Annotation
- Introduction
- Comprendre les fondamentaux de l'apprentissage zero-shot
- Embarquements latents : la fondation technique
- Modèles TARS : classification zero-shot avancée
- Ingénierie des prompts pour des performances optimales
- Solutions open source et mise en œuvre
- Applications commerciales pratiques
- Avantages et inconvénients
- Conclusion
- Questions fréquemment posées
Apprentissage zéro-shot : Classification de texte sans données d'entraînement étiquetées
L'apprentissage zéro-shot permet à l'IA de classer le texte dans des catégories non vues sans données étiquetées, en utilisant des plongements sémantiques et le transfert de connaissances pour

Introduction
Dans le domaine en rapide évolution du traitement du langage naturel, l'apprentissage zero-shot représente un changement révolutionnaire dans la manière dont les machines comprennent et catégorisent le texte. Cette approche innovante permet aux modèles d'IA de classer des documents, des sentiments et des sujets sans nécessiter de vastes ensembles de données d'entraînement étiquetés – une limitation qui a traditionnellement contraint les applications d'apprentissage automatique. En tirant parti de la compréhension sémantique et du transfert de connaissances, l'apprentissage zero-shot ouvre de nouvelles possibilités pour les organisations traitant du contenu dynamique et des besoins de classification évolutifs à travers divers chatbots IA et plateformes d'automatisation.
Comprendre les fondamentaux de l'apprentissage zero-shot
L'apprentissage zero-shot représente un changement de paradigme par rapport aux méthodes d'apprentissage supervisé traditionnelles. Alors que les approches conventionnelles nécessitent des exemples étiquetés substantiels pour chaque catégorie de classification, l'apprentissage zero-shot permet aux modèles de catégoriser le texte dans des classes qu'ils n'ont jamais rencontrées pendant l'entraînement. Cette capacité découle de la capacité du modèle à comprendre les relations sémantiques et à transférer des connaissances de domaines connexes.
Le mécanisme central implique de projeter à la fois les entrées de texte et les étiquettes de catégorie dans un espace sémantique partagé où leurs relations peuvent être mesurées via des métriques de similarité. Cette approche imite le raisonnement humain – nous pouvons souvent catégoriser de nouveaux concepts basés sur notre compréhension d'idées connexes sans avoir besoin d'exemples explicites.
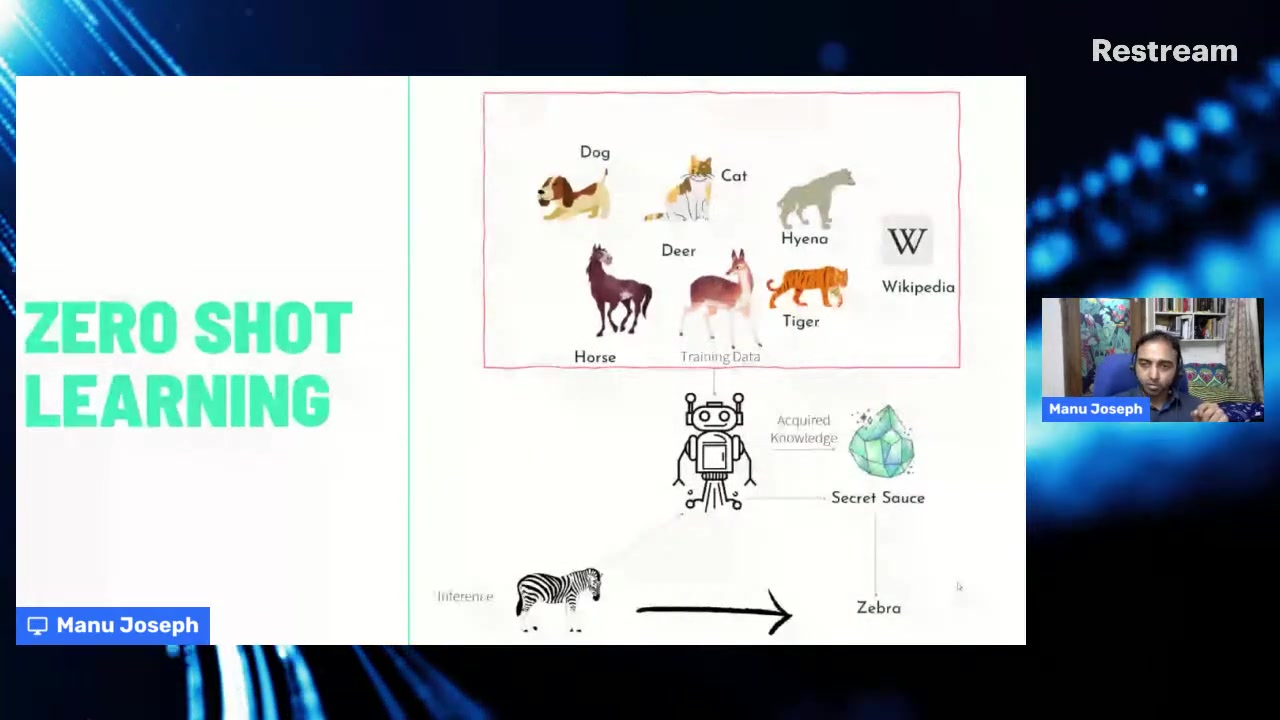
Embarquements latents : la fondation technique
Les embarquements latents forment l'épine dorsale technique des systèmes de classification zero-shot efficaces. Ces embarquements créent un espace multidimensionnel où à la fois le contenu textuel et les étiquettes de catégorie peuvent être représentés numériquement, permettant des calculs de similarité précis. Des modèles avancés comme Sentence-BERT (S-BERT) excellent à générer ces embarquements en capturant des significations sémantiques nuancées au-delà du simple appariement de mots-clés.
Le processus d'embarquement suit généralement ces étapes :
- Encodage du texte : Le texte d'entrée est traité par un encodeur basé sur des transformateurs pour créer une représentation vectorielle dense.
- Représentation des étiquettes : Les étiquettes de catégorie sont similaires encodées en utilisant la même architecture de modèle.
- Évaluation de la similarité : La similarité cosinus ou d'autres métriques calculent l'alignement entre le texte et les étiquettes.
- Décision de classification : Le système assigne le texte à la catégorie avec le score de similarité le plus élevé.
Cette méthodologie s'avère précieuse pour les outils d'écriture IA qui ont besoin de catégoriser divers types de contenu sans réentraînement constant.
Modèles TARS : classification zero-shot avancée
Les modèles de représentation de phrases conscientes du texte (TARS) représentent une avancée significative dans les capacités d'apprentissage zero-shot. Ces architectures spécialisées s'appuient sur des modèles de base comme BERT mais incorporent des mécanismes supplémentaires pour gérer les tâches de classification sans entraînement spécifique à la tâche. Les modèles TARS démontrent une flexibilité à s'adapter à de nouveaux schémas de catégorisation tout en maintenant des performances robustes.
La force de TARS réside dans sa capacité à comprendre les relations contextuelles entre le texte et les étiquettes potentielles. Cette approche nuancée permet une catégorisation plus précise, en particulier pour les tâches complexes. La mise en œuvre implique des modèles pré-entraînés appliqués à de nouveaux domaines avec un ajustement minimal, idéal pour un déploiement rapide. Cela s'aligne bien avec les outils d'IA conversationnelle modernes qui nécessitent une compréhension dynamique du contenu.
Ingénierie des prompts pour des performances optimales
Une ingénierie efficace des prompts joue un rôle crucial dans la maximisation des performances de l'apprentissage zero-shot. Étant donné que les modèles s'appuient sur les représentations d'étiquettes, la manière dont les étiquettes sont formulées impacte la précision. Des prompts bien conçus fournissent un contexte pour comprendre les limites des catégories.
Les meilleures pratiques incluent l'utilisation de noms d'étiquettes descriptifs et non ambigus. Pour l'analyse des sentiments, des prompts comme « texte exprimant la satisfaction » et « texte exprimant la critique » donnent de meilleurs résultats. Les techniques avancées utilisent plusieurs variations de prompts et des méthodes d'ensemble pour améliorer la fiabilité, précieuses pour les API et SDK IA où une performance cohérente est critique.
Solutions open source et mise en œuvre
L'écosystème de l'apprentissage zero-shot bénéficie de mises en œuvre open source robustes. Des bibliothèques comme Transformers de Hugging Face fournissent des modèles pré-entraînés pour les tâches zero-shot, tandis que des frameworks comme SetFit offrent des capacités efficaces avec des besoins computationnels minimaux.
Ces solutions incluent des modèles préconfigurés, des API standardisées, de la documentation et des mises à jour. Pour les développeurs travaillant avec des plateformes d'automatisation IA, celles-ci réduisent les barrières de mise en œuvre et fournissent une base solide pour la personnalisation.
Applications commerciales pratiques
L'apprentissage zero-shot apporte de la valeur dans des scénarios où la classification traditionnelle est impraticable. Le service client catégorise les tickets de support dans de nouveaux problèmes sans réentraînement. Le marketing analyse les retours sur de nouveaux produits, et la conformité surveille les risques inconnus.
Pour les agents et assistants IA, les capacités zero-shot permettent des interactions adaptatives en comprenant les demandes des utilisateurs en dehors des domaines entraînés. Il aide également la modération de contenu en identifiant de nouveaux contenus inappropriés basés sur la similarité sémantique.
Avantages et inconvénients
Avantages
- Élimine le besoin de vastes ensembles de données d'entraînement étiquetés
- Permet la classification de catégories complètement nouvelles et non vues
- Facilite l'adaptation rapide aux exigences commerciales changeantes
- Réduit le temps de préparation des données et les coûts associés
- Soutient le transfert de connaissances entre domaines connexes
Inconvénients
- Peut atteindre une précision inférieure à l'apprentissage supervisé avec des données suffisantes
- La performance dépend fortement de la qualité des embarquements et de la conception des prompts
- Peut avoir des difficultés avec des catégories de domaines hautement spécialisés ou techniques
Conclusion
L'apprentissage zero-shot représente un bond significatif pour rendre la classification de texte plus accessible et efficace. En réduisant la dépendance aux ensembles de données étiquetés, il ouvre l'apprentissage automatique aux organisations ayant des besoins dynamiques. Bien qu'il ne remplace pas entièrement l'apprentissage supervisé, il offre une alternative puissante pour la flexibilité et l'adaptation rapide, en particulier dans les applications impliquant des éditeurs de texte et des systèmes de gestion de contenu.
Questions fréquemment posées
Qu'est-ce que l'apprentissage zéro-shot en termes simples ?
L'apprentissage zéro-shot permet aux modèles d'IA de catégoriser le texte dans des classes qu'ils n'ont jamais vues pendant l'entraînement en comprenant les relations sémantiques plutôt qu'en s'appuyant sur des exemples étiquetés pour chaque catégorie spécifique.
En quoi l'apprentissage zéro-shot diffère-t-il de la classification traditionnelle ?
La classification traditionnelle nécessite des données étiquetées étendues pour chaque catégorie, tandis que l'apprentissage zéro-shot utilise la compréhension sémantique pour classer des catégories non vues sans exemples d'entraînement spécifiques.
Quels sont les principaux avantages commerciaux de l'apprentissage zéro-shot ?
Les avantages clés incluent la réduction des coûts d'étiquetage des données, l'adaptation plus rapide aux nouvelles catégories, la gestion des besoins de classification dynamique et la possibilité de classification lorsque les données étiquetées sont rares.
Quelles industries bénéficient le plus de la classification de texte zéro-shot ?
Service client, modération de contenu, étude de marché, surveillance de la conformité et tout domaine avec des catégories en évolution ou des sujets émergents où l'étiquetage des données est difficile.
Quelles sont les limites de l'apprentissage zéro-shot ?
Les limites incluent une précision potentiellement inférieure par rapport à l'apprentissage supervisé, la dépendance à la qualité des plongements et à la conception des prompts, et les défis avec le contenu ambigu ou hautement technique.
Articles pertinents sur l'IA et les tendances technologiques
Restez à jour avec les dernières informations, outils et innovations qui façonnent l'avenir de l'IA et de la technologie.
Grok AI : Génération Illimitée de Vidéos Gratuite à partir de Texte et d'Images | Guide 2024
Grok AI propose une génération illimitée de vidéos gratuite à partir de texte et d'images, rendant la création de vidéos professionnelles accessible à tous sans compétences en montage.
Configuration de Grok 4 Fast sur Janitor AI : Guide Complet de Jeu de Rôle Sans Filtre
Guide étape par étape pour configurer Grok 4 Fast sur Janitor AI pour un jeu de rôle sans restriction, incluant la configuration de l'API, les paramètres de confidentialité et les conseils d'optimisation
Top 3 des extensions de codage IA gratuites pour VS Code 2025 - Boostez votre productivité
Découvrez les meilleures extensions d'agents de codage IA gratuites pour Visual Studio Code en 2025, y compris Gemini Code Assist, Tabnine et Cline, pour améliorer votre