Annotation
- Introducción
- Comprendiendo la Clasificación de Texto Personalizada
- Por Qué Elegir el Servicio de Lenguaje de IA de Azure para la Clasificación de Texto
- Configuración del Servicio de Lenguaje de IA de Azure
- Entrenando Tu Modelo de Clasificación de Texto Personalizado
- Estructura de Precios del Servicio de Lenguaje de IA de Azure
- Características y Capacidades Principales
- Aplicaciones Prácticas y Casos de Uso
- Desafíos Comunes de Implementación
- Pros y Contras
- Conclusión
- Preguntas frecuentes
Servicio de lenguaje de Azure AI: Guía de configuración y entrenamiento de clasificación de texto personalizada
Aprenda a implementar la clasificación de texto personalizada con el Servicio de lenguaje de Azure AI, desde la configuración y el entrenamiento hasta la implementación, para un texto preciso

Introducción
En el entorno empresarial actual rico en datos, categorizar y comprender eficazmente los datos de texto se ha vuelto esencial para impulsar decisiones informadas. El Servicio de Lenguaje de IA de Azure de Microsoft proporciona capacidades potentes de procesamiento de lenguaje natural, incluyendo la clasificación de texto personalizada que permite a las organizaciones construir sistemas de categorización a medida. Este tutorial completo te guía a través del proceso completo de configuración, entrenamiento e implementación de modelos de clasificación de texto personalizados utilizando la infraestructura en la nube de Azure.
Comprendiendo la Clasificación de Texto Personalizada
La clasificación de texto personalizada representa un enfoque de aprendizaje automático especializado que asigna automáticamente categorías predefinidas a documentos de texto según tus requisitos empresariales específicos. A diferencia del análisis de texto general que podría centrarse en el análisis de sentimientos o la extracción de frases clave, la clasificación de texto personalizada te permite definir categorías específicas del dominio que se alinean con las necesidades de tu organización. Por ejemplo, podrías clasificar tickets de soporte al cliente en categorías como 'Problema Técnico', 'Consulta de Facturación' o 'Solicitud de Función' – proporcionando contexto inmediato para el enrutamiento y la resolución.
El Servicio de Lenguaje de IA de Azure ofrece capacidades de nivel empresarial para construir soluciones sofisticadas de clasificación de texto que escalan con el volumen de datos y los requisitos de complejidad.
Por Qué Elegir el Servicio de Lenguaje de IA de Azure para la Clasificación de Texto
El Servicio de Lenguaje de IA de Azure ofrece varias ventajas convincentes para las organizaciones que implementan clasificación de texto personalizada. La arquitectura nativa en la nube de la plataforma garantiza una escalabilidad perfecta para manejar volúmenes masivos de texto sin degradación del rendimiento. Los algoritmos avanzados de aprendizaje automático y las técnicas de procesamiento de lenguaje natural ofrecen altas tasas de precisión, mientras que las opciones de personalización te permiten entrenar modelos específicamente en tu dominio de datos. El servicio se integra sin problemas con otras APIs y SDKs de IA y plataformas de automatización de IA, creando un ecosistema integral de IA. El modelo de precios de pago por uso proporciona flexibilidad de optimización de costos, haciéndolo accesible tanto para experimentos pequeños como para implementaciones de producción a gran escala.
Configuración del Servicio de Lenguaje de IA de Azure
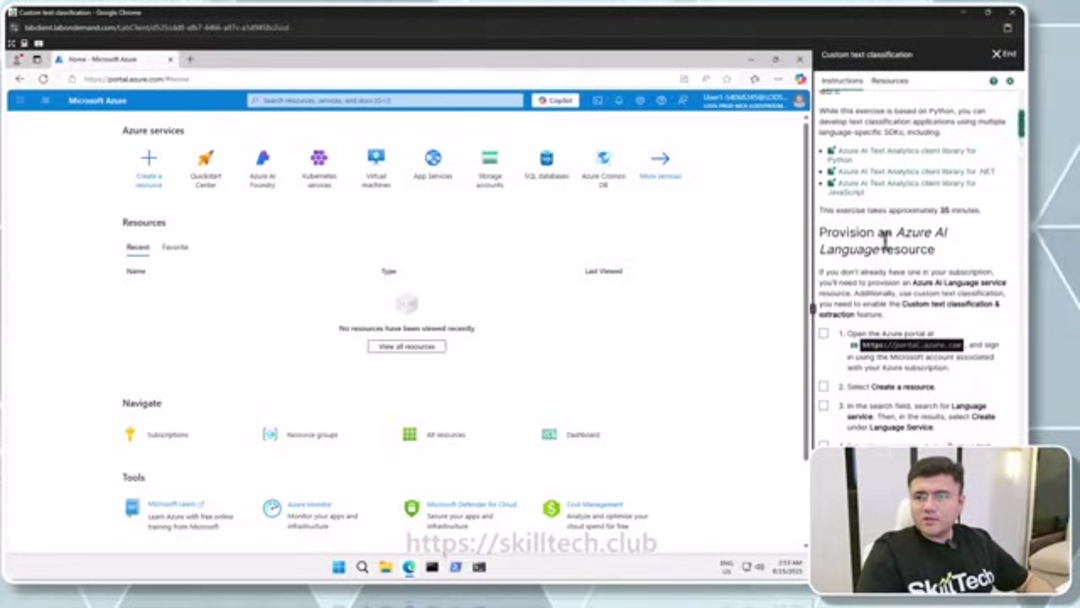
Antes de comenzar el proceso de configuración, asegúrate de tener una suscripción activa de Azure. Microsoft ofrece cuentas de prueba gratuitas para nuevos usuarios, proporcionando crédito para explorar servicios sin compromiso financiero inmediato. El proceso de configuración implica varios pasos clave que establecen la base para tus proyectos de clasificación de texto.
El paso inicial implica crear un recurso de Lenguaje de IA de Azure a través del portal de Azure. Este recurso sirve como el punto central de gestión para tus modelos de clasificación de texto personalizados y proporciona acceso a Language Studio – la interfaz basada en web para el desarrollo de modelos. Después de iniciar sesión en portal.azure.com con tus credenciales, navega a 'Crear un recurso' y busca 'Servicio de Lenguaje'. Selecciona el servicio apropiado de los resultados y procede con la creación.
Durante la configuración, proporciona detalles esenciales incluyendo tu suscripción de Azure, grupo de recursos para la gestión organizacional y selección de región geográfica – elegir ubicaciones cerca de tus fuentes de datos puede mejorar el rendimiento. Asigna un nombre único para tu recurso del Servicio de Lenguaje y selecciona el nivel de precios que coincida con el alcance de tu proyecto. El nivel Gratuito F0 funciona bien para experimentación, mientras que los entornos de producción típicamente requieren niveles Estándar o Premium para límites de transacción más altos y características avanzadas.
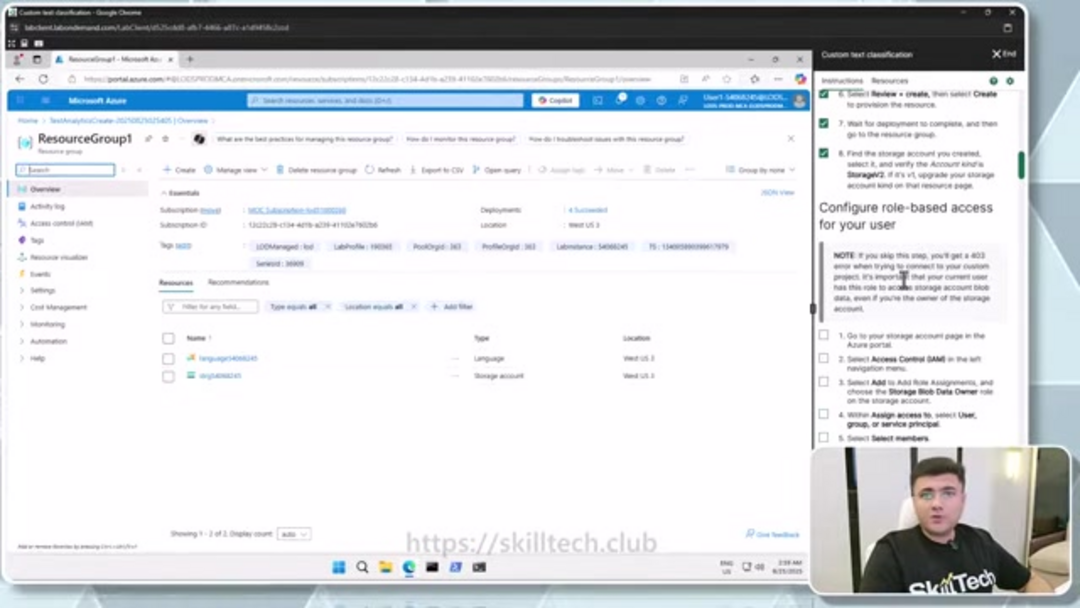
El Servicio de Lenguaje de IA de Azure requiere cuentas de almacenamiento asociadas para la funcionalidad operativa. Durante la creación del recurso, configurarás una nueva cuenta de almacenamiento o vincularás una existente, asegurando que se seleccione Almacenamiento con Redundancia Local Estándar (LRS) para confiabilidad. Después de que se complete la implementación, configura el control de acceso basado en roles navegando a la sección Control de Acceso (IAM) de tu cuenta de almacenamiento. Agrega una asignación de rol seleccionando 'Propietario de Datos de Blob de Almacenamiento' y asígnalo a tu cuenta de usuario, permitiendo permisos adecuados para las operaciones de entrenamiento de modelos.
Entrenando Tu Modelo de Clasificación de Texto Personalizado
Con la infraestructura establecida, el proceso de entrenamiento del modelo comienza con la preparación y etiquetado de datos – pasos críticos que impactan directamente la precisión y el rendimiento de la clasificación.
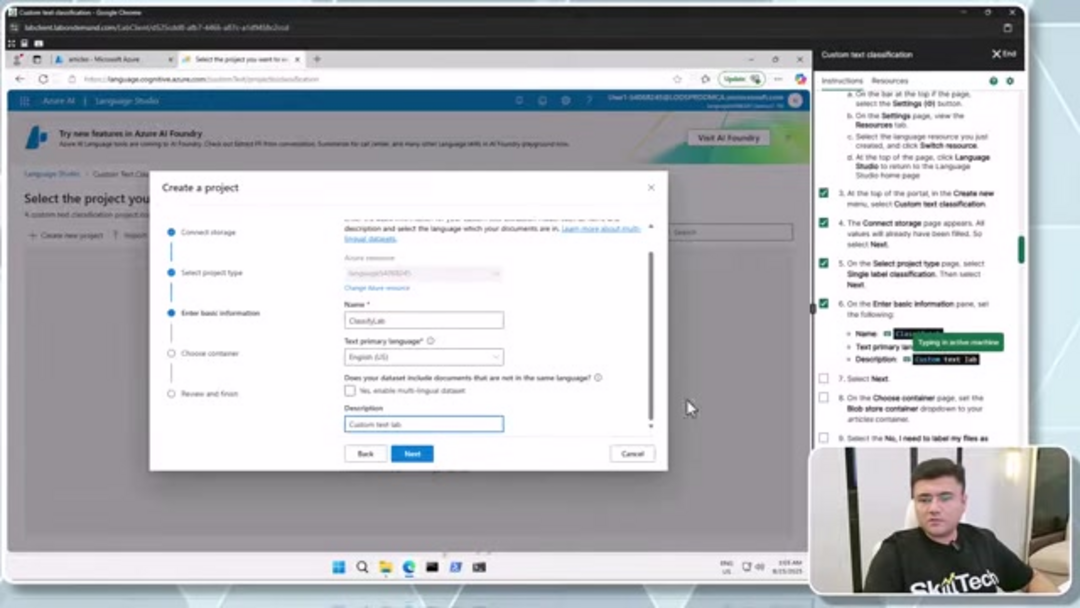
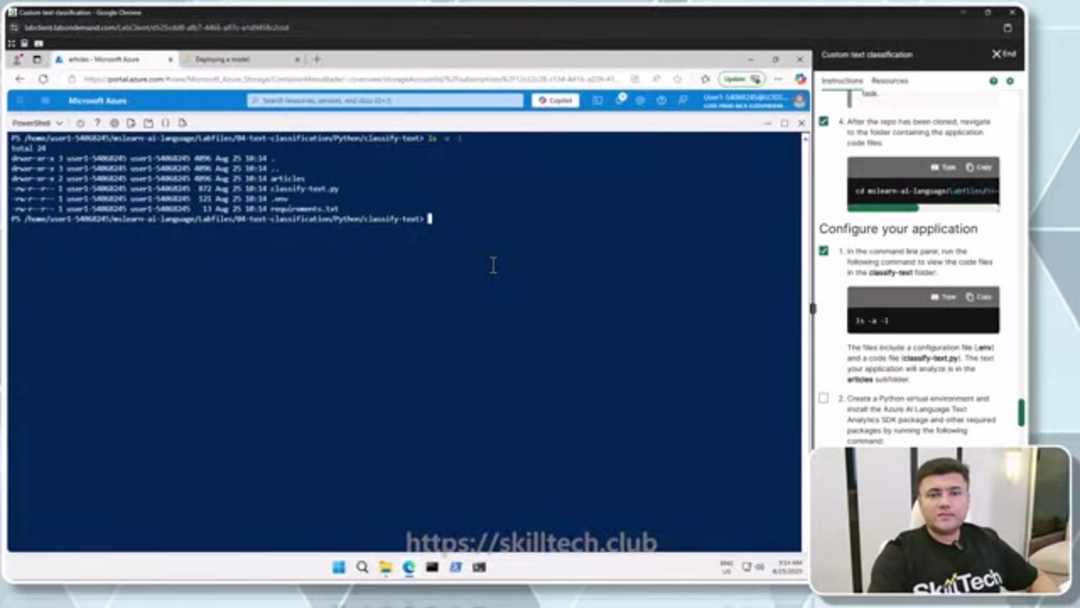
Comienza creando un contenedor dedicado dentro de tu cuenta de almacenamiento específicamente para documentos de entrenamiento. Navega a la sección Contenedores y crea un nuevo contenedor llamado "articles" con el nivel de acceso establecido en "Contenedor" para permitir operaciones de blob adecuadas. Sube tus documentos de muestra – estos deben representar las diversas categorías de texto que deseas clasificar. Para resultados óptimos, asegúrate de que tu conjunto de datos de entrenamiento incluya ejemplos suficientes de cada categoría, con documentos que representen de manera realista las variaciones de texto que tu modelo encontrará en producción. Esta fase de preparación es crucial para construir agentes y asistentes de IA efectivos que puedan procesar y categorizar información con precisión.
El etiquetado de datos proporciona la base estructurada que permite a tu modelo aprender las distinciones de categorías. En Language Studio, accede a la sección Etiquetado de Datos donde verás los archivos subidos desde tu cuenta de almacenamiento. Crea clases personalizadas que coincidan con tus necesidades de clasificación – por ejemplo, podrías establecer categorías como 'Deportes', 'Noticias', 'Entretenimiento' y 'Clasificados' para una aplicación de medios. Asigna sistemáticamente cada documento a su categoría apropiada, asegurando un etiquetado consistente en todo tu conjunto de datos. Este enfoque meticuloso de preparación de datos influye significativamente en la precisión del modelo y la capacidad de generalización.
Inicia el proceso de entrenamiento accediendo a Trabajos de Entrenamiento en Language Studio. Crea un nuevo trabajo de entrenamiento nombrado apropiadamente para tu proyecto, como "ClassifyArticles". Configura la división de datos entre conjuntos de entrenamiento y prueba – la división predeterminada 80/20 típicamente proporciona un buen equilibrio entre el aprendizaje del modelo y la validación. Durante el entrenamiento, Azure emplea técnicas avanzadas de aprendizaje automático para analizar patrones en tus datos etiquetados y construir capacidades de clasificación. Después de que se complete el entrenamiento, evalúa el rendimiento del modelo usando las métricas proporcionadas, incluyendo medidas de precisión, recuperación y puntuación F1 que indican qué tan bien tu modelo distingue entre categorías.
Estructura de Precios del Servicio de Lenguaje de IA de Azure
Comprender el modelo de precios de Azure ayuda en la planificación del presupuesto y la optimización de costos. El Nivel Gratuito (F0) proporciona transacciones mensuales limitadas adecuadas para experimentación y proyectos de prueba de concepto. El Nivel Estándar (S0) opera con precios de pago por uso basados en el volumen de transacciones, ideal para aplicaciones en crecimiento con patrones de uso variables. El Nivel Premium ofrece precios de capacidad reservada para implementaciones empresariales de alto volumen que requieren costos predecibles y máximo rendimiento. Considera tu volumen esperado de procesamiento de texto y requisitos de tiempo de respuesta al seleccionar el nivel apropiado para tu implementación.
Características y Capacidades Principales
El Servicio de Lenguaje de IA de Azure ofrece funcionalidad integral de procesamiento de lenguaje natural más allá de la clasificación de texto personalizada. El análisis de sentimientos determina el tono emocional en el texto, mientras que la extracción de frases clave identifica conceptos y temas centrales. La detección de idioma reconoce automáticamente el idioma del texto, y el reconocimiento de entidades nombradas identifica personas, organizaciones y ubicaciones mencionadas en el contenido. El servicio también admite reconocimiento de entidades nombradas personalizadas para entidades específicas del dominio y respuesta a preguntas personalizadas para construir bases de conocimiento inteligentes. Estas capacidades pueden combinarse para crear herramientas de escritura de IA y chatbots de IA sofisticados que entiendan y procesen el lenguaje natural de manera efectiva.
Aplicaciones Prácticas y Casos de Uso
La clasificación de texto personalizada encuentra aplicación en numerosas industrias y funciones empresariales. Las organizaciones de servicio al cliente automatizan la categorización de tickets, enrutando consultas a equipos apropiados basándose en el análisis de contenido. Los proveedores de salud clasifican registros médicos y comentarios de pacientes para una mejor coordinación de la atención y eficiencia operativa. Las instituciones financieras analizan documentos, noticias e informes para la evaluación de riesgos e identificación de oportunidades. Las plataformas de comercio electrónico categorizan reseñas de productos y comentarios de clientes para mejorar el descubrimiento y la satisfacción. Las empresas de medios clasifican contenido para recomendaciones personalizadas y compromiso de la audiencia. Estas aplicaciones demuestran cómo la clasificación de texto se integra con herramientas de IA conversacional y asistentes de correo electrónico de IA para automatizar el procesamiento de información.
Desafíos Comunes de Implementación
Varios desafíos pueden surgir durante los proyectos de clasificación de texto personalizada. El desequilibrio de datos ocurre cuando algunas categorías tienen significativamente más ejemplos de entrenamiento que otras, potencialmente creando modelos sesgados – técnicas como el sobremuestreo de clases minoritarias pueden abordar esto. El sobreajuste sucede cuando los modelos se vuelven demasiado complejos y funcionan mal en nuevos datos – la regularización y la validación cruzada ayudan a mantener la generalización. La disponibilidad limitada de datos etiquetados puede restringir el entrenamiento del modelo – los enfoques de aprendizaje activo y las técnicas de transferencia de aprendizaje pueden optimizar conjuntos de datos limitados. Las definiciones ambiguas de categorías confunden a los modelos durante el entrenamiento – dedicar tiempo adecuado a establecer categorías claras y distintas mejora los resultados. Los problemas de calidad de datos, incluyendo ruido e inconsistencia, impactan el rendimiento – una limpieza y preprocesamiento exhaustivos de datos establecen una base sólida para una clasificación precisa.
Pros y Contras
Ventajas
- Infraestructura en la nube altamente escalable maneja grandes volúmenes de texto de manera eficiente
- Algoritmos avanzados de aprendizaje automático ofrecen resultados de clasificación precisos
- Opciones de personalización completas para definiciones de categorías específicas del dominio
- Integración perfecta con el ecosistema integral de servicios de Azure
- Precios flexibles de pago por uso optimizan los costos operativos
- Seguridad de nivel empresarial y certificaciones de cumplimiento
- Mejora continua del modelo a través de capacidades de reentrenamiento
Desventajas
- Requiere una suscripción activa de Azure y dependencia de la nube
- Curva de aprendizaje más pronunciada para los recién llegados a los servicios de Azure
- Los costos pueden escalar significativamente con el uso de alto volumen
- Funcionalidad fuera de línea limitada debido a su naturaleza basada en la nube
- Consideraciones de gobernanza de datos para información sensible
Conclusión
El Servicio de Lenguaje de IA de Azure proporciona una plataforma robusta y escalable para implementar soluciones de clasificación de texto personalizadas que transforman texto no estructurado en información categorizada accionable. Siguiendo el proceso completo de configuración, entrenamiento e implementación descrito en esta guía, las organizaciones pueden construir sistemas de clasificación a medida que aborden necesidades empresariales específicas. Las capacidades de integración del servicio con otros servicios de IA de Azure y los modelos de precios flexibles lo hacen accesible para proyectos de diversas escalas y complejidades. A medida que los datos de texto continúan creciendo en volumen e importancia, dominar la clasificación de texto personalizada se vuelve cada vez más valioso para extraer insights, automatizar procesos y mejorar la toma de decisiones en todas las funciones empresariales.
Preguntas frecuentes
¿Para qué se utiliza el Servicio de lenguaje de Azure AI?
El Servicio de lenguaje de Azure AI es una plataforma de procesamiento de lenguaje natural basada en la nube que proporciona capacidades de análisis de texto, incluido el análisis de sentimientos, la extracción de frases clave, la detección de idiomas, el reconocimiento de entidades nombradas y la clasificación de texto personalizada para aplicaciones empresariales.
¿Cuánto cuesta el Servicio de lenguaje de Azure AI?
El Servicio de lenguaje de Azure AI ofrece nivel Gratuito (F0) para experimentación, precios estándar (S0) de pago por uso para aplicaciones en crecimiento y nivel Premium con capacidad reservada para implementaciones empresariales con costos predecibles basados en el volumen de transacciones.
¿Cuáles son los principales desafíos en la clasificación de texto personalizada?
Los desafíos clave incluyen el desequilibrio de datos entre categorías, el sobreajuste del modelo, datos de entrenamiento etiquetados limitados, definiciones de categorías ambiguas y problemas de calidad de datos que requieren un preprocesamiento cuidadoso y una configuración del modelo.
¿Qué tan precisa es la clasificación de texto personalizada de Azure?
La precisión depende de la calidad y cantidad de los datos de entrenamiento, pero los algoritmos avanzados de aprendizaje automático de Azure generalmente ofrecen altas tasas de precisión y recuperación cuando se entrenan adecuadamente con documentos representativos suficientes y bien etiquetados.
¿Cuánto tiempo lleva entrenar un modelo de clasificación de texto personalizada?
El tiempo de entrenamiento varía según el tamaño y la complejidad de los datos, pero generalmente oscila entre unos minutos y varias horas para grandes conjuntos de datos utilizando la infraestructura escalable de Azure.
Artículos relevantes sobre IA y tendencias tecnológicas
Mantente al día con las últimas ideas, herramientas e innovaciones que dan forma al futuro de la IA y la tecnología.
Grok AI: Generación Ilimitada de Videos Gratuita a partir de Texto e Imágenes | Guía 2024
Grok AI ofrece generación ilimitada de videos gratuita a partir de texto e imágenes, haciendo accesible la creación de videos profesionales para todos sin necesidad de habilidades de edición.
Configuración de Grok 4 Fast en Janitor AI: Guía Completa de Juego de Roles Sin Filtros
Guía paso a paso para configurar Grok 4 Fast en Janitor AI para juego de roles sin restricciones, incluyendo configuración de API, ajustes de privacidad y consejos de optimización
Las 3 mejores extensiones gratuitas de IA para programar en VS Code 2025 - Aumenta la productividad
Descubre las mejores extensiones gratuitas de agentes de IA para programar en Visual Studio Code en 2025, incluyendo Gemini Code Assist, Tabnine y Cline, para mejorar tu