Annotation
- Introducción
- Comprensión de los Fundamentos del Aprendizaje Zero-Shot
- Incrustaciones Latentes: La Base Técnica
- Modelos TARS: Clasificación Zero-Shot Avanzada
- Ingeniería de Prompts para un Rendimiento Óptimo
- Soluciones de Código Abierto e Implementación
- Aplicaciones Prácticas Empresariales
- Ventajas y Desventajas
- Conclusión
- Preguntas frecuentes
Aprendizaje de cero disparos: Clasificación de texto sin datos de entrenamiento etiquetados
El aprendizaje de cero disparos permite a la IA clasificar texto en categorías no vistas sin datos etiquetados, utilizando incrustaciones semánticas y transferencia de conocimiento para

Introducción
En el campo en rápido avance del Procesamiento del Lenguaje Natural, el aprendizaje zero-shot representa un cambio revolucionario en cómo las máquinas entienden y categorizan texto. Este enfoque innovador permite a los modelos de IA clasificar documentos, sentimientos y temas sin requerir extensos conjuntos de datos de entrenamiento etiquetados, una limitación que tradicionalmente ha restringido las aplicaciones de aprendizaje automático. Al aprovechar la comprensión semántica y la transferencia de conocimiento, el aprendizaje zero-shot abre nuevas posibilidades para organizaciones que manejan contenido dinámico y necesidades de clasificación en evolución en varios chatbots de IA y plataformas de automatización.
Comprensión de los Fundamentos del Aprendizaje Zero-Shot
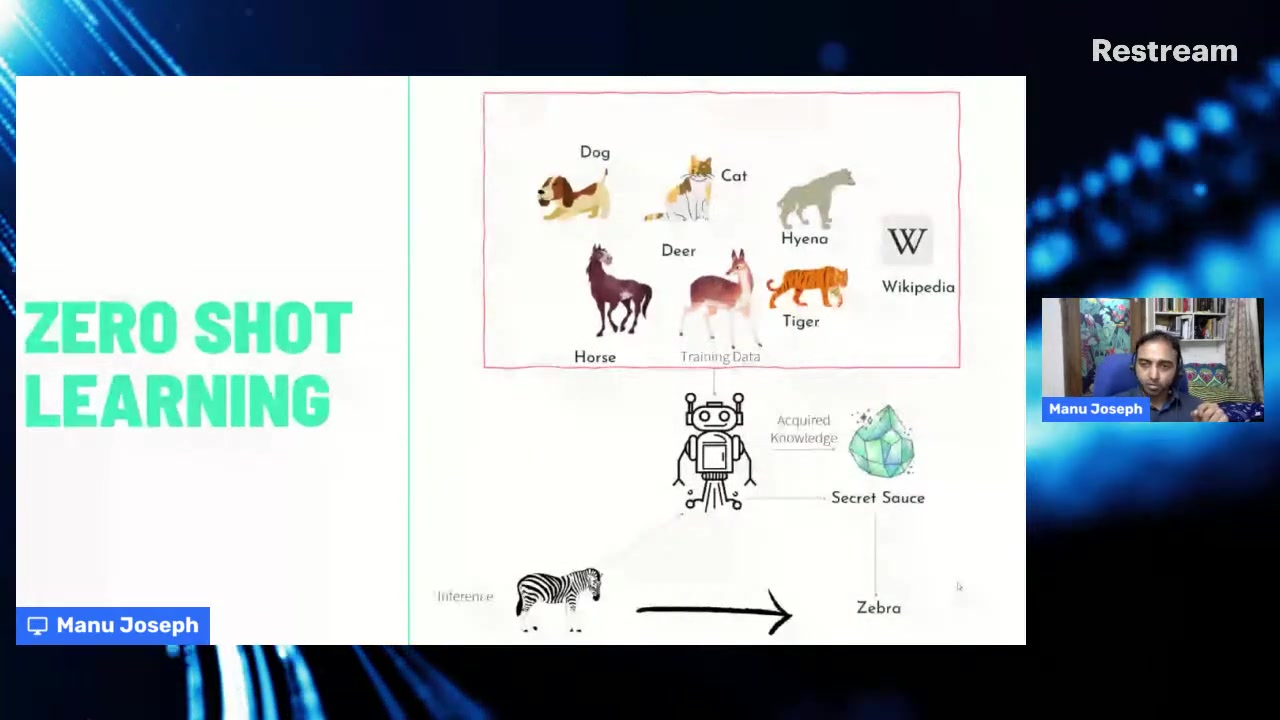
El aprendizaje zero-shot representa un cambio de paradigma respecto a los métodos tradicionales de aprendizaje supervisado. Mientras que los enfoques convencionales requieren ejemplos etiquetados sustanciales para cada categoría de clasificación, el aprendizaje zero-shot permite a los modelos categorizar texto en clases que nunca han encontrado durante el entrenamiento. Esta capacidad surge de la habilidad del modelo para entender relaciones semánticas y transferir conocimiento de dominios relacionados.
El mecanismo central implica proyectar tanto las entradas de texto como las etiquetas de categoría en un espacio semántico compartido donde sus relaciones pueden medirse mediante métricas de similitud. Este enfoque imita el razonamiento humano: a menudo podemos categorizar nuevos conceptos basándonos en nuestra comprensión de ideas relacionadas sin necesidad de ejemplos explícitos.
Incrustaciones Latentes: La Base Técnica
Las incrustaciones latentes forman la base técnica de los sistemas efectivos de clasificación zero-shot. Estas incrustaciones crean un espacio multidimensional donde tanto el contenido de texto como las etiquetas de categoría pueden representarse numéricamente, permitiendo cálculos precisos de similitud. Modelos avanzados como Sentence-BERT (S-BERT) sobresalen en generar estas incrustaciones al capturar significados semánticos matizados más allá de la simple coincidencia de palabras clave.
El proceso de incrustación generalmente sigue estos pasos:
- Codificación de Texto: El texto de entrada se procesa a través de un codificador basado en transformadores para crear una representación vectorial densa.
- Representación de Etiquetas: Las etiquetas de categoría se codifican de manera similar utilizando la misma arquitectura de modelo.
- Evaluación de Similitud: La similitud coseno u otras métricas calculan la alineación entre el texto y las etiquetas.
- Decisión de Clasificación: El sistema asigna el texto a la categoría con la puntuación de similitud más alta.
Esta metodología resulta valiosa para herramientas de escritura con IA que necesitan categorizar diversos tipos de contenido sin reentrenamiento constante.
Modelos TARS: Clasificación Zero-Shot Avanzada
Los modelos de Representación de Oraciones Conscientes del Texto (TARS) representan un avance significativo en las capacidades de aprendizaje zero-shot. Estas arquitecturas especializadas se basan en modelos fundamentales como BERT pero incorporan mecanismos adicionales para manejar tareas de clasificación sin entrenamiento específico de tarea. Los modelos TARS demuestran flexibilidad al adaptarse a nuevos esquemas de categorización mientras mantienen un rendimiento robusto.
La fortaleza de TARS radica en su capacidad para entender relaciones contextuales entre el texto y las etiquetas potenciales. Este enfoque matizado permite una categorización más precisa, especialmente para tareas complejas. La implementación implica modelos preentrenados aplicados a nuevos dominios con ajustes mínimos, ideal para un despliegue rápido. Esto se alinea bien con las modernas herramientas de IA conversacional que requieren una comprensión dinámica del contenido.
Ingeniería de Prompts para un Rendimiento Óptimo
La ingeniería efectiva de prompts juega un papel crucial en maximizar el rendimiento del aprendizaje zero-shot. Dado que los modelos dependen de representaciones de etiquetas, cómo se redactan las etiquetas impacta la precisión. Los prompts bien elaborados proporcionan contexto para entender los límites de las categorías.
Las mejores prácticas incluyen usar nombres de etiquetas descriptivos y no ambiguos. Para el análisis de sentimientos, prompts como "texto que expresa satisfacción" y "texto que expresa crítica" producen mejores resultados. Las técnicas avanzadas utilizan múltiples variaciones de prompts y métodos de conjunto para mejorar la confiabilidad, valioso para APIs y SDKs de IA donde el rendimiento consistente es crítico.
Soluciones de Código Abierto e Implementación
El ecosistema de aprendizaje zero-shot se beneficia de implementaciones robustas de código abierto. Bibliotecas como Transformers de Hugging Face proporcionan modelos preentrenados para tareas zero-shot, mientras que marcos como SetFit ofrecen capacidades eficientes con necesidades computacionales mínimas.
Estas soluciones incluyen modelos preconfigurados, APIs estandarizadas, documentación y actualizaciones. Para desarrolladores que trabajan con plataformas de automatización con IA, estas reducen las barreras de implementación y proporcionan una base sólida para la personalización.
Aplicaciones Prácticas Empresariales
El aprendizaje zero-shot ofrece valor en escenarios donde la clasificación tradicional es impracticable. El servicio al cliente categoriza tickets de soporte en nuevos problemas sin reentrenamiento. El marketing analiza comentarios sobre nuevos productos, y el cumplimiento monitorea riesgos desconocidos.
Para agentes y asistentes de IA, las capacidades zero-shot permiten interacciones adaptativas al entender solicitudes de usuario fuera de los dominios entrenados. También ayuda en la moderación de contenido al identificar nuevo contenido inapropiado basado en similitud semántica.
Ventajas y Desventajas
Ventajas
- Elimina la necesidad de extensos conjuntos de datos de entrenamiento etiquetados
- Permite la clasificación de categorías completamente nuevas y no vistas
- Facilita la adaptación rápida a requisitos empresariales cambiantes
- Reduce el tiempo de preparación de datos y los costos asociados
- Admite la transferencia de conocimiento entre dominios relacionados
Desventajas
- Puede lograr una precisión menor que el aprendizaje supervisado con datos suficientes
- El rendimiento depende en gran medida de la calidad de las incrustaciones y el diseño de prompts
- Puede tener dificultades con categorías de dominio altamente especializadas o técnicas
Conclusión
El aprendizaje zero-shot representa un salto significativo en hacer la clasificación de texto más accesible y eficiente. Al reducir la dependencia de conjuntos de datos etiquetados, abre el aprendizaje automático a organizaciones con necesidades dinámicas. Aunque no reemplaza completamente el aprendizaje supervisado, ofrece una alternativa poderosa para flexibilidad y adaptación rápida, especialmente en aplicaciones que involucran editores de texto y sistemas de gestión de contenido.
Preguntas frecuentes
¿Qué es el aprendizaje de cero disparos en términos simples?
El aprendizaje de cero disparos permite a los modelos de IA categorizar texto en clases que nunca han visto durante el entrenamiento al comprender las relaciones semánticas en lugar de depender de ejemplos etiquetados para cada categoría específica.
¿En qué se diferencia el aprendizaje de cero disparos de la clasificación tradicional?
La clasificación tradicional requiere datos etiquetados extensos para cada categoría, mientras que el aprendizaje de cero disparos utiliza la comprensión semántica para clasificar categorías no vistas sin ejemplos de entrenamiento específicos.
¿Cuáles son los principales beneficios comerciales del aprendizaje de cero disparos?
Los beneficios clave incluyen costos reducidos de etiquetado de datos, adaptación más rápida a nuevas categorías, manejo de necesidades de clasificación dinámica y permitir la clasificación cuando los datos etiquetados son escasos.
¿Qué industrias se benefician más de la clasificación de texto de cero disparos?
Servicio al cliente, moderación de contenido, investigación de mercado, monitoreo de cumplimiento y cualquier campo con categorías en evolución o temas emergentes donde etiquetar datos es desafiante.
¿Cuáles son las limitaciones del aprendizaje de cero disparos?
Las limitaciones incluyen una precisión potencialmente menor en comparación con el aprendizaje supervisado, dependencia de la calidad de las incrustaciones y el diseño de prompts, y desafíos con contenido ambiguo o altamente técnico.
Artículos relevantes sobre IA y tendencias tecnológicas
Mantente al día con las últimas ideas, herramientas e innovaciones que dan forma al futuro de la IA y la tecnología.
Grok AI: Generación Ilimitada de Videos Gratuita a partir de Texto e Imágenes | Guía 2024
Grok AI ofrece generación ilimitada de videos gratuita a partir de texto e imágenes, haciendo accesible la creación de videos profesionales para todos sin necesidad de habilidades de edición.
Configuración de Grok 4 Fast en Janitor AI: Guía Completa de Juego de Roles Sin Filtros
Guía paso a paso para configurar Grok 4 Fast en Janitor AI para juego de roles sin restricciones, incluyendo configuración de API, ajustes de privacidad y consejos de optimización
Las 3 mejores extensiones gratuitas de IA para programar en VS Code 2025 - Aumenta la productividad
Descubre las mejores extensiones gratuitas de agentes de IA para programar en Visual Studio Code en 2025, incluyendo Gemini Code Assist, Tabnine y Cline, para mejorar tu