Annotation
- Introducción
- Comprendiendo los Servicios de Transcripción de Audio
- Componentes Principales de la Infraestructura
- Interfaz del Sitio Web y Experiencia de Usuario
- Arquitectura de Producción y Flujo de Trabajo
- Estructura del Código Base y Repositorio GitHub
- Desafíos de Desarrollo en el Mundo Real
- Containerización y Mejoras Futuras
- Diseño de Base de Datos y Seguimiento de Trabajos
- Pros y Contras
- Conclusión
- Preguntas frecuentes
Construir Servicio de Transcripción de Audio: Guía de Kubernetes y RabbitMQ
Aprende a construir un servicio de transcripción de audio escalable con Kubernetes y RabbitMQ. Esta guía cubre arquitectura, flujo de trabajo e implementación

Introducción
Construir un servicio de transcripción de audio requiere una planificación cuidadosa en infraestructura, flujos de trabajo de procesamiento y experiencia de usuario. Esta guía completa recorre la creación de Phonic Tonic – un prototipo funcional que demuestra cómo convertir voz a texto a escala. Exploraremos la pila técnica completa desde la orquestación de contenedores hasta la cola de mensajes, proporcionando ideas prácticas para desarrolladores que construyen servicios similares.
Comprendiendo los Servicios de Transcripción de Audio
La conversión de audio a texto se ha vuelto esencial en múltiples industrias, incluyendo producción de medios, investigación académica, documentación legal y comunicaciones empresariales. Los servicios de transcripción modernos aprovechan algoritmos avanzados de reconocimiento de voz para entregar salidas de texto precisas desde varios formatos de audio. La creciente demanda surge de los requisitos mejorados de accesibilidad, la capacidad mejorada de búsqueda de contenido y las capacidades eficientes de análisis de datos. Para los desarrolladores, construir tales servicios presenta desafíos únicos en torno a la escalabilidad, la precisión y la optimización de costos.
Phonic Tonic sirve como un prototipo educativo que demuestra los desafíos de implementación del mundo real en lugar de presentar código empresarial pulido. Este enfoque proporciona ideas valiosas sobre los aspectos prácticos del desarrollo, incluyendo decisiones de infraestructura, diseño de flujos de trabajo y consideraciones operativas que muchos tutoriales pasan por alto.
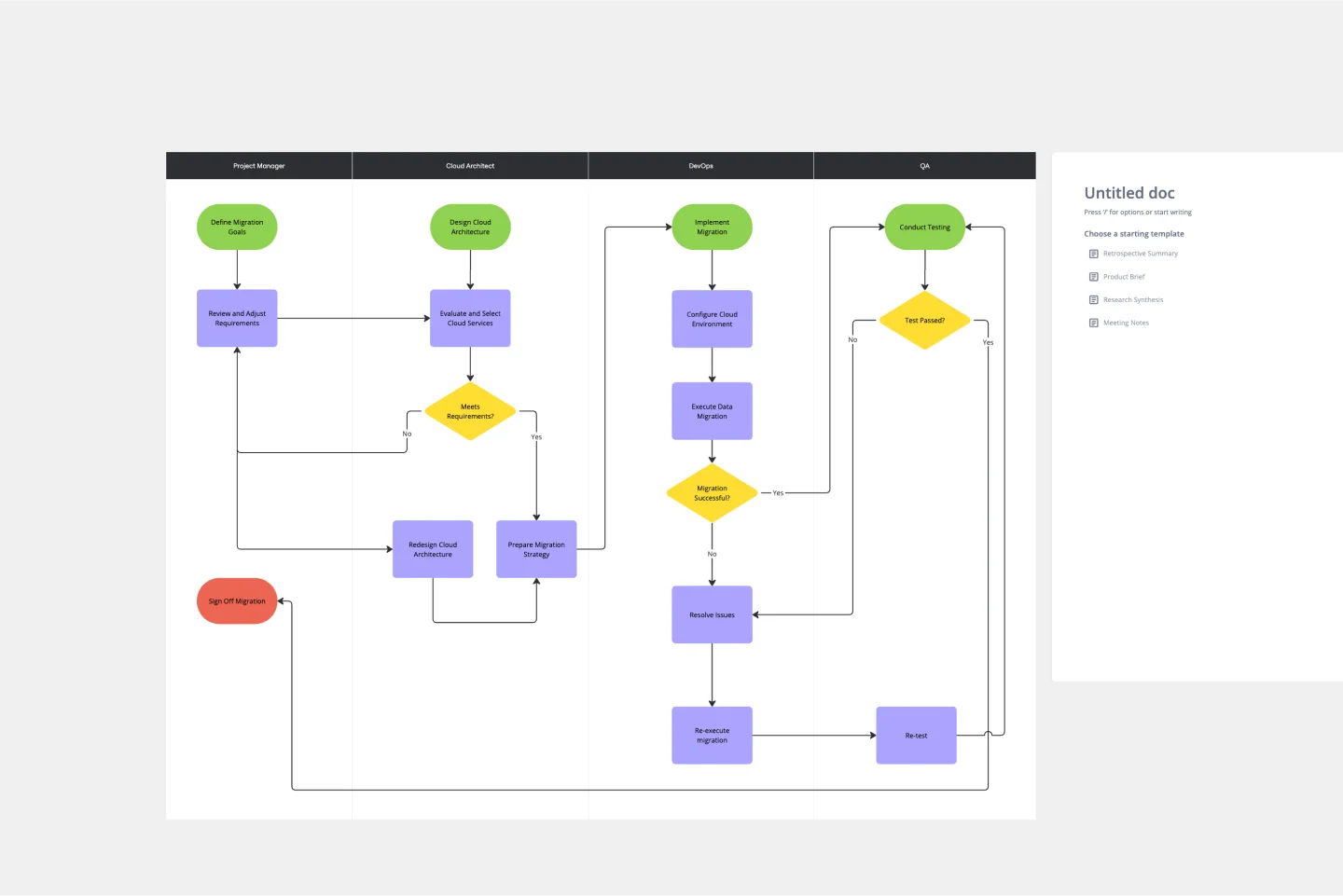
Componentes Principales de la Infraestructura
La base de cualquier servicio de transcripción confiable reside en su arquitectura de infraestructura. Phonic Tonic emplea un enfoque de microservicios utilizando varias tecnologías clave que trabajan juntas sin problemas. Kubernetes maneja la orquestación de contenedores, asegurando que diferentes componentes puedan escalar independientemente según las demandas de carga de trabajo. Esto es particularmente importante para manejar volúmenes variables de solicitudes de transcripción a lo largo del día.
La cola de mensajes con RabbitMQ permite el procesamiento asíncrono, previniendo la sobrecarga del sistema durante períodos de uso máximo. Cuando los usuarios cargan múltiples archivos de audio grandes simultáneamente, la cola gestiona la distribución de la carga de trabajo entre los trabajadores disponibles. Las soluciones de almacenamiento en la nube como Google Cloud Storage proporcionan almacenamiento de archivos duradero y escalable tanto para los archivos de audio originales como para las transcripciones generadas, mientras que las bases de datos MySQL rastrean el estado del trabajo y la información del usuario a lo largo de la tubería de procesamiento.
Interfaz del Sitio Web y Experiencia de Usuario
El componente orientado al usuario de Phonic Tonic se centra en la simplicidad y la funcionalidad. Los usuarios interactúan con una interfaz web limpia donde pueden cargar archivos de audio en formatos comunes como MP3, WAV y M4A. El sistema incluye validación integral de archivos para asegurar que el contenido cargado cumple con los requisitos de procesamiento antes de entrar en la cola de transcripción. La recolección de correo electrónico permite la entrega de notificaciones una vez que la transcripción se completa, creando una experiencia de usuario sin problemas sin requerir la creación de una cuenta.
Detrás de escena, el sitio web maneja el procesamiento inicial de archivos y se coordina con los servicios backend a través de APIs bien definidas. Esta separación de preocupaciones permite que el desarrollo frontend y backend proceda independientemente mientras mantiene la confiabilidad del sistema. El diseño de la interfaz prioriza la claridad y la facilidad de uso, reconociendo que muchos usuarios pueden no tener antecedentes técnicos pero aún requieren servicios de transcripción precisos.
Arquitectura de Producción y Flujo de Trabajo
El flujo de trabajo de transcripción sigue una secuencia cuidadosamente orquestada desde la carga del archivo hasta la entrega del texto. Cuando un usuario envía un archivo de audio, el sistema primero valida el formato y lo almacena en el almacenamiento en la nube. Un registro de base de datos crea una entrada de trabajo con identificador único e información de contacto del usuario. El sistema luego coloca una solicitud de transcripción en la cola de mensajes, donde los trabajadores disponibles pueden reclamar tareas según la capacidad actual.
Este enfoque distribuido previene puntos únicos de falla y permite escalado horizontal durante períodos de alta demanda. La arquitectura separa la transcodificación (conversión de formato) del reconocimiento de voz real, permitiendo optimización especializada para cada tarea. Las transcripciones completadas activan notificaciones por correo electrónico a los usuarios con enlaces de descarga, mientras que el sistema mantiene trazas de auditoría para fines de solución de problemas y análisis.
Estructura del Código Base y Repositorio GitHub
El código base de Phonic Tonic, disponible públicamente en GitHub, demuestra patrones de implementación práctica para proyectos similares. El repositorio contiene configuraciones de Docker para despliegue containerizado, archivos YAML de Kubernetes para orquestación, y código fuente para todos los componentes principales. El servicio web maneja las interacciones del usuario y el procesamiento inicial, mientras que trabajadores especializados gestionan tareas específicas como transcodificación de audio, reconocimiento de voz y notificaciones por correo electrónico.
Cada componente sigue principios de diseño modular, haciendo el sistema más fácil de mantener y extender. El trabajador de transcripción se integra con APIs de voz en la nube, manejando autenticación, formato de solicitud y procesamiento de respuesta. El código incluye manejo integral de errores para escenarios comunes como tiempos de espera de red, formatos de audio inválidos y limitaciones de cuota de API – consideraciones esenciales para la preparación para producción.
Desafíos de Desarrollo en el Mundo Real
Construir servicios de transcripción listos para producción implica abordar numerosos desafíos prácticos más allá de la funcionalidad básica. Phonic Tonic intencionalmente muestra compromisos comunes de inicio, incluyendo credenciales codificadas que deberían usar variables de entorno o secretos de Kubernetes en entornos de producción. El prototipo carece de sistemas integrales de monitoreo y alerta, que serían esenciales para identificar problemas de rendimiento o interrupciones del servicio en despliegue en vivo.
Las consideraciones de seguridad se extienden más allá de la gestión de credenciales para incluir validación de entrada, controles de acceso y encriptación de datos. La naturaleza educativa de este proyecto significa que estos aspectos están simplificados, pero los sistemas de producción requerirían revisiones de seguridad rigurosas y cumplimiento con regulaciones de protección de datos. La optimización del rendimiento representa otra área para mejora, particularmente en torno al manejo de archivos de audio grandes y la minimización de la latencia de transcripción.
Containerización y Mejoras Futuras
La estrategia de containerización permite un despliegue consistente a través de diferentes entornos mientras simplifica la gestión de dependencias. Las mejoras futuras se centrarían en la excelencia operativa a través de registro integral usando implementaciones de pila ELK y monitoreo de métricas con Prometheus y Grafana. Estas herramientas proporcionan visibilidad en el rendimiento del sistema y ayudan a identificar cuellos de botella antes de que impacten a los usuarios.
Los mecanismos de alerta notificarían a los administradores de problemas críticos como acumulaciones en la cola, fallos de trabajadores o límites de capacidad de almacenamiento. Las pruebas de carga validarían el comportamiento del sistema bajo cargas pico esperadas, asegurando un rendimiento confiable durante picos de uso. Estas mejoras representan la evolución de prototipo funcional a servicio listo para producción capaz de manejar tráfico real de usuarios.
Diseño de Base de Datos y Seguimiento de Trabajos
El esquema de base de datos para Phonic Tonic enfatiza simplicidad y efectividad para el seguimiento de trabajos. Dos tablas principales gestionan el flujo de trabajo central: la tabla Jobs almacena información de alto nivel incluyendo direcciones de correo electrónico de usuarios e identificadores únicos, mientras que la tabla Tasks rastrea pasos individuales de procesamiento con actualizaciones de estado, metadatos de archivos y resultados finales de transcripción. Esta separación permite un manejo flexible de tuberías de procesamiento complejas mientras mantiene la integridad de los datos.
El diseño soporta trazas de auditoría y solución de problemas preservando información histórica de trabajos y líneas de tiempo de procesamiento. Las mejoras futuras podrían incluir tablas adicionales para gestión de usuarios, información de facturación y datos de análisis, pero la implementación actual se centra en los requisitos esenciales para un producto mínimo viable.
Pros y Contras
Ventajas
- Arquitectura escalable utilizando la orquestación de contenedores de Kubernetes
- El procesamiento asíncrono previene la sobrecarga del sistema durante picos
- El diseño modular permite el desarrollo independiente de componentes
- El almacenamiento en la nube proporciona gestión de archivos duradera y rentable
- El código base de código abierto facilita el aprendizaje y la personalización
- Manejo integral de errores para escenarios de falla comunes
- Interfaz de usuario simple reduce las barreras para la adopción
Desventajas
- Las credenciales codificadas presentan riesgos de seguridad significativos
- Falta de monitoreo y alerta para entornos de producción
- Datos limitados de pruebas de carga para validación de rendimiento
- Registro insuficiente para una solución de problemas efectiva
- Autenticación básica sin soporte multi-usuario
Conclusión
Construir un servicio de transcripción de audio como Phonic Tonic demuestra la intersección de las prácticas modernas de desarrollo y los requisitos prácticos de negocio. Mientras que el prototipo muestra una implementación funcional, el despliegue en producción requeriría abordar consideraciones de seguridad, monitoreo y escalabilidad. La arquitectura modular proporciona una base sólida para extensión, ya sea añadiendo soporte para idiomas adicionales, implementando transcripción en tiempo real o integrando con sistemas de gestión de contenido. Para desarrolladores embarcándose en proyectos similares, esta guía ofrece tanto patrones técnicos como ideas valiosas sobre las realidades de llevar servicios de transcripción desde el concepto hasta el estado operativo.
Preguntas frecuentes
¿Qué tecnologías impulsan el servicio de transcripción Phonic Tonic?
Phonic Tonic utiliza Kubernetes para la orquestación de contenedores, RabbitMQ para la cola de mensajes, Google Cloud Storage para la gestión de archivos y MySQL para el seguimiento de trabajos, creando una arquitectura de microservicios escalable.
¿Está el código de Phonic Tonic listo para producción?
No, es un prototipo educativo que requiere mejoras de seguridad, sistemas de monitoreo y pruebas de carga antes del despliegue en producción, pero proporciona una excelente base de aprendizaje.
¿Cómo mejora la cola de mensajes los servicios de transcripción?
RabbitMQ permite el procesamiento asíncrono, evitando la sobrecarga del sistema durante el uso máximo al distribuir las cargas de trabajo entre los trabajadores disponibles y garantizando la persistencia del trabajo hasta su finalización.
¿Cuáles son las consideraciones clave de seguridad para los servicios de transcripción?
Las medidas de seguridad esenciales incluyen usar variables de entorno para credenciales, implementar controles de acceso adecuados, cifrar datos sensibles y realizar auditorías de seguridad periódicas.
¿Qué formatos de audio son compatibles con Phonic Tonic?
Phonic Tonic admite formatos de audio comunes, incluidos MP3, WAV y M4A, con validación incorporada para garantizar la compatibilidad de archivos antes del procesamiento.
Artículos relevantes sobre IA y tendencias tecnológicas
Mantente al día con las últimas ideas, herramientas e innovaciones que dan forma al futuro de la IA y la tecnología.
Grok AI: Generación Ilimitada de Videos Gratuita a partir de Texto e Imágenes | Guía 2024
Grok AI ofrece generación ilimitada de videos gratuita a partir de texto e imágenes, haciendo accesible la creación de videos profesionales para todos sin necesidad de habilidades de edición.
Las 3 mejores extensiones gratuitas de IA para programar en VS Code 2025 - Aumenta la productividad
Descubre las mejores extensiones gratuitas de agentes de IA para programar en Visual Studio Code en 2025, incluyendo Gemini Code Assist, Tabnine y Cline, para mejorar tu
Configuración de Grok 4 Fast en Janitor AI: Guía Completa de Juego de Roles Sin Filtros
Guía paso a paso para configurar Grok 4 Fast en Janitor AI para juego de roles sin restricciones, incluyendo configuración de API, ajustes de privacidad y consejos de optimización