Annotation
- Introducción
- Comprendiendo los Modelos de Lenguaje Grandes Multilingües
- ¿Qué Son los Modelos de Lenguaje Grandes Multilingües?
- Aportaciones Clave de la Investigación en MLLM
- La Importancia de los Modelos de Lenguaje Multilingües
- Progreso Reciente y Desafíos Globales
- Estrategias de Alineación de Parámetros en MLLMs
- Recursos de Datos para el Entrenamiento de MLLM
- Métodos de Alineación por Ajuste de Parámetros
- Direcciones y Desafíos Futuros de la Investigación
- Ventajas y Desventajas
- Conclusión
- Preguntas frecuentes
Modelos de Lenguaje Grande Multilingües: Guía Completa de Recursos y Tendencias Futuras
Los modelos de lenguaje grande multilingües (MLLM) permiten la comunicación de IA cross-lingual con recursos integrales, taxonomía y tendencias futuras para el ámbito global
Introducción
Los Modelos de Lenguaje Grandes Multilingües (MLLMs) representan un avance transformador en la inteligencia artificial, permitiendo una comunicación fluida a través de diversos paisajes lingüísticos. Estos sofisticados sistemas de IA pueden procesar, comprender y generar texto en múltiples idiomas simultáneamente, derribando las barreras lingüísticas tradicionales que durante mucho tiempo han obstaculizado la colaboración global y el intercambio de información. A medida que las organizaciones operan cada vez más a través de fronteras internacionales, la demanda de capacidades robustas de IA multilingüe continúa creciendo exponencialmente.
Comprendiendo los Modelos de Lenguaje Grandes Multilingües
¿Qué Son los Modelos de Lenguaje Grandes Multilingües?
Los Modelos de Lenguaje Grandes Multilingües (MLLMs) constituyen un paso evolutivo significativo más allá de los sistemas de IA monolingües tradicionales. A diferencia de sus contrapartes de un solo idioma, los MLLMs están específicamente diseñados para manejar múltiples idiomas dentro de una arquitectura unificada, permitiendo la comprensión y generación interlingüística sin requerir modelos separados para cada idioma. Este enfoque integrado permite una utilización más eficiente de los recursos y facilita capacidades multilingües genuinas que reflejan la flexibilidad lingüística humana.
La innovación central de los MLLMs radica en su capacidad para aprender representaciones compartidas entre idiomas, capturando patrones lingüísticos y relaciones semánticas que trascienden los límites individuales de los idiomas. Esta comprensión interlingüística permite aplicaciones que van desde servicios de traducción en tiempo real hasta sistemas de soporte al cliente multinacionales impulsados por chatbots de IA avanzados y herramientas de IA conversacional.
Aportaciones Clave de la Investigación en MLLM
El innovador artículo de investigación "Multilingual Large Language Model: A Survey of Resources, Taxonomy and Frontiers" de Libo Qin y sus colegas representa un hito en la investigación de IA multilingüe. Este trabajo integral proporciona el primer examen sistemático del desarrollo de MLLM, ofreciendo a investigadores y profesionales un marco unificado para comprender este campo en rápida evolución. La importancia del artículo se extiende más allá de los círculos académicos, proporcionando ideas prácticas para desarrolladores que trabajan con API y SDK de IA para implementar capacidades multilingües.
Entre sus contribuciones más valiosas se encuentra la recopilación de extensos recursos de código abierto, incluyendo conjuntos de datos curados, artículos de investigación y puntos de referencia de rendimiento. Esta compilación de recursos aborda una brecha crítica en el campo, proporcionando a los desarrolladores las herramientas necesarias para acelerar la implementación y evaluación de MLLM en diversos contextos lingüísticos.
La Importancia de los Modelos de Lenguaje Multilingües
Progreso Reciente y Desafíos Globales
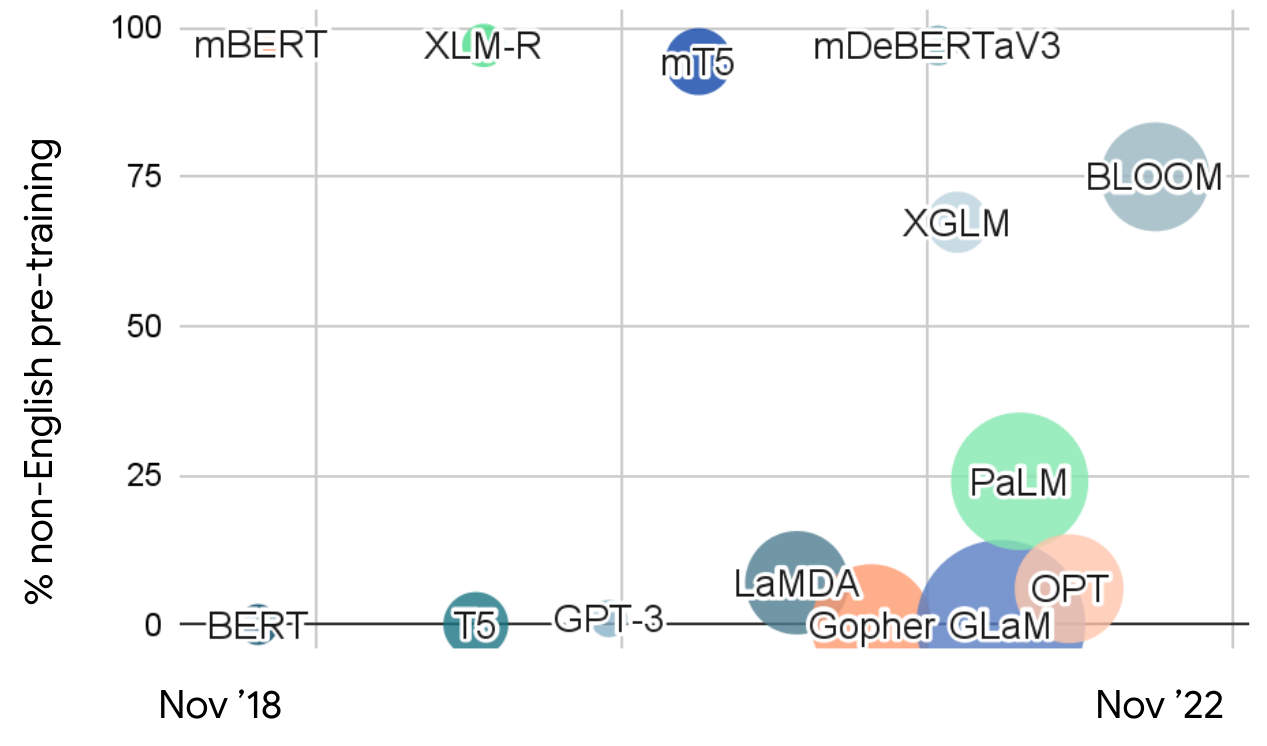
Los avances recientes en modelos de lenguaje grandes han demostrado capacidades notables en la comprensión y generación del lenguaje natural. Sin embargo, el enfoque predominante en el entrenamiento en inglés ha creado limitaciones significativas para el despliegue global. Con más de 7.000 idiomas hablados en todo el mundo y las crecientes demandas de globalización, la necesidad de sistemas de IA verdaderamente multilingües nunca ha sido más urgente. Esta brecha es particularmente pronunciada en escenarios de idiomas de bajos recursos, donde los datos de entrenamiento limitados y los recursos computacionales presentan desafíos sustanciales.
El sesgo centrado en el inglés en la mayoría de los LLMs actuales crea disparidades en la accesibilidad y el rendimiento de la IA en diferentes comunidades lingüísticas. Los MLLMs abordan este desequilibrio al proporcionar un acceso más equitativo a la tecnología del lenguaje, permitiendo a las organizaciones desplegar capacidades de IA consistentes en los mercados globales a través de plataformas de automatización de IA y sistemas de servicio multilingües.
Estrategias de Alineación de Parámetros en MLLMs
La alineación de parámetros representa un desafío técnico fundamental en el desarrollo de MLLM, determinando cuán efectivamente los modelos pueden transferir conocimiento y capacidades entre idiomas. Las dos metodologías de alineación principales – enfoques de ajuste de parámetros y parámetros congelados – ofrecen ventajas y compensaciones distintas para diferentes escenarios de despliegue.
La alineación por ajuste de parámetros implica ajustar activamente los parámetros del modelo durante el entrenamiento para optimizar el rendimiento interlingüístico. Este método generalmente produce resultados superiores pero requiere recursos computacionales sustanciales y un ajuste cuidadoso para evitar sobreajuste o interferencia lingüística. En contraste, la alineación con parámetros congelados aprovecha las capacidades existentes del modelo a través de técnicas de indicación estratégica, ofreciendo mayor eficiencia y despliegue más rápido para organizaciones que utilizan agentes y asistentes de IA.
Recursos de Datos para el Entrenamiento de MLLM
La efectividad de los modelos multilingües depende críticamente de la calidad y diversidad de los datos de entrenamiento a través de las diferentes etapas lingüísticas. Los datos de preentrenamiento de modelos como GPT-3, mT5 y ERNIE 3.0 proporcionan la comprensión lingüística fundamental, mientras que los datos de ajuste fino de recursos como Flan-PaLM y BLOOMZ permiten la optimización específica de tareas. Los datos de aprendizaje por refuerzo a partir de retroalimentación humana (RLHF) refinan aún más el comportamiento del modelo basado en preferencias humanas, creando interacciones multilingües más naturales y contextualmente apropiadas.
Cada categoría de datos sirve propósitos distintos en la pipeline de desarrollo del modelo, con el preentrenamiento multilingüe estableciendo capacidades lingüísticas amplias y el ajuste fino supervisado especializando modelos para aplicaciones específicas. La curación y equilibrado cuidadosos de estos conjuntos de datos entre idiomas es esencial para lograr un rendimiento interlingüístico robusto, particularmente para desarrolladores que trabajan con servicios de alojamiento de modelos de IA.
Métodos de Alineación por Ajuste de Parámetros
La alineación por ajuste de parámetros emplea un enfoque sistemático y multi-etapa para optimizar el rendimiento de MLLM en todos los idiomas. El proceso comienza con la alineación de preentrenamiento, donde los modelos aprenden patrones lingüísticos fundamentales de diversos conjuntos de datos multilingües. Esta etapa fundamental establece las capacidades interlingüísticas básicas y las representaciones compartidas del modelo.
La alineación de ajuste fino supervisado luego refina estas capacidades para tareas y aplicaciones específicas, incorporando datos en formato de instrucción para mejorar el rendimiento en casos de uso específicos. La alineación de aprendizaje por refuerzo a partir de retroalimentación humana mejora aún más el comportamiento del modelo incorporando preferencias humanas y consideraciones de seguridad. Finalmente, la alineación de ajuste fino posterior adapta los modelos para escenarios de despliegue específicos, con técnicas eficientes en parámetros como LoRA (Adaptación de Bajo Rango) optimizando la utilización de recursos.
Direcciones y Desafíos Futuros de la Investigación
La continua evolución de los MLLMs enfrenta varios desafíos de investigación críticos que requieren atención enfocada. La detección y mitigación de alucinaciones multilingües representa un área particularmente urgente, ya que los modelos deben mantener precisión y confiabilidad en diversos contextos lingüísticos. La edición de conocimiento presenta otro desafío significativo, requiriendo métodos para actualizar y corregir información continuamente en todos los idiomas admitidos manteniendo la consistencia.
Las consideraciones de seguridad y equidad se extienden más allá del rendimiento técnico para abarcar el despliegue ético en contextos globales. Establecer puntos de referencia de seguridad integrales, desarrollar mecanismos efectivos de filtrado de contenido inseguro y garantizar un rendimiento equitativo en idiomas de bajos recursos son esenciales para el desarrollo responsable de MLLM. Estos esfuerzos se alinean con iniciativas más amplias en tecnología de aprendizaje de idiomas y aplicaciones de noticias multilingües que sirven a audiencias globales diversas.
Ventajas y Desventajas
Ventajas
- Permite una comunicación fluida en múltiples idiomas simultáneamente
- Facilita la comprensión intercultural y la colaboración global
- Apoya el desarrollo de aplicaciones y servicios internacionales
- Mejora la precisión en tareas de procesamiento del lenguaje natural multilingüe
- Reduce la necesidad de múltiples sistemas de IA de un solo idioma
- Mejora la accesibilidad para poblaciones que no hablan inglés
- Apoya mercados emergentes y comunidades de idiomas de bajos recursos
Desventajas
- Requiere extensos conjuntos de datos multilingües y recursos computacionales
- Desafiante optimizar el rendimiento en todos los idiomas admitidos
- Potencial de sesgos e inexactitudes en idiomas de bajos recursos
- Consideraciones complejas de seguridad y ética entre culturas
- Costos de desarrollo y mantenimiento más altos que los sistemas monolingües
Conclusión
Los Modelos de Lenguaje Grandes Multilingües representan un avance fundamental en la inteligencia artificial, ofreciendo capacidades sin precedentes para la comunicación interlingüística y la colaboración global. A medida que la investigación continúa abordando las limitaciones actuales en la mitigación de alucinaciones, edición de conocimiento y garantía de seguridad, los MLLMs jugarán un papel cada vez más vital en cerrar las brechas lingüísticas y permitir sistemas de IA más inclusivos. La taxonomía integral y la compilación de recursos proporcionadas por investigaciones recientes establecen una base sólida para la innovación futura, guiando a investigadores y profesionales hacia soluciones de IA multilingües más efectivas y equitativas que sirvan a diversas comunidades globales.
Preguntas frecuentes
¿Cuáles son los principales desafíos en el desarrollo de modelos de lenguaje grande multilingües?
Los desafíos clave incluyen manejar más de 7,000 idiomas con disponibilidad de datos variable, satisfacer las demandas de globalización para la comunicación cross-lingual y abordar escenarios de bajos recursos donde los datos y recursos computacionales son limitados, particularmente para idiomas subrepresentados.
¿Cuáles son las principales ventajas de utilizar modelos de lenguaje grande multilingües?
Los MLLM permiten una comunicación fluida a través de múltiples idiomas, facilitan la comprensión cross-cultural, apoyan el desarrollo de aplicaciones globales, mejoran la precisión de las tareas de PLN multilingüe y reducen la necesidad de mantener sistemas de IA separados para un solo idioma.
¿Qué áreas de investigación futuras son importantes para el desarrollo de MLLM?
Las áreas de investigación críticas incluyen abordar problemas de alucinación multilingüe, mejorar las capacidades de edición de conocimientos a través de idiomas, establecer puntos de referencia de seguridad integrales, garantizar la equidad en idiomas de bajos recursos y desarrollar estrategias de alineación más eficientes.
¿Cuáles son las estrategias clave de alineación de parámetros en los MLLM?
Los MLLM utilizan principalmente estrategias de alineación de ajuste de parámetros y parámetros congelados. El ajuste de parámetros implica ajustar los parámetros del modelo para la optimización cross-lingual, mientras que los parámetros congelados aprovechan las capacidades existentes a través del prompting para una mayor eficiencia.
¿Cómo impactan los MLLM en la accesibilidad y equidad global de la IA?
Los MLLM mejoran la accesibilidad global de la IA al proporcionar tecnología lingüística equitativa en diversas comunidades, reducir los sesgos centrados en el inglés y apoyar los idiomas de bajos recursos, promoviendo así la equidad en el despliegue de IA en todo el mundo.
Artículos relevantes sobre IA y tendencias tecnológicas
Mantente al día con las últimas ideas, herramientas e innovaciones que dan forma al futuro de la IA y la tecnología.
Grok AI: Generación Ilimitada de Videos Gratuita a partir de Texto e Imágenes | Guía 2024
Grok AI ofrece generación ilimitada de videos gratuita a partir de texto e imágenes, haciendo accesible la creación de videos profesionales para todos sin necesidad de habilidades de edición.
Configuración de Grok 4 Fast en Janitor AI: Guía Completa de Juego de Roles Sin Filtros
Guía paso a paso para configurar Grok 4 Fast en Janitor AI para juego de roles sin restricciones, incluyendo configuración de API, ajustes de privacidad y consejos de optimización
Las 3 mejores extensiones gratuitas de IA para programar en VS Code 2025 - Aumenta la productividad
Descubre las mejores extensiones gratuitas de agentes de IA para programar en Visual Studio Code en 2025, incluyendo Gemini Code Assist, Tabnine y Cline, para mejorar tu