado
La configuración adecuada del entorno forma la base para un desarrollo exitoso del modelo. Comience instalando paquetes esenciales de Python que proporcionen las capacidades computacionales, de procesamiento de imágenes y de aprendizaje automático requeridas para las tareas de reconocimiento facial. Las bibliotecas clave incluyen NumPy para operaciones numéricas, Pandas para manipulación de datos, OpenCV para procesamiento de imágenes, Matplotlib para visualización y Keras para la implementación de redes neuronales. La biblioteca Pillow maneja la carga y manipulación de imágenes, mientras que Pickle permite la serialización del modelo para guardar y cargar sistemas entrenados. Un entorno correctamente configurado asegura que todas las herramientas necesarias estén disponibles para las etapas de desarrollo posteriores, desde la preparación de datos hasta la implementación del modelo. Esta configuración proporciona el marco para implementar APIs y SDKs de IA sofisticados que podrían integrarse con su sistema de reconocimiento.
Paso 1: Configuración del Entorno y Configuración de Bibliotecas
Datos de alta calidad y bien preparados sirven como la piedra angular de sistemas efectivos de reconocimiento facial. Esta guía utiliza una versión modificada del conjunto de datos Labeled Faces in the Wild (LFW), aumentada con imágenes enmascaradas simuladas para crear ejemplos de entrenamiento realistas. El conjunto de datos LFW estándar contiene fotografías de rostros etiquetadas adecuadas para tareas de reconocimiento, pero carece de ejemplos enmascarados. Para abordar esta limitación, generamos imágenes enmascaradas sintéticas superponiendo programáticamente plantillas de máscaras en rostros existentes utilizando técnicas de procesamiento de imágenes como mezcla alfa y transformaciones geométricas. Este enfoque crea un conjunto de datos equilibrado que contiene ejemplos enmascarados y no enmascarados, proporcionando la variación necesaria para que los modelos aprendan representaciones de características robustas. La preparación adecuada del conjunto de datos involucra múltiples etapas: cargar imágenes con etiquetas correspondientes, redimensionar a dimensiones consistentes, normalizar valores de píxeles y dividir en subconjuntos de entrenamiento y validación. La preparación meticulosa de datos influye directamente en el rendimiento del modelo, asegurando que el sistema reciba ejemplos de alta calidad y representativos que permitan un aprendizaje efectivo en condiciones variadas.
Paso 2: Preparación Integral del Conjunto de Datos
El modelo FaceNet, desarrollado por investigadores de Google, proporciona una base preentrenada poderosa para tareas de reconocimiento facial. Esta sofisticada arquitectura de red neuronal convolucional genera incrustaciones faciales compactas: representaciones vectoriales densas que capturan características faciales distintivas en un espacio de baja dimensión. Estas incrustaciones permiten operaciones eficientes de verificación, identificación y agrupación de rostros. Cargar el modelo FaceNet preentrenado implica importar tanto la arquitectura de la red como los pesos aprendidos, y luego configurarlo para extracción de características en lugar de reentrenamiento completo. Este enfoque de aprendizaje por transferencia aprovecha el conocimiento adquirido de conjuntos de datos masivos de rostros, reduciendo el tiempo de desarrollo y los requisitos computacionales. El modelo procesa imágenes de rostros para producir incrustaciones de 128 o 512 dimensiones que sirven como características de entrada para las etapas de clasificación posteriores. La eficiencia de FaceNet lo hace adecuado para implementación en entornos con recursos limitados, incluyendo dispositivos periféricos y aplicaciones móviles. Al construir sobre esta base establecida, los desarrolladores pueden centrarse en adaptar el sistema para escenarios de rostros enmascarados en lugar de entrenar desde cero.
Paso 3: Implementación del Modelo FaceNet
Con las incrustaciones faciales extraídas usando FaceNet, la siguiente etapa implica construir un clasificador que mapee estas representaciones numéricas a identidades específicas. Esta guía emplea un clasificador de Máquina de Vectores de Soporte (SVM), un algoritmo robusto bien adaptado para la clasificación de características de alta dimensión. Los SVMs funcionan identificando el hiperplano óptimo que separa maximalmente las diferentes clases en el espacio de características. Entrenar el clasificador implica alimentarlo con las incrustaciones faciales junto con sus etiquetas de identidad correspondientes del conjunto de datos de entrenamiento. El SVM aprende los patrones distintivos asociados con cada individuo, permitiéndole clasificar con precisión nuevos ejemplos no vistos. Los pasos críticos de preprocesamiento incluyen la normalización L2 de las incrustaciones para asegurar escalas de características consistentes y la codificación de etiquetas para convertir identidades textuales a valores numéricos. El entrenamiento y validación adecuados del clasificador aseguran que el sistema pueda distinguir de manera confiable entre individuos basándose en sus características faciales, incluso cuando porciones del rostro están oscurecidas por máscaras. Esta capa de clasificación representa donde muchas plataformas de automatización de IA integrarían la capacidad de reconocimiento en flujos de trabajo más amplios de seguridad o identificación.
Paso 4: Desarrollo y Entrenamiento del Clasificador
Las pruebas exhaustivas con imágenes previamente no vistas proporcionan la validación definitiva del rendimiento del modelo y la capacidad de generalización. Esta fase crítica implica cargar nuevas imágenes, tanto enmascaradas como no enmascaradas, que el modelo no ha encontrado durante el entrenamiento. El proceso de prueba refleja la canalización de preprocesamiento: las imágenes se redimensionan, normalizan y procesan a través del modelo FaceNet para generar incrustaciones. Estas incrustaciones luego pasan a través del clasificador SVM entrenado para producir predicciones de identidad. Comparar estas predicciones con las etiquetas de verdad fundamental cuantifica la precisión del modelo en diferentes condiciones. Probar específicamente con imágenes enmascaradas evalúa la robustez del sistema a las oclusiones, mientras que las pruebas no enmascaradas establecen el rendimiento de referencia. La evaluación integral debería incluir métricas más allá de la simple precisión, como precisión, recuperación y puntuación F1, particularmente para conjuntos de datos desequilibrados. Esta metodología de prueba rigurosa asegura que el modelo funcione de manera confiable en escenarios de implementación del mundo real, proporcionando confianza en su aplicabilidad práctica para sistemas de seguridad, control de acceso o identificación.
Aplicaciones en el Mundo Real y Consideraciones de Implementación
La tecnología de reconocimiento facial enmascarado encuentra aplicaciones en numerosos sectores donde la identificación sigue siendo esencial a pesar de las cubiertas faciales. En entornos de atención médica, la tecnología permite un control de acceso seguro mientras se adapta a los requisitos de mascarillas médicas. Los puntos de control de seguridad en aeropuertos e instalaciones gubernamentales se benefician de capacidades de identificación mantenidas durante mandatos de salud pública. Los sistemas de seguridad minorista pueden continuar monitoreando a pesar de que los clientes usen máscaras, mientras que las instituciones financieras preservan los procesos de autenticación para individuos enmascarados. La tecnología también admite sistemas de seguridad biométrica en entornos corporativos donde las políticas de máscaras pueden fluctuar. Cada dominio de aplicación presenta requisitos únicos con respecto a umbrales de precisión, velocidad de procesamiento e integración con la infraestructura de seguridad existente. Comprender estos casos de uso variados ayuda a los desarrolladores a adaptar los sistemas a contextos operativos específicos y expectativas de rendimiento.
Aplicaciones Diversas en la Industria
La implementación exitosa del reconocimiento facial enmascarado requiere una consideración cuidadosa de la arquitectura del sistema y los componentes técnicos. La canalización completa típicamente incluye etapas de detección de rostros, alineación, extracción de características y clasificación. Para escenarios de rostros enmascarados, pasos de preprocesamiento adicionales pueden involucrar detección de máscaras y técnicas de alineación especializadas que se centran en las regiones faciales superiores. Los arquitectos de sistemas deben equilibrar los requisitos de precisión con las restricciones computacionales, particularmente para aplicaciones en tiempo real. Las implementaciones basadas en la nube ofrecen escalabilidad y actualizaciones fáciles, mientras que la computación periférica proporciona ventajas de privacidad y latencia reducida. La integración con sistemas de seguridad existentes a menudo requiere APIs estandarizadas y compatibilidad con infraestructura heredada. El monitoreo del rendimiento y los mecanismos de mejora continua aseguran que los sistemas mantengan la precisión a medida que emergen nuevos estilos de máscaras y tendencias de cubiertas faciales. Estas decisiones arquitectónicas impactan significativamente la practicidad y efectividad de los sistemas implementados en diferentes entornos operativos.
Implementación Técnica y Arquitectura del Sistema
Optimizar los sistemas de reconocimiento facial enmascarado involucra múltiples estrategias para mejorar la precisión mientras se gestionan los recursos computacionales. Las técnicas de aumento de datos específicamente adaptadas para escenarios enmascarados, incluyendo posiciones, tipos y colores variados de máscaras, mejoran la robustez del modelo. Los enfoques de aprendizaje por transferencia ajustan finamente modelos preentrenados en conjuntos de datos de rostros enmascarados, acelerando el desarrollo mientras mantienen el rendimiento. Los métodos de conjunto que combinan múltiples algoritmos pueden aumentar la precisión aprovechando fortalezas complementarias. Los mecanismos de atención que ponderan dinámicamente las regiones faciales ayudan a los sistemas a centrarse en las características visibles más discriminatorias. El reentrenamiento regular del modelo con datos recién recolectados previene la degradación del rendimiento con el tiempo. Estas técnicas de optimización permiten a los desarrolladores crear sistemas eficientes y precisos adecuados para la implementación práctica en diversos escenarios del mundo real, desde instalaciones de alta seguridad hasta lugares públicos.
Técnicas de Optimización del Rendimiento
Consideraciones Éticas y Despliegue Responsable
El despliegue de sistemas de reconocimiento facial enmascarado plantea consideraciones importantes de privacidad que requieren atención cuidadosa. Las organizaciones deben implementar prácticas transparentes de manejo de datos, comunicando claramente cómo se recopilan, almacenan y procesan los datos faciales. El cifrado seguro de las plantillas almacenadas y los datos en tránsito protege contra el acceso no autorizado. Establecer políticas de retención de datos que limiten la duración del almacenamiento reduce los riesgos de privacidad. Proporcionar mecanismos de exclusión donde sea factible respeta la autonomía individual mientras mantiene la seguridad donde sea absolutamente necesario. Estas salvaguardas de privacidad ayudan a equilibrar los beneficios de seguridad con los derechos fundamentales, fomentando la confianza pública en el uso responsable de la tecnología en diferentes contextos y aplicaciones.
Protección de la Privacidad y Seguridad de Datos
Navegar por el panorama regulatorio en evolución representa un aspecto crítico del despliegue responsable del reconocimiento facial enmascarado. Diferentes jurisdicciones han implementado requisitos variables con respecto a la recolección y procesamiento de datos biométricos. El GDPR de la Unión Europea establece pautas estrictas para el manejo de datos biométricos, mientras que varios estados de EE. UU. han promulgado sus propias leyes de privacidad biométrica. El cumplimiento implica implementar evaluaciones de impacto de protección de datos, obtener el consentimiento apropiado donde se requiera y mantener documentación integral de las actividades de procesamiento de datos. La adhesión a estándares técnicos emergentes asegura la interoperabilidad y facilita la auditoría de terceros. Los esfuerzos de cumplimiento proactivos no solo cumplen con las obligaciones legales, sino que también demuestran el compromiso organizacional con las prácticas éticas de tecnología, potencialmente mejorando la aceptación y confianza pública.
Cumplimiento Normativo y Estándares
Pros y Contras
Ventajas
- Permite una identificación confiable a pesar de la oclusión facial parcial
- Mejora la seguridad en entornos donde las máscaras se usan comúnmente
- Se adapta a los requisitos de salud y seguridad pública en evolución
- Se integra perfectamente con la infraestructura existente de reconocimiento facial
- Abre nuevas aplicaciones en entornos de atención médica y médicos
- Mantiene la funcionalidad durante períodos de uso estacional de máscaras
- Proporciona continuidad del servicio durante emergencias de salud pública
Desventajas
- Generalmente menor precisión en comparación con los sistemas de reconocimiento no enmascarados
- Requiere conjuntos de datos de entrenamiento especializados con ejemplos enmascarados
- Mayores requisitos computacionales para el manejo complejo de oclusiones
- Plantea preocupaciones adicionales de privacidad con la identificación enmascarada
- Vulnerabilidad potencial a ataques adversariales que explotan oclusiones
Conclusión
El reconocimiento facial enmascarado representa una adaptación crucial de la tecnología biométrica a las realidades contemporáneas donde las cubiertas faciales se han vuelto comunes. Al aprovechar enfoques avanzados de aprendizaje profundo, preparación integral de conjuntos de datos y diseño de sistema reflexivo, los desarrolladores pueden crear sistemas de identificación robustos que mantienen la funcionalidad a pesar de las oclusiones faciales parciales. La vía de implementación técnica proporciona un marco práctico para construir soluciones efectivas. Sin embargo, el despliegue exitoso requiere igual atención a las consideraciones éticas, mitigación de sesgos y cumplimiento normativo. A medida que la tecnología continúa evolucionando, el refinamiento continuo mejorará aún más la precisión y expandirá los casos de uso aplicables. Cuando se implementa de manera responsable, la tecnología de reconocimiento facial enmascarado ofrece capacidades valiosas para seguridad, control de acceso e identificación en diversos sectores.
Preguntas frecuentes
¿Qué tan preciso es el reconocimiento facial con imágenes enmascaradas?
Los sistemas modernos de reconocimiento facial con mascarillas pueden lograr más del 90% de precisión con datos de entrenamiento y algoritmos adecuados. El rendimiento depende de la calidad del conjunto de datos, la arquitectura del modelo y las características visibles específicas disponibles. Los sistemas entrenados en conjuntos de datos diversos de mascarillas generalmente superan a los adaptados de modelos de reconocimiento estándar.
¿Cuáles son las principales preocupaciones éticas con el reconocimiento facial?
Las principales preocupaciones éticas incluyen violaciones de privacidad, sesgos demográficos, uso indebido potencial por parte de las autoridades y falta de consentimiento. El despliegue responsable requiere transparencia, mitigación de sesgos, cumplimiento normativo y pautas de uso claras para equilibrar los beneficios de seguridad con la protección de los derechos individuales.
¿Pueden los sistemas de reconocimiento facial existentes manejar mascarillas?
Los sistemas estándar experimentan caídas significativas de precisión con mascarillas. El reconocimiento efectivo con mascarillas requiere reentrenamiento con conjuntos de datos enmascarados, extracción de características especializada centrada en las regiones superiores de la cara y, a menudo, modificaciones arquitectónicas para manejar específicamente los patrones de oclusión.
¿Qué tipos de mascarillas son más desafiantes para el reconocimiento facial?
Las mascarillas de color sólido que cubren la nariz y la boca plantean el mayor desafío, mientras que las mascarillas transparentes o parciales pueden permitir una mejor extracción de características. Los sistemas entrenados en diversos tipos de mascarillas funcionan de manera más robusta en diferentes escenarios de enmascaramiento.
¿Cómo pueden las organizaciones garantizar el uso ético del reconocimiento facial con mascarillas?
Las organizaciones deben implementar políticas de transparencia, obtener consentimiento cuando sea posible, auditar regularmente en busca de sesgos, cumplir con las regulaciones y utilizar principios de minimización de datos para proteger la privacidad y garantizar un despliegue responsable de la tecnología.
Artículos relevantes sobre IA y tendencias tecnológicas
Mantente al día con las últimas ideas, herramientas e innovaciones que dan forma al futuro de la IA y la tecnología.
Grok AI: Generación Ilimitada de Videos Gratuita a partir de Texto e Imágenes | Guía 2024
Grok AI ofrece generación ilimitada de videos gratuita a partir de texto e imágenes, haciendo accesible la creación de videos profesionales para todos sin necesidad de habilidades de edición.
Configuración de Grok 4 Fast en Janitor AI: Guía Completa de Juego de Roles Sin Filtros
Guía paso a paso para configurar Grok 4 Fast en Janitor AI para juego de roles sin restricciones, incluyendo configuración de API, ajustes de privacidad y consejos de optimización
Las 3 mejores extensiones gratuitas de IA para programar en VS Code 2025 - Aumenta la productividad
Descubre las mejores extensiones gratuitas de agentes de IA para programar en Visual Studio Code en 2025, incluyendo Gemini Code Assist, Tabnine y Cline, para mejorar tu