Annotation
- Introducción
- Comprendiendo las Redes Neuronales Convolucionales para el Reconocimiento de Imágenes
- Configuración del Entorno y Herramientas Requeridas
- Librerías Esenciales de Python para el Desarrollo de CNN
- Trabajando con el Conjunto de Datos CIFAR-10
- Construyendo la Arquitectura CNN con Keras
- Compilación del Modelo y Configuración del Entrenamiento
- Pasos de Implementación Práctica
- Ventajas y Desventajas
- Conclusión
- Preguntas frecuentes
Tutorial de Reconocimiento de Imágenes con CNN: Guía de Python, Keras y TensorFlow
Aprende a construir una Red Neuronal Convolucional para reconocimiento de imágenes usando Python y Keras. Este tutorial cubre la arquitectura CNN, conjunto de datos
Introducción
Las Redes Neuronales Convolucionales han transformado la visión por computadora, permitiendo a las máquinas interpretar datos visuales con una precisión sin precedentes. Este tutorial completo te guía a través de la construcción de una CNN práctica para reconocimiento de imágenes usando Python, Keras y TensorFlow. Cubriremos todo, desde la configuración del entorno hasta la evaluación del modelo, proporcionando experiencia práctica con implementación en el mundo real. Ya sea que estés explorando tutoriales de IA o construyendo sistemas de producción, esta guía ofrece conocimiento accionable para soluciones efectivas de reconocimiento de imágenes.
Comprendiendo las Redes Neuronales Convolucionales para el Reconocimiento de Imágenes
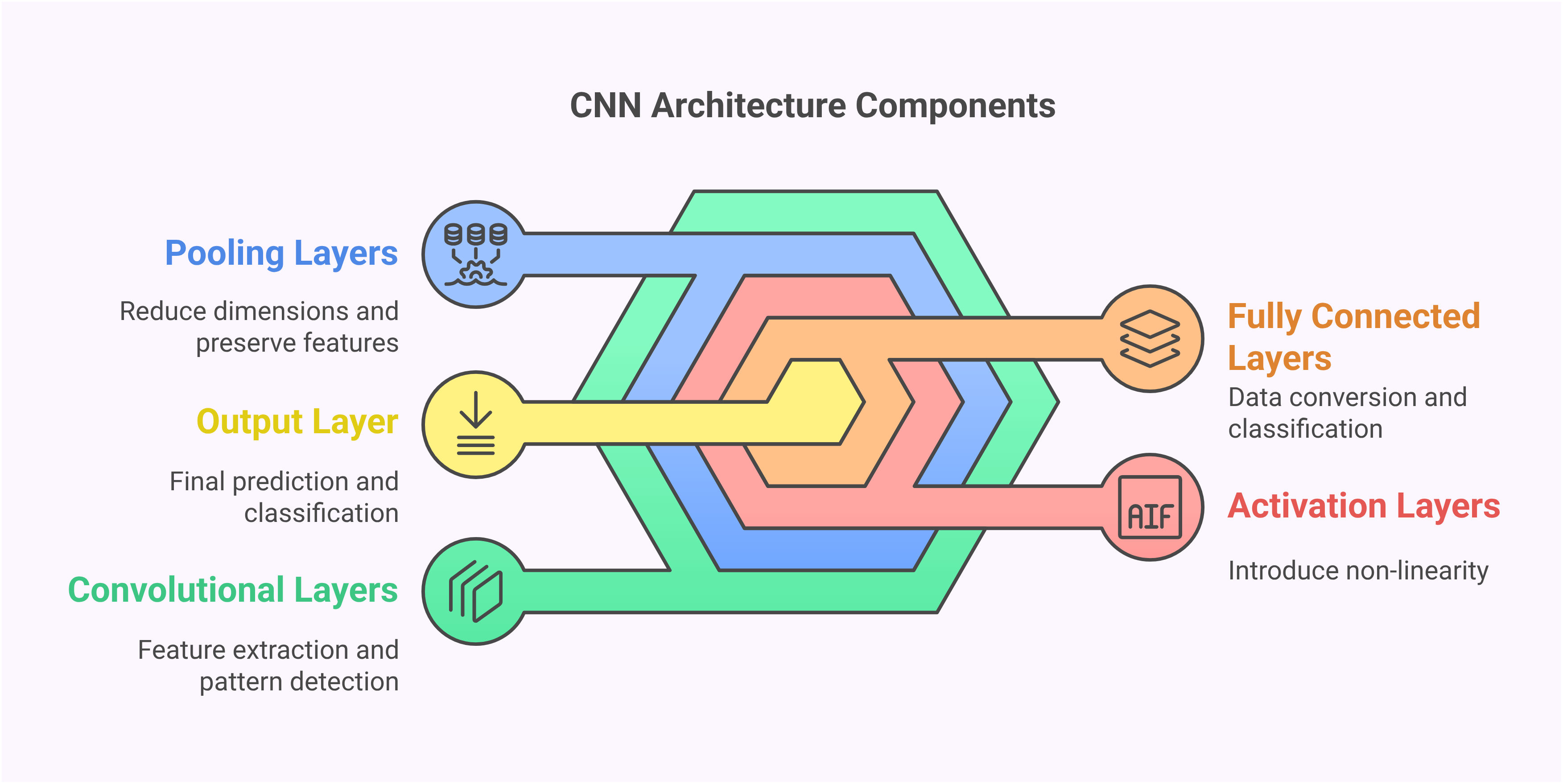
Las Redes Neuronales Convolucionales representan una arquitectura especializada diseñada específicamente para procesar datos visuales. A diferencia de las redes neuronales tradicionales que tratan los datos de entrada como vectores planos, las CNN preservan las relaciones espaciales a través de su estructura de capas única. Esta conciencia espacial les permite detectar patrones, bordes y texturas de manera que imita el procesamiento visual humano. La capacidad de extracción de características jerárquicas hace que las CNN sean particularmente efectivas para tareas visuales complejas donde el contexto y las relaciones espaciales importan.
Los bloques fundamentales de las CNN incluyen capas convolucionales que escanean imágenes con filtros para detectar características, capas de agrupación que reducen la dimensionalidad mientras preservan información importante, y capas completamente conectadas que realizan la clasificación final. Este enfoque estructurado permite a las CNN aprender automáticamente características relevantes sin ingeniería manual, haciéndolas ideales para diversas aplicaciones de reconocimiento de imágenes desde diagnósticos médicos hasta sistemas de conducción autónoma.
Configuración del Entorno y Herramientas Requeridas
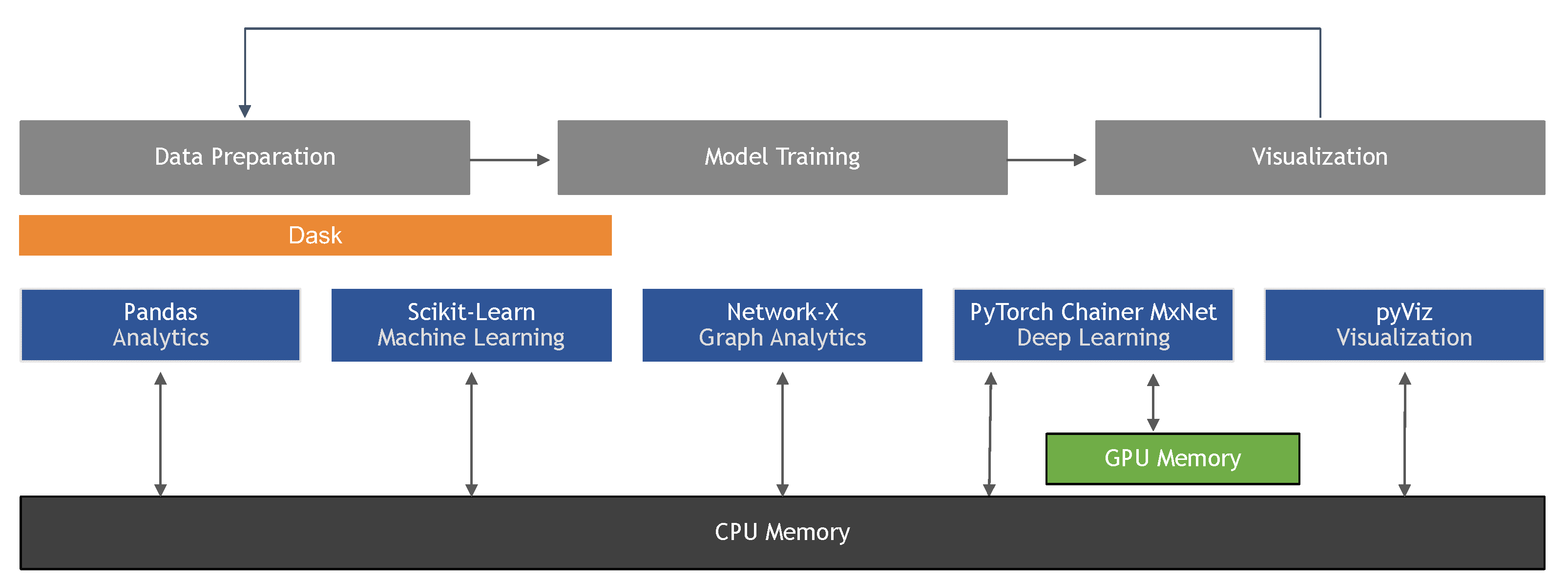
Antes de implementar tu CNN, una configuración adecuada del entorno es esencial. Este tutorial utiliza Python 3.7+ con TensorFlow 2.x y Keras como el marco principal de aprendizaje profundo. El proceso de configuración implica instalar varios paquetes clave que proporcionan la columna vertebral computacional para las operaciones de redes neuronales. Comienza creando un entorno virtual para gestionar las dependencias de manera limpia, luego instala los paquetes requeridos usando pip.
Los paquetes principales incluyen TensorFlow para cálculos de backend, Keras para APIs de alto nivel de redes neuronales, NumPy para operaciones numéricas y Matplotlib para visualización. Librerías adicionales útiles incluyen OpenCV para procesamiento avanzado de imágenes y Scikit-learn para utilidades de preprocesamiento de datos. Estas herramientas colectivamente proporcionan una base robusta para construir y experimentar con modelos de aprendizaje profundo en diferentes configuraciones de hardware.
Librerías Esenciales de Python para el Desarrollo de CNN
Importar las librerías correctas establece la base para tu sistema de reconocimiento de imágenes. Las importaciones clave incluyen NumPy para operaciones de arrays, capas de Keras para la arquitectura de red, y utilidades de conjuntos de datos para cargar datos de entrenamiento. Cada librería sirve propósitos específicos en el pipeline de CNN, desde la manipulación de datos hasta la definición y entrenamiento del modelo.
El modelo Secuencial de Keras proporciona una pila lineal de capas, mientras que Conv2D implementa operaciones convolucionales. Las capas de Dropout previenen el sobreajuste, BatchNormalization estabiliza el entrenamiento, y MaxPooling2D reduce las dimensiones espaciales. Comprender el papel de cada componente ayuda en el diseño de arquitecturas efectivas y en la resolución de problemas durante el desarrollo. Estas librerías forman el núcleo de los marcos de aprendizaje profundo modernos utilizados en entornos de producción.
Trabajando con el Conjunto de Datos CIFAR-10
El conjunto de datos CIFAR-10 sirve como un excelente punto de referencia para tareas de reconocimiento de imágenes, conteniendo 60,000 imágenes en color a través de 10 categorías que incluyen aviones, automóviles, pájaros, gatos, ciervos, perros, ranas, caballos, barcos y camiones. Cada imagen de 32x32 píxeles representa objetos del mundo real con diversas perspectivas y condiciones de iluminación, haciéndolo lo suficientemente desafiante para demostrar las capacidades de las CNN mientras sigue siendo computacionalmente manejable.
El preprocesamiento de datos implica normalizar los valores de píxeles al rango 0-1 dividiendo por 255, lo que estabiliza el entrenamiento y mejora la convergencia. La codificación one-hot transforma las etiquetas categóricas en vectores binarios, permitiendo la clasificación multiclase. Un preprocesamiento adecuado asegura que la red reciba entrada estandarizada, reduciendo el tiempo de entrenamiento y mejorando la precisión final. Este conjunto de datos proporciona experiencia práctica con técnicas de validación de modelos del mundo real.
Construyendo la Arquitectura CNN con Keras
Diseñar la arquitectura CNN implica apilar capas estratégicamente para extraer características cada vez más complejas. La arquitectura de ejemplo comienza con capas convolucionales usando filtros 3x3 y activación ReLU, seguidas de dropout y normalización por lotes para regularización. Las capas de agrupación máxima reducen las dimensiones espaciales mientras preservan características importantes, y la red culmina con capas densas para clasificación.
Las decisiones arquitectónicas clave incluyen tamaños de filtro, estrategias de agrupación y profundidad de capas. Los filtros más pequeños (3x3) capturan detalles finos mientras que los filtros más grandes reconocen patrones más amplios. El número de filtros aumenta en capas más profundas para manejar combinaciones de características más complejas. Esta complejidad progresiva permite a la red aprender representaciones jerárquicas, desde bordes simples en capas tempranas hasta partes complejas de objetos en capas más profundas. Tales arquitecturas forman la base de los sistemas de visión por computadora modernos.
Compilación del Modelo y Configuración del Entrenamiento
Compilar el modelo implica especificar la función de pérdida, el optimizador y las métricas de evaluación. Para la clasificación multiclase, la entropía cruzada categórica mide el error de predicción, mientras que el optimizador Adam adapta las tasas de aprendizaje durante el entrenamiento. Las métricas de precisión rastrean el rendimiento a lo largo del proceso de entrenamiento, proporcionando retroalimentación inmediata sobre la mejora del modelo.
Parámetros de entrenamiento como el tamaño del lote y las épocas impactan significativamente los resultados. Los lotes más pequeños proporcionan actualizaciones de pesos más frecuentes pero requieren más computación, mientras que los lotes más grandes ofrecen estabilidad pero pueden converger más lentamente. La división de validación monitorea el rendimiento de generalización, ayudando a detectar el sobreajuste temprano. Estas configuraciones equilibran la eficiencia del entrenamiento con la calidad del modelo, esencial para desarrollar aplicaciones de IA confiables.
Pasos de Implementación Práctica
La implementación sigue un flujo de trabajo estructurado que comienza con la configuración del entorno y la carga de datos. Después de importar las librerías necesarias, carga y preprocesa el conjunto de datos CIFAR-10, luego define la arquitectura CNN usando la API Secuencial de Keras. Compila el modelo con funciones de pérdida y optimizadores apropiados, luego entrena usando los datos preparados con monitoreo de validación.
La evaluación implica probar el modelo entrenado en datos no vistos y analizar las métricas de rendimiento. El enfoque paso a paso asegura la comprensión de cada componente mientras se construye hacia un sistema funcional completo. Esta metodología se aplica a diversas tareas de reconocimiento de imágenes más allá del alcance del tutorial, proporcionando habilidades transferibles para proyectos del mundo real.
Ventajas y Desventajas
Ventajas
- Aprende automáticamente características relevantes sin ingeniería manual
- Logra alta precisión en tareas complejas de reconocimiento de imágenes
- Robusto a variaciones en escala, rotación y condiciones de iluminación
- Procesamiento eficiente a través del compartimiento de parámetros en capas convolucionales
- Efectividad probada en diversas aplicaciones de visión por computadora
- Mejora continua con conjuntos de datos más grandes y mejores arquitecturas
- Capacidades de transferencia de aprendizaje para tareas visuales relacionadas
Desventajas
- Entrenamiento computacionalmente intensivo que requiere recursos significativos
- Grandes conjuntos de datos etiquetados necesarios para un rendimiento óptimo
- Susceptible al sobreajuste sin una regularización adecuada
- Sintonización compleja de hiperparámetros para resultados óptimos
- Naturaleza de caja negra que hace difícil la interpretación
Conclusión
Este tutorial demuestra la implementación práctica de Redes Neuronales Convolucionales para reconocimiento de imágenes usando Python y Keras. Desde la configuración del entorno hasta la evaluación del modelo, hemos cubierto los pasos esenciales para construir sistemas efectivos de visión por computadora. El conjunto de datos CIFAR-10 proporciona un terreno de prueba realista, mientras que la arquitectura CNN muestra técnicas modernas de aprendizaje profundo. A medida que continúas desarrollando soluciones de reconocimiento de imágenes, recuerda que las implementaciones exitosas equilibran la complejidad arquitectónica con la eficiencia computacional, y siempre validan el rendimiento con pruebas rigurosas. Las habilidades adquiridas aquí proporcionan una base sólida para abordar desafíos más avanzados de visión por computadora en aplicaciones del mundo real.
Preguntas frecuentes
¿Cuál es el número ideal de capas para una CNN?
No hay una respuesta universal: comienza con 3-5 capas convolucionales para tareas básicas, aumentando la profundidad para reconocimiento complejo. Equilibra la profundidad con las limitaciones computacionales y los riesgos de sobreajuste mediante técnicas de regularización adecuadas.
¿Cómo puedo mejorar la precisión de mi modelo CNN?
Mejora la precisión mediante aumento de datos, ajuste de hiperparámetros, optimización arquitectónica, métodos de regularización y aprendizaje por transferencia. Experimenta con diferentes optimizadores, tasas de aprendizaje y configuraciones de capas mientras monitoreas el rendimiento de validación.
¿Este tutorial funciona con otros conjuntos de datos?
Sí, la metodología se aplica a varios conjuntos de datos de imágenes. Ajusta las dimensiones de entrada, normalización y capas de salida para que coincidan con las características específicas de tus datos, manteniendo los principios fundamentales de la arquitectura CNN.
¿Cómo maneja CNN las variaciones de imagen como rotación y escala?
Las CNN utilizan capas de agrupación y aumento de datos para mantener la invariancia a pequeñas transformaciones, pero pueden requerir técnicas específicas como transformadores espaciales para grandes variaciones en rotación y escala.
¿Cuáles son los parámetros clave a ajustar en un modelo CNN?
Los parámetros importantes incluyen tamaños de filtro, número de capas, tasa de aprendizaje, tamaño de lote y técnicas de regularización como dropout para optimizar el rendimiento y prevenir el sobreajuste en tareas de reconocimiento de imágenes.
Artículos relevantes sobre IA y tendencias tecnológicas
Mantente al día con las últimas ideas, herramientas e innovaciones que dan forma al futuro de la IA y la tecnología.
Grok AI: Generación Ilimitada de Videos Gratuita a partir de Texto e Imágenes | Guía 2024
Grok AI ofrece generación ilimitada de videos gratuita a partir de texto e imágenes, haciendo accesible la creación de videos profesionales para todos sin necesidad de habilidades de edición.
Configuración de Grok 4 Fast en Janitor AI: Guía Completa de Juego de Roles Sin Filtros
Guía paso a paso para configurar Grok 4 Fast en Janitor AI para juego de roles sin restricciones, incluyendo configuración de API, ajustes de privacidad y consejos de optimización
Las 3 mejores extensiones gratuitas de IA para programar en VS Code 2025 - Aumenta la productividad
Descubre las mejores extensiones gratuitas de agentes de IA para programar en Visual Studio Code en 2025, incluyendo Gemini Code Assist, Tabnine y Cline, para mejorar tu