Annotation
- Introducción
- Comprendiendo la Clasificación de Texto Zero-Shot
- Enfoques de Clasificación Tradicional vs Zero-Shot
- Resumen de la Biblioteca Hugging Face Transformers
- Mejorando el Rendimiento de la Clasificación Zero-Shot
- Guía de Implementación Práctica
- Precios y Licencias de Hugging Face
- Ventajas y Desventajas
- Aplicaciones y Casos de Uso en el Mundo Real
- Conclusión
- Preguntas frecuentes
Clasificación de Texto Cero-Shot con Hugging Face: Guía Práctica Completa
La clasificación de texto cero-shot con Hugging Face permite categorizar texto sin datos de entrenamiento. Esta guía cubre implementación, beneficios y código
Introducción
La clasificación de texto tradicional ha dependido durante mucho tiempo de conjuntos de datos etiquetados extensos, requiriendo un esfuerzo manual y recursos significativos. Sin embargo, la clasificación de texto zero-shot representa un cambio de paradigma en el procesamiento del lenguaje natural, permitiendo que los modelos de IA categorizen texto en clases predefinidas sin ningún entrenamiento previo en ejemplos etiquetados. Este enfoque revolucionario aprovecha el poder de los modelos de lenguaje preentrenados de la biblioteca Transformers de Hugging Face, haciendo que la clasificación de texto sea accesible incluso cuando no hay datos etiquetados disponibles. Esta guía completa explora la implementación práctica, los beneficios y las aplicaciones en el mundo real de la clasificación zero-shot para desarrolladores y científicos de datos.
Comprendiendo la Clasificación de Texto Zero-Shot
¿Qué es la Clasificación de Texto Zero-Shot?
La clasificación de texto zero-shot representa una técnica avanzada de aprendizaje automático donde los modelos categorizan texto en clases que no han encontrado durante el entrenamiento. A diferencia de los enfoques tradicionales que requieren conjuntos de datos etiquetados extensos, la clasificación zero-shot aprovecha las capacidades de comprensión semántica de los grandes modelos de lenguaje. Estos modelos, entrenados en corpus de texto masivos, desarrollan representaciones sofisticadas de las relaciones del lenguaje, permitiéndoles generalizar a nuevas tareas de clasificación sin entrenamiento adicional. Esta capacidad es particularmente valiosa en entornos dinámicos donde las categorías cambian con frecuencia o cuando los datos etiquetados son escasos.
El mecanismo subyacente implica comparar la similitud semántica entre el texto de entrada y las etiquetas candidatas utilizando el conocimiento preexistente del modelo. Cuando proporcionas una muestra de texto y categorías potenciales, el modelo evalúa qué tan estrechamente se alinea el texto con cada etiqueta basándose en su comprensión de los patrones del lenguaje y las relaciones contextuales. Este enfoque elimina la necesidad de etiquetado de datos que consume tiempo y del reentrenamiento del modelo, haciéndolo ideal para la creación rápida de prototipos y el despliegue en entornos de producción.
Enfoques de Clasificación Tradicional vs Zero-Shot
La clasificación de texto tradicional sigue un paradigma de aprendizaje supervisado, requiriendo conjuntos de datos cuidadosamente curados donde cada ejemplo de texto se etiqueta manualmente con su categoría correspondiente. Este proceso implica recolectar miles de ejemplos, anotarlos con las etiquetas apropiadas y entrenar un modelo especializado que aprende a reconocer patrones asociados con cada categoría. Si bien es efectivo, este enfoque demanda recursos sustanciales y se vuelve impráctico cuando se trata de temas emergentes o necesidades de clasificación que cambian rápidamente.
La clasificación zero-shot difiere fundamentalmente al utilizar modelos que ya han desarrollado una comprensión integral del lenguaje a través del preentrenamiento en diversas fuentes de texto. Estos modelos pueden inferir relaciones entre texto nuevo y etiquetas candidatas sin entrenamiento específico en las categorías objetivo. Las ventajas van más allá de solo eliminar el etiquetado de datos: la clasificación zero-shot ofrece una flexibilidad notable, permitiéndote adaptarte instantáneamente a nuevos esquemas de clasificación simplemente modificando las etiquetas candidatas. Esto lo hace particularmente valioso para aplicaciones en chatbots de IA y herramientas de IA conversacional donde las consultas de los usuarios pueden abarcar diversos temas.
Resumen de la Biblioteca Hugging Face Transformers
La biblioteca Hugging Face Transformers ha surgido como el recurso definitivo para el procesamiento moderno del lenguaje natural, proporcionando acceso simplificado a modelos preentrenados de vanguardia. Esta biblioteca integral abstrae las complejidades de la arquitectura del modelo y la implementación, permitiendo a los desarrolladores centrarse en resolver problemas prácticos en lugar de detalles técnicos. Para la clasificación zero-shot específicamente, Hugging Face ofrece versiones optimizadas de modelos populares como BERT, RoBERTa y DistilBERT, cada uno con fortalezas y características de rendimiento distintas.
Lo que hace que la biblioteca sea particularmente poderosa es su interfaz intuitiva de pipeline, que permite realizar tareas complejas de PLN con código mínimo. El pipeline de clasificación zero-shot maneja toda la complejidad subyacente, incluyendo tokenización, inferencia del modelo e interpretación de resultados, entregando una API limpia y fácil de usar. Esta accesibilidad ha democratizado las capacidades avanzadas de PLN, haciéndolas disponibles para desarrolladores sin experiencia profunda en aprendizaje automático o arquitecturas de transformadores. La compatibilidad de la biblioteca con varias APIs y SDKs de IA mejora aún más su utilidad en entornos de producción.
Mejorando el Rendimiento de la Clasificación Zero-Shot
Seleccionando Modelos Preentrenados Óptimos
Elegir el modelo preentrenado correcto impacta significativamente en la precisión y el rendimiento de la clasificación zero-shot. Diferentes modelos sobresalen en varios escenarios basados en sus datos de entrenamiento, arquitectura y casos de uso previstos. BERT (Bidirectional Encoder Representations from Transformers) sigue siendo una opción popular por su rendimiento robusto en diversos tipos de texto, habiendo sido entrenado en datos de Wikipedia y corpus de libros. Su mecanismo de atención bidireccional le permite comprender el contexto desde ambas direcciones, haciéndolo particularmente efectivo para tareas de clasificación matizadas.
RoBERTa (Robustly Optimized BERT Pretraining Approach) representa una versión optimizada que elimina el objetivo de predicción de la siguiente oración de BERT y emplea un entrenamiento más extenso con lotes más grandes y secuencias más largas. Estas optimizaciones a menudo resultan en un rendimiento superior para tareas zero-shot. Para entornos con recursos limitados, DistilBERT ofrece una alternativa convincente: esta versión destilada mantiene aproximadamente el 97% del rendimiento de BERT mientras es un 40% más pequeño y un 60% más rápido, haciéndolo ideal para aplicaciones que requieren inferencia rápida o despliegue en hardware limitado.
Formulación Estratégica de Etiquetas Candidatas
La calidad y formulación de las etiquetas candidatas influyen directamente en la precisión de la clasificación en escenarios zero-shot. Las etiquetas efectivas deben ser descriptivas, inequívocas y semánticamente distintas entre sí. En lugar de usar categorías de una sola palabra como "deportes", considera frases más descriptivas como "noticias de deportes profesionales" o "actividades atléticas amateur" que proporcionen señales semánticas más claras al modelo. Esta especificidad ayuda al modelo a comprender mejor los límites de categorización previstos y reduce la confusión entre conceptos similares.
Al tratar con sistemas de categorización jerárquicos, puedes estructurar las etiquetas para reflejar estas relaciones. Por ejemplo, en lugar de usar etiquetas planas como "baloncesto" y "fútbol", podrías implementar un enfoque jerárquico con "deportes - baloncesto - NBA" y "deportes - fútbol - NFL". Este etiquetado estructurado puede mejorar la precisión al aprovechar la comprensión del modelo de las relaciones de categoría. Además, considera incluir ejemplos negativos o etiquetas fuera de alcance cuando sea apropiado, ya que esto ayuda al modelo a distinguir mejor entre clasificaciones relevantes e irrelevantes para tu caso de uso específico.
Estrategias de Ajuste Fino Específicas del Dominio
Aunque la clasificación zero-shot funciona notablemente bien de inmediato, el rendimiento puede mejorarse aún más mediante el ajuste fino específico del dominio cuando está involucrada terminología o contexto especializado. El ajuste fino implica entrenamiento adicional en un pequeño conjunto de datos relevante para tu dominio específico, permitiendo que el modelo adapte su comprensión al vocabulario y conceptos especializados. Este enfoque es particularmente valioso para dominios técnicos como literatura médica, documentos legales o artículos científicos donde los modelos de lenguaje estándar pueden tener dificultades con la terminología específica del dominio.
El proceso de ajuste fino típicamente requiere un conjunto de datos modesto de ejemplos etiquetados de tu dominio objetivo: a menudo solo unos cientos de muestras pueden producir mejoras significativas. Durante el ajuste fino, el modelo ajusta sus parámetros para reconocer mejor los patrones y relaciones específicos de tu dominio mientras retiene sus capacidades generales de comprensión del lenguaje. Este enfoque híbrido combina la flexibilidad de la clasificación zero-shot con la precisión de la adaptación al dominio, haciéndolo ideal para aplicaciones especializadas en plataformas de automatización de IA y sistemas empresariales.
Guía de Implementación Práctica
Configuración del Entorno e Instalación
Comenzar con la clasificación zero-shot requiere una configuración mínima, gracias al ecosistema bien diseñado de Hugging Face. Comienza instalando los paquetes de Python necesarios usando pip. La biblioteca transformers proporciona la funcionalidad central, mientras que pandas ofrece capacidades convenientes de manipulación de datos para manejar conjuntos de datos de texto. Para un rendimiento óptimo, asegúrate de usar un entorno Python con versión 3.7 o superior, y considera configurar la aceleración por GPU si está disponible, ya que esto puede acelerar significativamente la inferencia para conjuntos de datos más grandes.
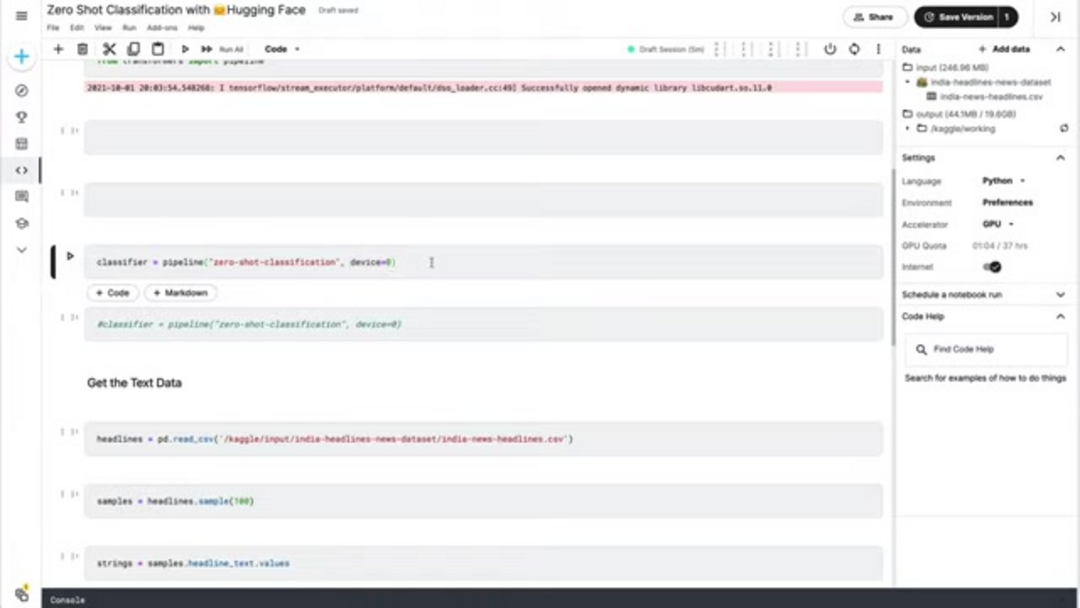
pip install transformers pandas torchDespués de la instalación, importa los componentes necesarios en tu script de Python o notebook. La función pipeline de transformers proporciona la interfaz de alto nivel para la clasificación zero-shot, mientras que pandas facilita la carga y manipulación de datos. Si tienes una GPU compatible con CUDA disponible, PyTorch la aprovechará automáticamente para computación acelerada, aunque la ejecución en CPU sigue siendo completamente funcional para aplicaciones a pequeña escala.
from transformers import pipeline
import pandas as pdPreparación de Datos e Inicialización del Clasificador
La preparación adecuada de datos es crucial para una clasificación zero-shot efectiva. Comienza cargando tus datos de texto desde archivos fuente: los formatos comunes incluyen CSV, JSON o archivos de texto plano. Para fines de demostración, asumiremos un archivo CSV que contiene titulares de noticias, pero el enfoque se generaliza a cualquier fuente de texto. Asegúrate de que tus datos de texto estén limpios y correctamente formateados, ya que los caracteres extraños o problemas de formato pueden afectar la precisión de la clasificación.
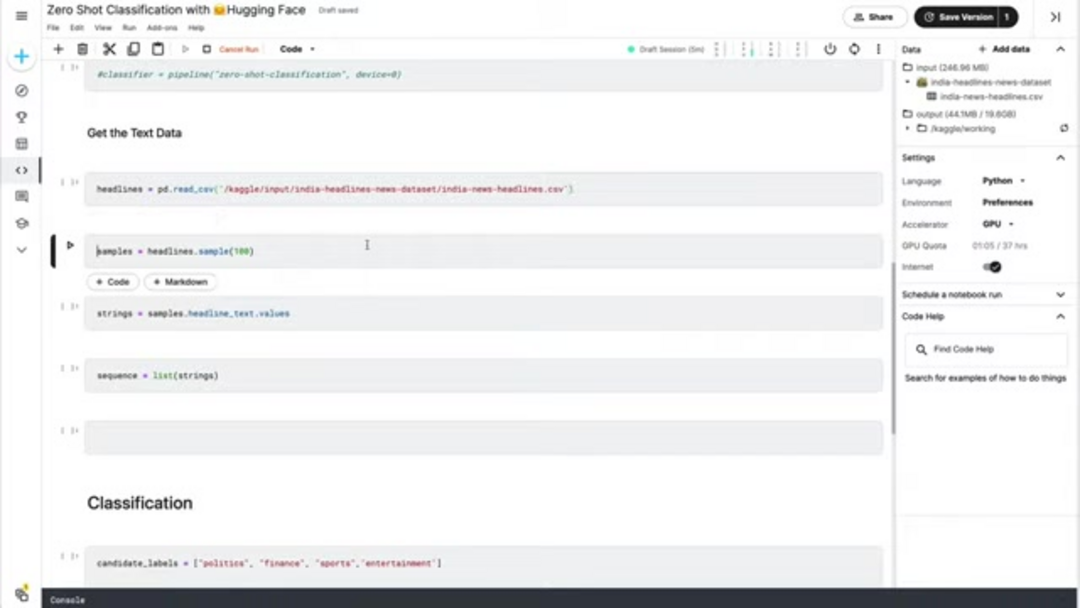
# Load headline data from CSV
headlines_df = pd.read_csv('news_headlines.csv')
headline_samples = headlines_df['headline_text'].sample(100).tolist()Inicializa el clasificador zero-shot usando la función pipeline de Hugging Face. El parámetro device te permite especificar si usar procesamiento de CPU o GPU: establecer device=0 habilita la primera GPU disponible para inferencia acelerada. El clasificador descarga y configura automáticamente un modelo preentrenado apropiado, típicamente una versión de BERT optimizada para tareas zero-shot.
# Initialize classifier with GPU acceleration
classifier = pipeline('zero-shot-classification', device=0)Ejecución de la Clasificación y Análisis de Resultados
Con tus datos preparados y el clasificador inicializado, define tus etiquetas candidatas basadas en las categorías que quieres identificar. Estas etiquetas representan las clasificaciones potenciales para tus datos de texto. Elige etiquetas que sean mutuamente excluyentes y cubran exhaustivamente los tipos de contenido esperados en tu conjunto de datos. Para la categorización de noticias, las etiquetas típicas podrían incluir política, negocios, deportes, entretenimiento, tecnología y salud.
candidate_labels = ['politics', 'business', 'sports', 'entertainment', 'technology', 'health']Ejecuta la clasificación pasando tus muestras de texto y etiquetas candidatas al clasificador. El modelo devuelve puntuaciones de probabilidad para cada etiqueta, indicando qué tan fuertemente se alinea el texto con cada categoría. Puedes procesar estos resultados para asignar la etiqueta de mayor probabilidad a cada muestra de texto o implementar filtrado basado en umbrales para excluir clasificaciones de baja confianza.
# Perform classification
classification_results = classifier(headline_samples, candidate_labels)
# Analyze and display results
for i, result in enumerate(classification_results):
top_label = result['labels'][0]
confidence = result['scores'][0]
print(f"Sample {i+1}: {headline_samples[i][:50]}...")
print(f"Predicted: {top_label} (confidence: {confidence:.3f})")
print("---")Precios y Licencias de Hugging Face
La biblioteca central Hugging Face Transformers y la mayoría de los modelos preentrenados están disponibles bajo licencias de código abierto, principalmente Apache 2.0, permitiendo su uso gratuito tanto para aplicaciones de investigación como comerciales. Esta accesibilidad ha sido instrumental en la adopción generalizada de modelos de transformadores en todas las industrias. La naturaleza de código abierto permite a los desarrolladores inspeccionar, modificar y extender la base de código para cumplir con requisitos específicos sin restricciones de licencia o costos.
Para usuarios empresariales que requieren capacidades mejoradas, Hugging Face ofrece servicios premium que incluyen APIs de inferencia acelerada, soporte experto dedicado y alojamiento privado de modelos. Estos servicios típicamente operan en modelos de suscripción con precios basados en el volumen de uso y las características requeridas. La API de inferencia proporciona infraestructura de despliegue optimizada con SLAs de rendimiento garantizados, mientras que el soporte experto ofrece acceso directo al equipo técnico de Hugging Face para asistencia con implementaciones complejas y desafíos de optimización. Estos servicios son particularmente valiosos para organizaciones que utilizan soluciones de alojamiento de modelos de IA a escala.
Ventajas y Desventajas
Ventajas
- Elimina la necesidad de etiquetado de datos costoso y que consume tiempo
- Instantáneamente adaptable a nuevas categorías sin reentrenamiento del modelo
- Capacidad de despliegue rápido para prueba de concepto y producción
- Solución rentable para organizaciones con recursos limitados de ML
- Excelente rendimiento en clasificación de texto de dominio general
- Escalable a través de múltiples idiomas y tipos de texto
- Mejora continua a medida que los modelos base reciben actualizaciones
Desventajas
- Precisión más baja en comparación con modelos supervisados con datos etiquetados abundantes
- Variabilidad de rendimiento en diferentes dominios y tipos de texto
- Dependencia de la calidad y especificidad de las etiquetas candidatas
- Control limitado sobre el comportamiento del modelo y los límites de decisión
- Sesgo potencial heredado de las fuentes de datos de preentrenamiento
Aplicaciones y Casos de Uso en el Mundo Real
La clasificación de texto zero-shot encuentra aplicaciones en numerosas industrias y escenarios donde la categorización de texto rápida y flexible es valiosa. En sistemas de gestión de contenidos, permite el etiquetado automático de artículos, publicaciones de blog y documentos sin intervención manual. Las organizaciones de noticias aprovechan la clasificación zero-shot para categorizar artículos entrantes en secciones temáticas, mientras que las plataformas de comercio electrónico la usan para organizar reseñas de productos y comentarios de clientes por tema o sentimiento.
Las operaciones de servicio al cliente se benefician del enrutamiento automático de tickets de soporte e consultas a departamentos apropiados basándose en el análisis de contenido. Las plataformas de redes sociales y comunidades en línea emplean la clasificación zero-shot para la moderación de contenido, identificando material inapropiado o categorizando contenido generado por usuarios. Las instituciones de investigación usan la técnica para organizar artículos académicos y literatura científica por campo o metodología. Estas aplicaciones demuestran la versatilidad de la clasificación zero-shot en agentes y asistentes de IA y varios contextos empresariales.
Conclusión
La clasificación de texto zero-shot representa un avance significativo en el procesamiento del lenguaje natural, democratizando el acceso a capacidades poderosas de categorización de texto sin el requisito tradicional de datos de entrenamiento etiquetados. Al aprovechar modelos preentrenados de la biblioteca Transformers de Hugging Face, los desarrolladores y organizaciones pueden implementar rápidamente sistemas de clasificación flexibles que se adaptan a necesidades evolutivas. Si bien el enfoque puede no siempre igualar la precisión de los métodos completamente supervisados con datos etiquetados abundantes, su flexibilidad, velocidad y rentabilidad lo hacen invaluable para numerosas aplicaciones prácticas. A medida que los modelos de lenguaje continúan mejorando, las capacidades de clasificación zero-shot probablemente se expandirán aún más, abriendo nuevas posibilidades para el procesamiento inteligente de texto en todas las industrias y casos de uso. Para aquellos que exploran varias soluciones de IA, los directorios completos de herramientas de IA pueden proporcionar contexto adicional y alternativas.
Preguntas frecuentes
¿Qué tipos de texto funcionan mejor para la clasificación cero-shot?
La clasificación cero-shot funciona bien con texto de dominio general como artículos de noticias, reseñas de productos, correos electrónicos y publicaciones en redes sociales. El contenido técnico o altamente especializado puede requerir adaptación de dominio para obtener resultados óptimos.
¿Cuántas etiquetas candidatas debo usar?
Utiliza 4-8 etiquetas bien definidas y distintas para obtener el mejor rendimiento. Demasiadas etiquetas no relacionadas pueden diluir los resultados, mientras que muy pocas pueden no cubrir todas las categorías relevantes en tus datos de texto.
¿La clasificación cero-shot siempre supera a la clasificación tradicional?
No – con abundantes datos etiquetados de alta calidad, los métodos supervisados a menudo logran una mayor precisión. La clasificación cero-shot sobresale cuando los datos etiquetados son escasos, las categorías cambian con frecuencia o se prioriza el despliegue rápido.
¿Puedo mejorar la precisión de la clasificación cero-shot?
Sí – prueba diferentes modelos preentrenados, refina las etiquetas candidatas para mayor claridad, utiliza etiquetado jerárquico para categorías complejas y considera el ajuste específico del dominio con datos etiquetados limitados cuando estén disponibles.
¿Cómo maneja la clasificación cero-shot el texto ambiguo?
La clasificación cero-shot puede tener dificultades con el texto ambiguo, ya que depende de la similitud semántica. Usar etiquetas candidatas más claras y contexto puede ayudar a mejorar la precisión en tales casos.
Artículos relevantes sobre IA y tendencias tecnológicas
Mantente al día con las últimas ideas, herramientas e innovaciones que dan forma al futuro de la IA y la tecnología.
Grok AI: Generación Ilimitada de Videos Gratuita a partir de Texto e Imágenes | Guía 2024
Grok AI ofrece generación ilimitada de videos gratuita a partir de texto e imágenes, haciendo accesible la creación de videos profesionales para todos sin necesidad de habilidades de edición.
Configuración de Grok 4 Fast en Janitor AI: Guía Completa de Juego de Roles Sin Filtros
Guía paso a paso para configurar Grok 4 Fast en Janitor AI para juego de roles sin restricciones, incluyendo configuración de API, ajustes de privacidad y consejos de optimización
Las 3 mejores extensiones gratuitas de IA para programar en VS Code 2025 - Aumenta la productividad
Descubre las mejores extensiones gratuitas de agentes de IA para programar en Visual Studio Code en 2025, incluyendo Gemini Code Assist, Tabnine y Cline, para mejorar tu