Annotation
- Introducción
- ¿Por qué elegir código abierto para IA?
- Presentando Docling: Un héroe de código abierto
- Comparando Docling con alternativas de código cerrado
- Técnicas esenciales: Extracción, análisis, fragmentación, incrustación y recuperación
- Ejecutando el ejemplo de Docling
- Pros y contras
- Conclusión
- Preguntas frecuentes
Docling Análisis de Documentos de Código Abierto: Guía Completa de Implementación de IA
Guía de análisis de documentos de código abierto Docling para IA: implemente procesamiento de PDF, fragmentación, incrustación y canalizaciones RAG localmente.

Introducción
En el entorno empresarial actual impulsado por datos, los agentes de IA se han convertido en herramientas esenciales para el soporte al cliente y el análisis de datos. La base de los sistemas de IA efectivos radica en su capacidad para acceder y comprender información específica de la empresa, que a menudo reside en documentos, PDFs y sitios web. Si bien existen numerosas herramientas comerciales para el análisis de documentos, muchas conllevan costos de API y limitaciones de código cerrado. Docling surge como una poderosa alternativa de código abierto que proporciona control completo sobre tu pipeline de procesamiento de documentos mientras mantiene la privacidad de los datos y la flexibilidad de personalización.
¿Por qué elegir código abierto para IA?
Al desarrollar agentes de IA, el acceso a datos propietarios es crucial para lograr resultados significativos. Estos datos típicamente incluyen documentos internos, informes en PDF y sitios web de la empresa que contienen conocimiento específico sobre tu organización. Las soluciones de análisis tradicionales a menudo requieren enviar datos sensibles a plataformas de terceros, creando posibles vulnerabilidades de seguridad y gastos continuos de licencias. Las alternativas de código abierto como Docling eliminan estas preocupaciones al permitir el procesamiento local dentro de tu propia infraestructura.
Las ventajas del análisis de documentos de código abierto van más allá del ahorro de costos. Obtienes transparencia completa sobre cómo se procesan tus datos, la capacidad de personalizar la lógica de análisis para estructuras de documentos únicas y libertad del bloqueo del proveedor. Este enfoque se alinea particularmente bien con los requisitos empresariales de gobernanza y cumplimiento de datos. Para las organizaciones que exploran soluciones de extracción de documentos con IA, el código abierto proporciona beneficios tanto técnicos como estratégicos.

Las herramientas de código abierto ofrecen un valor significativo a través de varios beneficios clave: control completo sobre los pipelines de procesamiento de datos, posibilidades ilimitadas de personalización, operaciones transparentes que mejoran la seguridad, soporte activo de la comunidad y reducciones sustanciales de costos en comparación con las alternativas propietarias. Estas ventajas hacen que el código abierto sea particularmente atractivo para las organizaciones que construyen plataformas de automatización de IA integrales que requieren capacidades confiables de procesamiento de documentos.
Presentando Docling: Un héroe de código abierto
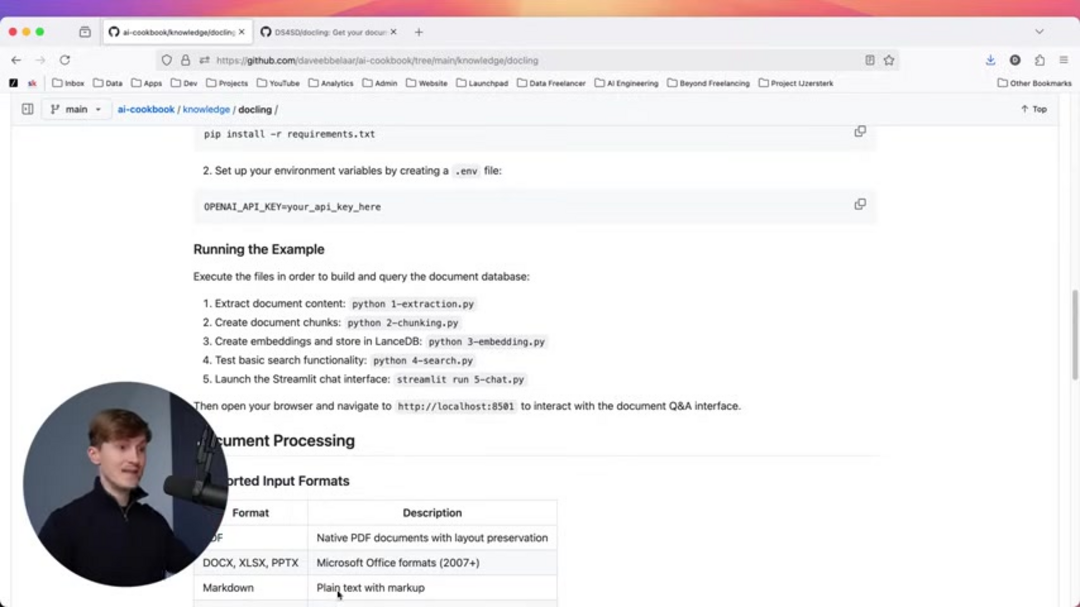
Docling representa una biblioteca sofisticada de procesamiento de documentos de código abierto que transforma diversos formatos de documentos en datos estructurados unificados. Construida con capacidades avanzadas de IA, se destaca en el análisis de diseño y el reconocimiento de estructuras de tablas mientras mantiene la eficiencia del procesamiento local. La biblioteca admite una amplia gama de formatos, incluidos PDFs, archivos DOCX, hojas de cálculo XLSX, presentaciones PPTX, documentos Markdown, páginas HTML y varios formatos de imagen.

Lo que distingue a Docling son sus opciones de salida flexibles, que permiten a los desarrolladores exportar contenido procesado a formatos HTML, Markdown, JSON o texto plano. Esta versatilidad lo hace ideal para la integración en flujos de trabajo y aplicaciones existentes. El sistema opera eficientemente en hardware estándar y presenta una arquitectura extensible que permite a los desarrolladores incorporar modelos personalizados o modificar pipelines de procesamiento para requisitos específicos. Esto hace que Docling sea particularmente valioso para sistemas de búsqueda de documentos empresariales, implementaciones de recuperación de pasajes y proyectos de extracción de conocimiento.
Para desarrolladores que trabajan con APIs y SDKs de IA, Docling proporciona una base sólida para construir pipelines de Generación Aumentada por Recuperación (RAG). Sus capacidades avanzadas de fragmentación y optimizaciones de procesamiento aseguran que las aplicaciones GenAI reciban entradas de conocimiento bien estructuradas, mejorando significativamente la calidad y precisión de las respuestas en sistemas de respuesta a preguntas basados en documentos.
Comparando Docling con alternativas de código cerrado
Al evaluar soluciones de análisis de documentos, es esencial entender cómo Docling se compara con alternativas comerciales como Microsoft Azure AI Document Intelligence, Amazon Textract y varios servicios propietarios. La distinción fundamental radica en la naturaleza de código abierto de Docling versus el enfoque de código cerrado y dependiente de API de las ofertas comerciales.
Los servicios comerciales de análisis de documentos típicamente operan con modelos de precios basados en el uso que pueden volverse costosos a escala. Cada documento procesado incurre en costos, y las operaciones de alto volumen pueden acumular rápidamente gastos significativos. Además, estos servicios requieren enviar documentos sensibles a servidores externos, planteando preocupaciones de privacidad de datos y posibles problemas de cumplimiento para organizaciones que manejan información confidencial.
Docling elimina estas preocupaciones al permitir un procesamiento local completo sin dependencias externas. Tus datos nunca salen de tu infraestructura, asegurando máxima seguridad y cumplimiento con las regulaciones de protección de datos. El modelo de código abierto también proporciona oportunidades ilimitadas de personalización: puedes modificar la lógica de análisis, agregar soporte para tipos de documentos especializados o integrar modelos de IA personalizados adaptados a tus requisitos específicos. Este nivel de flexibilidad típicamente no está disponible en soluciones comerciales de editor de PDF y análisis que ofrecen opciones de configuración limitadas.
Técnicas esenciales: Extracción, análisis, fragmentación, incrustación y recuperación
Construir un pipeline efectivo de extracción de conocimiento involucra varias etapas interconectadas que transforman documentos crudos en información contextual y buscable. Cada etapa juega un papel crítico en asegurar que tus agentes de IA puedan acceder y utilizar efectivamente el contenido del documento.
Antes de comenzar la implementación, asegúrate de tener los prerrequisitos necesarios instalados. Comienza instalando los paquetes requeridos usando pip install -r requirements.txt, que debe incluir Docling y cualquier dependencia adicional. Crea un archivo .env para almacenar variables de entorno, incluyendo tu clave de API de OpenAI para la generación de incrustaciones si usas modelos externos.
La construcción del pipeline sigue estas etapas clave:
- Extracción: Comienza extrayendo contenido de documentos fuente usando el convertidor de documentos de Docling. Después de instalar via pip install docling, puedes procesar PDFs, URLs y varios formatos de archivo en contenido estructurado legible. Esta etapa inicial maneja la detección de formato y la extracción de contenido mientras preserva la estructura del documento.
- Análisis: La fase de análisis identifica y categoriza elementos del documento, incluidos párrafos de texto, listas, tablas y componentes estructurales. Docling convierte el contenido a formato Markdown mientras mantiene las relaciones semánticas entre elementos, haciendo el contenido más fácil de manipular y procesar en etapas posteriores.
- Fragmentación: La fragmentación de documentos segmenta lógicamente el contenido para un procesamiento óptimo. El fragmentador híbrido de Docling ajusta automáticamente los tamaños de fragmento basándose en la estructura del contenido, evitando fragmentos excesivamente pequeños mientras divide secciones grandes según parámetros de ajuste de texto. Esto asegura la preservación del contexto mientras mantiene unidades de procesamiento manejables.
- Incrustación: La etapa de incrustación convierte los fragmentos de texto procesados en vectores numéricos usando modelos de incrustación. Puedes utilizar varios modelos, incluyendo las incrustaciones de OpenAI o alternativas de código abierto, creando representaciones vectoriales que capturan significado semántico para operaciones eficientes de búsqueda por similitud.
- Recuperación: La etapa final implica almacenar incrustaciones en una base de datos vectorial como LanceDB, permitiendo búsqueda eficiente por similitud y recuperación de contexto. Esto permite que los agentes y asistentes de IA localicen rápidamente secciones relevantes del documento al responder preguntas o proporcionar información.
Ejecutando el ejemplo de Docling
Para demostrar una implementación práctica, sigue estos pasos secuenciales para construir y probar un pipeline completo de procesamiento de documentos. Asegúrate de que cada paso se complete exitosamente antes de proceder al siguiente y mantén la seguridad adecuada para tus archivos de configuración de entorno.
- Ejecuta python 1-extraction.py para extraer contenido del documento de tus archivos fuente o URLs, generando salida estructurada lista para procesamiento adicional.
- Ejecuta python 2-chunking.py para crear fragmentos de documento de tamaño óptimo usando los algoritmos de segmentación inteligente de Docling, preparando el contenido para la generación de incrustaciones.
- Procesa python 3-embedding.py para generar incrustaciones y almacenarlas en la base de datos vectorial LanceDB, creando el índice de búsqueda para tu contenido de documento.
- Prueba la funcionalidad básica de búsqueda con python 4-search.py para verificar que tu pipeline esté funcionando correctamente y devolviendo resultados relevantes para consultas de muestra.
- Lanza la interfaz de chat interactiva de Streamlit usando streamlit run 5-chat.py, proporcionando una forma amigable para el usuario de consultar tu base de conocimiento de documentos.
Después de completar estos pasos, abre tu navegador web y navega a localhost:8501 para acceder a la interfaz de preguntas y respuestas de documentos. Esto proporciona una demostración práctica de cómo Docling permite la interacción inteligente con documentos a través de capacidades de editor de documentos y búsqueda integradas en interfaces conversacionales.
Pros y contras
Ventajas
- Solución completa de código abierto con licencia MIT
- El procesamiento local asegura máxima privacidad de datos
- Amplio soporte de formatos, incluidos PDF y DOCX
- Análisis de diseño avanzado y reconocimiento de tablas
- Formatos de salida flexibles para integración
- Pipeline de análisis personalizable para necesidades únicas
- Soporte activo de la comunidad y documentación
Desventajas
- Requiere experiencia técnica para la implementación
- Integración limitada de modelos de lenguaje visual
- Comprensión compleja de documentos de química
- Limitaciones de hardware local para grandes volúmenes
Conclusión
Docling representa un avance significativo en el procesamiento de documentos de código abierto, proporcionando a las organizaciones una alternativa poderosa a los servicios comerciales de análisis. Su soporte integral de formatos, capacidades avanzadas de IA y arquitectura flexible lo hacen ideal para construir sistemas sofisticados de extracción de conocimiento. Al permitir el procesamiento local y la personalización completa, Docling aborda preocupaciones críticas en torno a la privacidad de datos, el control de costos y la flexibilidad de integración. Ya sea que estés desarrollando agentes de IA, construyendo pipelines RAG o creando soluciones de búsqueda empresarial, Docling ofrece las herramientas y capacidades necesarias para transformar el contenido de documentos en inteligencia accionable mientras mantienes control completo sobre tus datos y flujos de trabajo de procesamiento.
Preguntas frecuentes
¿Qué formatos de archivo admite Docling?
Docling admite una amplia gama de formatos de documentos, incluidos PDF, DOCX, XLSX, PPTX, Markdown, HTML y varios formatos de imagen, lo que lo hace versátil para diversas necesidades de procesamiento de documentos.
¿Es Docling realmente de código abierto?
Sí, Docling utiliza la licencia MIT, proporcionando acceso completo de código abierto sin restricciones ni tarifas de licencia para uso comercial o personal.
¿Cómo mejora Docling las canalizaciones RAG?
Docling optimiza las canalizaciones RAG mediante fragmentación avanzada, análisis de diseño y reconocimiento de tablas, proporcionando a las aplicaciones GenAI conocimiento estructurado y contextual de los documentos.
¿Puede Docling procesar documentos localmente?
Sí, Docling opera completamente localmente en hardware estándar, garantizando la privacidad de los datos y eliminando la dependencia de API externas o servicios en la nube.
¿Qué hardware se recomienda para Docling?
Docling se ejecuta en hardware estándar, pero para grandes volúmenes, se recomiendan CPU multinúcleo y suficiente RAM; la GPU puede acelerar algunos modelos si está integrada.