Annotation
- Introducción
- Comprendiendo el Desafío de la Detección de Deepfakes
- Estrategia de Conjunto de Datos para un Entrenamiento Robusto del Modelo
- Implementación de la Arquitectura Vision Transformer
- Evaluación del Rendimiento y Análisis de Métricas
- Arquitectura de Implementación Full-Stack
- Flujo de Trabajo de Usuario de Extremo a Extremo
- Aplicaciones y Casos de Uso en el Mundo Real
- Fundamento Técnico: La Revolución del Transformer
- Pros y Contras
- Conclusión
- Preguntas frecuentes
Proyecto de Detección de Imágenes Deepfake: Guía de Implementación de Vision Transformer
Una guía completa sobre la construcción de un sistema de detección de imágenes deepfake utilizando Vision Transformers, que cubre la preparación de datos, el entrenamiento del modelo y la evaluación

Introducción
A medida que la inteligencia artificial continúa avanzando, la capacidad de distinguir entre contenido visual auténtico y manipulado se ha vuelto cada vez más crítica. Esta guía completa explora un proyecto completo de aprendizaje profundo que aprovecha la arquitectura transformadora de vanguardia para detectar imágenes deepfake con una precisión notable. Desde la preparación de datos hasta la implementación web, recorreremos cada componente de la construcción de un sistema robusto de detección de deepfakes que combina técnicas modernas de IA con estrategias de implementación práctica.
Comprendiendo el Desafío de la Detección de Deepfakes
La tecnología deepfake representa uno de los desafíos más significativos en la autenticidad de los medios digitales en la actualidad. Estas manipulaciones generadas por IA pueden variar desde alteraciones faciales sutiles hasta fabricaciones completas que son casi indistinguibles de las imágenes reales para los observadores humanos. El proyecto que estamos examinando aborda este desafío de frente implementando un sistema de detección sofisticado que analiza artefactos visuales e inconsistencias que a menudo delatan el contenido generado por IA. Este enfoque es particularmente relevante para profesionales que trabajan con generadores de imágenes IA que necesitan verificar la autenticidad del contenido.
Estrategia de Conjunto de Datos para un Entrenamiento Robusto del Modelo
La base de cualquier modelo de aprendizaje profundo efectivo reside en sus datos de entrenamiento. Para este proyecto de detección de deepfakes, el conjunto de datos fue meticulosamente curado para incluir ejemplos diversos de imágenes tanto auténticas como manipuladas en varios escenarios y niveles de calidad. Esta diversidad asegura que el modelo aprenda a reconocer deepfakes independientemente de la técnica de generación específica utilizada o del tema de la imagen.
El conjunto de datos sigue una división estructurada de tres partes que es esencial para el desarrollo adecuado del modelo:
- Datos de Entrenamiento (70%): La porción más grande expone el modelo a miles de ejemplos variados, enseñándole a reconocer los patrones sutiles y artefactos que distinguen las imágenes reales de los deepfakes en diferentes condiciones de iluminación, resoluciones y técnicas de manipulación.
- Datos de Validación (15%): Utilizados durante el entrenamiento para monitorear el rendimiento y prevenir el sobreajuste, este subconjunto ayuda a afinar los hiperparámetros y asegura que el modelo se generalice bien en lugar de memorizar los ejemplos de entrenamiento.
- Datos de Prueba (15%): Completamente retenidos hasta la evaluación final, estos datos proporcionan una evaluación imparcial de cómo el modelo se desempeñará en imágenes nunca antes vistas en escenarios del mundo real.
Implementación de la Arquitectura Vision Transformer
En el núcleo de este sistema de detección se encuentra un modelo Vision Transformer (ViT), que representa una desviación significativa de las redes neuronales convolucionales tradicionales para el análisis de imágenes. La arquitectura transformadora, desarrollada originalmente para el procesamiento del lenguaje natural, ha demostrado un rendimiento notable en tareas de visión por computadora al capturar dependencias de largo alcance y contexto global dentro de las imágenes.
El proceso de implementación dentro del entorno de Jupyter notebook sigue un enfoque sistemático:
- Configuración del Entorno: Importar bibliotecas esenciales incluyendo TensorFlow, Keras e implementaciones especializadas de transformadores, junto con herramientas de manipulación y visualización de datos.
- Construcción de la Tubería de Datos: Construir cargadores de datos eficientes que manejen el redimensionamiento de imágenes, la normalización y técnicas de aumento como rotación, volteo y ajustes de brillo para mejorar la robustez del modelo.
- Configuración del Modelo: Definir la arquitectura Vision Transformer con tamaños de parche apropiados, dimensiones de incrustación y cabezas de atención adaptadas para la tarea de detección de deepfakes.
- Aplicación de Aprendizaje por Transferencia: Aprovechar pesos preentrenados de conjuntos de datos de imágenes a gran escala y ajustar finamente el modelo específicamente para la detección de deepfakes, reduciendo significativamente el tiempo de entrenamiento y mejorando el rendimiento.
- Optimización del Entrenamiento: Implementar programación de tasa de aprendizaje, parada temprana y recorte de gradientes para asegurar una convergencia estable y eficiente del modelo.
Evaluación del Rendimiento y Análisis de Métricas
Evaluar un modelo de detección de deepfakes requiere métricas integrales que vayan más allá de la precisión simple. El proyecto implementa múltiples enfoques de evaluación para evaluar exhaustivamente el rendimiento del modelo e identificar posibles debilidades.
El análisis de la matriz de confusión revela información crítica sobre el comportamiento del modelo:
| Predicho Real | Predicho Falso | |
|---|---|---|
| Verdadero Real | 37,831 | 249 |
| Verdadero Falso | 326 | 37,755 |
Esta matriz demuestra un excelente rendimiento con mínimos falsos positivos y falsos negativos. El modelo logra aproximadamente un 99.2% de precisión, con métricas de precisión y recuperación ambas superando el 99% en ambas clases. Estos resultados indican un modelo bien equilibrado que se desempeña consistentemente independientemente de si está detectando imágenes reales o falsas.
Arquitectura de Implementación Full-Stack
Para hacer las capacidades de detección de deepfakes accesibles para los usuarios finales, el proyecto implementa una aplicación web completa con componentes separados de frontend y backend. Esta arquitectura sigue las prácticas modernas de desarrollo web mientras asegura un servicio eficiente del modelo y una experiencia de usuario responsiva.
La pila de implementación incluye:
- API Backend (Flask): Un framework web ligero de Python que aloja el modelo entrenado y proporciona endpoints RESTful para el procesamiento de imágenes y predicción. El backend maneja el preprocesamiento de imágenes, la inferencia del modelo y el formateo de resultados, haciéndolo compatible con varias APIs y SDKs de IA.
- Interfaz Frontend: Una aplicación web responsiva construida con HTML, CSS y JavaScript que proporciona una interfaz intuitiva de arrastrar y soltar para la carga de imágenes, indicadores de procesamiento en tiempo real y una presentación clara de resultados.
- Optimización del Servicio del Modelo: Implementación de mecanismos de caché, colas de solicitudes y aceleración por GPU para asegurar tiempos de respuesta rápidos incluso bajo carga pesada, similar a las capacidades encontradas en plataformas profesionales de alojamiento de modelos de IA.
Flujo de Trabajo de Usuario de Extremo a Extremo
El sistema completo opera a través de un flujo de trabajo optimizado que equilibra la conveniencia del usuario con la robustez técnica:
- Envío de Imagen: Los usuarios cargan imágenes a través de la interfaz web, con soporte para formatos comunes (JPEG, PNG) y validación automática para el tamaño del archivo y dimensiones.
- Procesamiento Backend: La API de Flask recibe la imagen, aplica el preprocesamiento necesario (redimensionamiento, normalización) y ejecuta la tubería de inferencia del modelo.
- Análisis en Tiempo Real: El Vision Transformer procesa la imagen, analizando las relaciones espaciales y patrones de textura para identificar artefactos de manipulación que son característicos de las técnicas de generación de deepfakes.
- Puntuación de Confianza: El modelo genera tanto una clasificación (real/falso) como una puntuación de confianza que indica la certeza de la predicción, ayudando a los usuarios a entender la confiabilidad de cada resultado.
- Entrega de Resultados: El frontend muestra el resultado del análisis con indicadores visuales y texto explicativo, haciendo los resultados técnicos accesibles para usuarios no expertos.
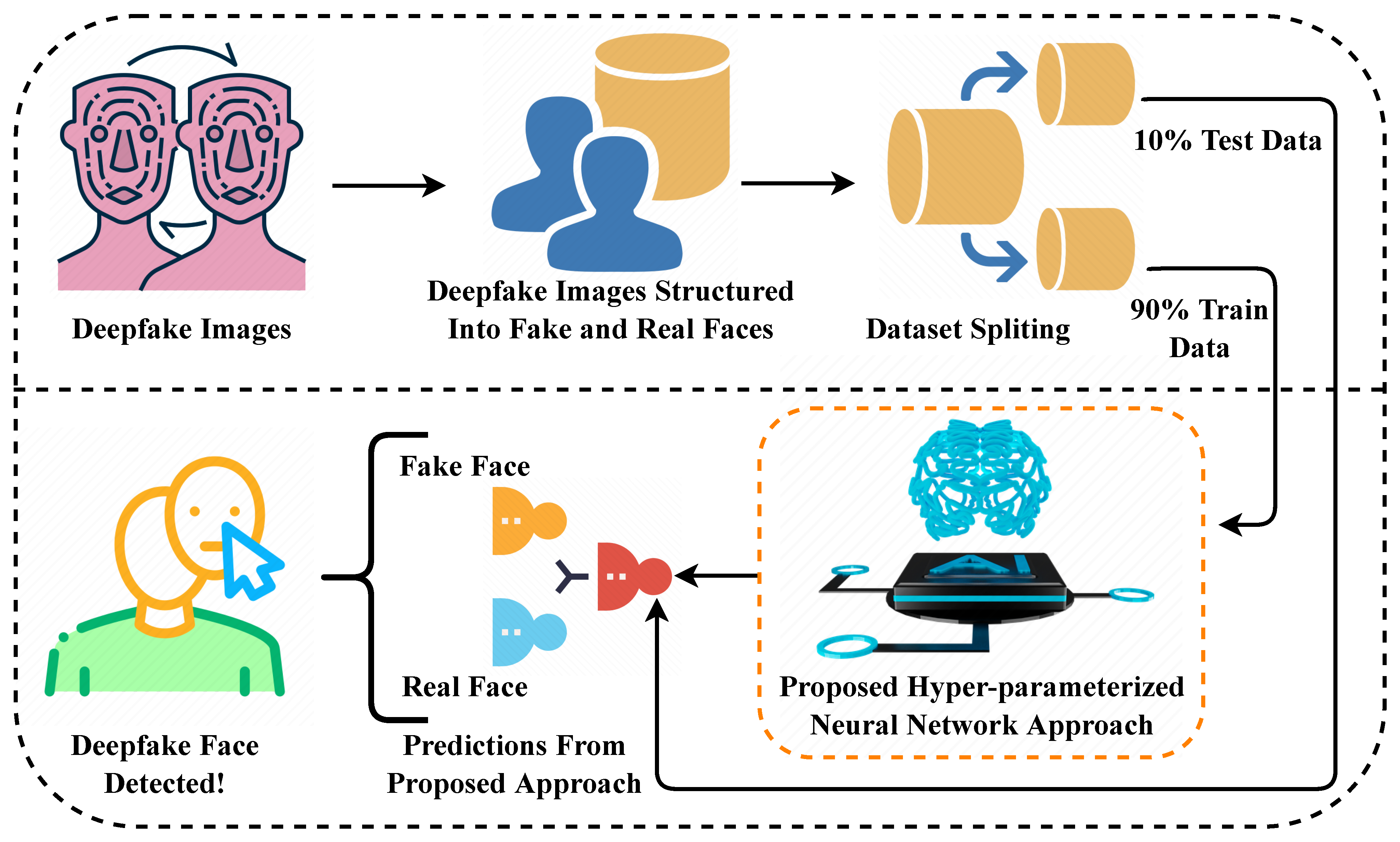
Aplicaciones y Casos de Uso en el Mundo Real
Las aplicaciones prácticas de una detección robusta de deepfakes se extienden a través de múltiples dominios donde la autenticidad visual es primordial. Las organizaciones de noticias pueden integrar tales sistemas para verificar el contenido enviado por usuarios antes de la publicación, mientras que las plataformas de redes sociales podrían desplegar tecnología similar para marcar automáticamente imágenes potencialmente manipuladas. Los profesionales legales y forenses se benefician de herramientas que proporcionan análisis preliminar de la autenticidad de la evidencia, aunque la revisión de expertos humanos sigue siendo esencial para casos críticos. La tecnología también complementa las herramientas existentes de editor de fotos al agregar capacidades de verificación.
En entornos corporativos, la detección de deepfakes ayuda a proteger contra ataques sofisticados de ingeniería social que utilizan imágenes manipuladas para el engaño de identidad. Las instituciones educativas pueden usar estos sistemas para enseñar alfabetización digital y habilidades de evaluación crítica de medios. La creciente integración de tecnologías similares en plataformas de automatización de IA demuestra la importancia creciente de la verificación de contenido en flujos de trabajo automatizados.
Fundamento Técnico: La Revolución del Transformer
Este proyecto se basa en el trabajo innovador presentado en el artículo de investigación "Attention Is All You Need", que introdujo la arquitectura transformadora que desde entonces ha revolucionado tanto el procesamiento del lenguaje natural como la visión por computadora. El mecanismo de auto-atención en el corazón de los transformadores permite al modelo ponderar la importancia de diferentes regiones de la imagen dinámicamente, haciéndolo particularmente efectivo para detectar los artefactos sutiles y globalmente distribuidos que caracterizan las manipulaciones deepfake.
A diferencia de las redes convolucionales tradicionales que procesan imágenes a través de filtros locales, los transformadores pueden capturar dependencias de largo alcance a través de toda la imagen simultáneamente. Esta perspectiva global es crucial para identificar inconsistencias en la iluminación, patrones de textura y proporciones anatómicas que a menudo delatan el contenido generado por IA. La escalabilidad de la arquitectura también le permite beneficiarse de conjuntos de datos más grandes y más recursos computacionales, siguiendo tendencias vistas en directorios completos de herramientas de IA que rastrean las capacidades de los modelos.
Pros y Contras
Ventajas
- Precisión de detección excepcional que supera el 99% en datos de prueba
- Implementación integral de extremo a extremo desde los datos hasta la implementación
- Arquitectura de código abierto que permite personalización y extensión
- La arquitectura Vision Transformer captura el contexto global de la imagen
- Interfaz web fácil de usar accesible para usuarios no técnicos
- Rendimiento robusto en diversos tipos y calidades de imágenes
- Tiempos de inferencia rápidos adecuados para aplicaciones en tiempo real
Desventajas
- Requisitos computacionales sustanciales para el entrenamiento
- Requiere experiencia significativa en aprendizaje automático para modificar
- Rendimiento dependiente de la calidad y diversidad de los datos de entrenamiento
- Posibles falsos positivos con imágenes altamente comprimidas
- Efectividad limitada contra técnicas de manipulación nunca antes vistas
Conclusión
Este proyecto de detección de imágenes deepfake demuestra la poderosa combinación de la arquitectura transformadora moderna con la implementación práctica full-stack. Al aprovechar Vision Transformers, el sistema logra una precisión excepcional para distinguir imágenes auténticas de manipulaciones generadas por IA mientras mantiene la accesibilidad a través de una interfaz web fácil de usar. El flujo de trabajo completo—desde la preparación de datos y el entrenamiento del modelo hasta la implementación y evaluación—proporciona un marco robusto que puede adaptarse a varios escenarios de autenticación de imágenes. A medida que la tecnología deepfake continúa evolucionando, tales sistemas de detección jugarán un papel cada vez más vital en el mantenimiento de la confianza digital y el combate de la desinformación visual a través de plataformas e industrias.
Preguntas frecuentes
¿Qué es la detección de imágenes deepfake?
La detección de imágenes deepfake utiliza inteligencia artificial para identificar imágenes manipuladas por técnicas de aprendizaje profundo, analizando artefactos visuales e inconsistencias que distinguen el contenido generado por IA de las fotografías auténticas.
¿Qué tan preciso es este detector de deepfake?
El detector basado en Vision Transformer logra una precisión superior al 99% en conjuntos de datos de prueba, con un rendimiento equilibrado en ambas clases de imágenes reales y falsas, aunque el rendimiento puede variar según la calidad de la imagen y las nuevas técnicas de manipulación.
¿Qué tecnologías impulsan este sistema de detección?
El sistema combina la arquitectura Vision Transformer para el análisis de imágenes, TensorFlow/Keras para el aprendizaje profundo, Flask para la API del backend y tecnologías web modernas para la interfaz frontal, creando una aplicación completa de pila completa.
¿Pueden los estudiantes usar este proyecto para aprender?
Sí, el proyecto es excelente para fines educativos, incluidos trabajos de curso, proyectos de investigación o proyectos de último año. El enfoque de código abierto permite a los estudiantes estudiar y modificar la implementación mientras aprenden técnicas modernas de IA.
¿Cuáles son los requisitos del sistema?
El entrenamiento requiere recursos sustanciales de GPU, pero la aplicación web implementada puede ejecutarse en servidores estándar. Para el desarrollo, se necesitan Python 3.8+, TensorFlow 2.x y bibliotecas comunes de ciencia de datos, similares a muchos entornos de desarrollo de IA.