Annotation
- Introduction
- Comprendre YOLO et la détection d'objets moderne
- Configuration de l'environnement : Google Colab et développement local
- Construire des jeux de données personnalisés de haute qualité
- Annotation efficace avec Label Studio
- Entraînement du modèle dans Google Colab
- Déploiement local et mise en œuvre pratique
- Avantages et inconvénients
- Conclusion
- Questions fréquemment posées
Détection d'objets YOLOv11 : Guide complet d'entraînement 2024
Apprenez à entraîner et déployer YOLOv11 pour la détection d'objets en utilisant Google Colab et Label Studio. Ce guide couvre la création de jeux de données, l'annotation, le modèle
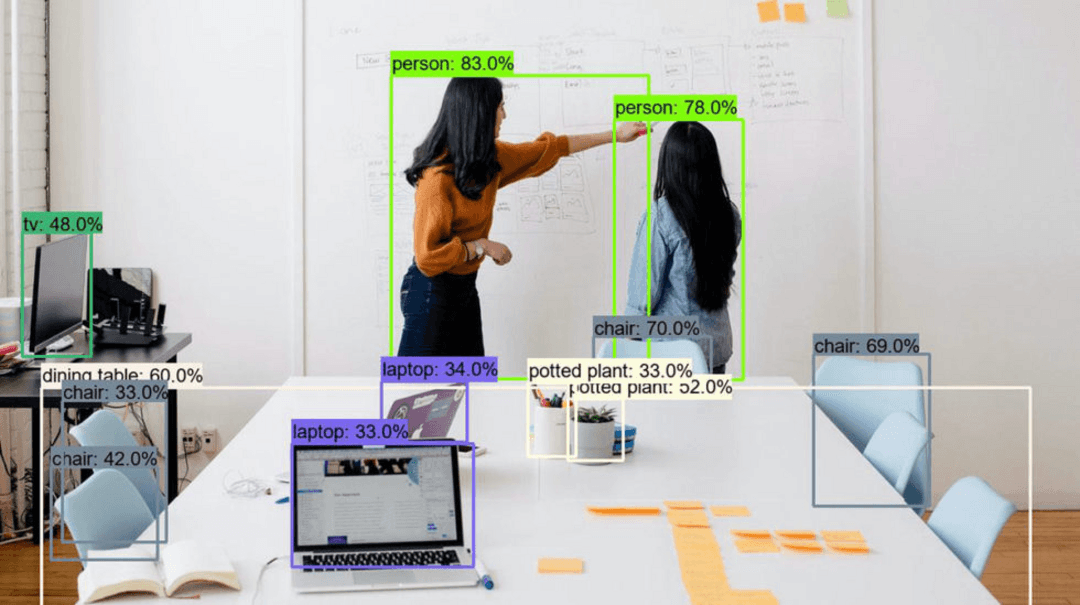
Introduction
YOLOv11 représente la pointe de la technologie en matière de détection d'objets en temps réel, s'appuyant sur l'architecture révolutionnaire You Only Look Once. Ce guide complet vous accompagne dans l'entraînement de modèles YOLO personnalisés en utilisant des outils accessibles comme Google Colab, la création de jeux de données spécialisés et le déploiement de vos modèles entraînés pour des applications pratiques. Que vous développiez des systèmes de vision par ordinateur pour les véhicules autonomes, l'analyse de la vente au détail ou des projets créatifs, ce tutoriel fournit les bases pour construire des solutions robustes de détection d'objets.
Comprendre YOLO et la détection d'objets moderne
YOLO (You Only Look Once) a transformé la vision par ordinateur en consolidant la détection d'objets en un processus en une seule étape, offrant des améliorations remarquables de vitesse par rapport aux cadres traditionnels en deux étapes. YOLOv11 poursuit cette innovation avec des raffinement architecturaux qui améliorent à la fois la précision et l'efficacité. Le modèle traite des images entières en une seule passe avant dans le réseau neuronal, prédisant simultanément les boîtes englobantes et les probabilités de classe. Cette approche rend YOLOv11 particulièrement précieux pour les applications en temps réel où la latence est importante, telles que la surveillance vidéo, la navigation autonome et les systèmes interactifs.
La détection d'objets représente une avancée significative au-delà de la simple classification d'images. Alors que la classification identifie simplement ce qui se trouve dans une image, la détection localise précisément les objets avec des boîtes englobantes et attribue des étiquettes appropriées. Cette compréhension granulaire permet des applications à travers de nombreuses plateformes d'automatisation IA, du contrôle qualité industriel à l'analyse d'imagerie médicale. La polyvalence de cette technologie la rend accessible aux développeurs travaillant avec diverses API et SDK IA pour l'intégration dans des systèmes plus larges.
Configuration de l'environnement : Google Colab et développement local
Google Colab offre un point de départ idéal pour l'entraînement de modèles YOLO, fournissant un accès gratuit aux ressources GPU qui accélèrent considérablement le processus intensif en calcul. Cette plateforme cloud élimine le besoin d'investissements matériels coûteux, rendant l'apprentissage profond accessible aux développeurs individuels et aux petites équipes. Pour commencer, assurez-vous d'avoir un compte Google actif et naviguez vers colab.research.google.com. L'interface de notebook Jupyter de la plateforme simplifie l'exécution du code et l'expérimentation.
Pour le déploiement et les tests locaux, Anaconda propose une solution robuste pour gérer les environnements Python et les dépendances. Téléchargez la distribution depuis anaconda.com et suivez l'assistant d'installation. Cette configuration fournit des environnements isolés où vous pouvez installer des versions spécifiques de packages sans conflits. Créer des environnements dédiés pour différents projets assure la reproductibilité et simplifie la gestion des dépendances à travers plusieurs scénarios d'hébergement de modèles IA et cibles de déploiement.
Construire des jeux de données personnalisés de haute qualité
La base de tout modèle de détection d'objets réussi réside dans ses données d'entraînement. Un jeu de données bien structuré et diversifié impacte directement la précision du modèle et ses capacités de généralisation. Pour les projets de preuve de concept, visez 100 à 200 images soigneusement sélectionnées qui représentent la variété des conditions que votre modèle rencontrera en production. Cela inclut différents scénarios d'éclairage, arrière-plans, orientations d'objets et occultations potentielles.
Les stratégies de collecte de données varient selon les exigences du projet. Pour des applications personnalisées comme notre exemple de détection de bonbons, capturez des images en utilisant des smartphones ou des webcams dans divers environnements. Complétez votre collection avec des jeux de données publiquement disponibles sur des plateformes comme Roboflow Universe ou Kaggle, mais vérifiez toujours la précision des étiquettes et leur pertinence pour votre cas d'utilisation spécifique. Organisez vos images dans des structures de dossiers logiques, comme un répertoire principal "yolo" avec des sous-dossiers pour différentes catégories d'objets ou sources de données.
Annotation efficace avec Label Studio
Label Studio rationalise le processus crucial d'annotation avec une interface web intuitive et des fonctionnalités d'automatisation puissantes. Cet outil open-source prend en charge divers types d'annotation, les boîtes englobantes étant essentielles pour les tâches de détection d'objets. Le processus d'installation commence par la création d'un environnement Conda dédié pour maintenir des dépendances propres : conda create --name yolo-env python=3.12 suivi de pip install label-studio.
Le flux de travail d'annotation implique de créer un nouveau projet, d'importer des images par lots (jusqu'à 100 à la fois pour éviter les limitations du serveur) et de configurer l'interface d'étiquetage pour la détection d'objets. Remplacez les étiquettes par défaut par vos noms de classe spécifiques, puis annotez systématiquement chaque image en dessinant des boîtes englobantes autour des objets cibles. Utilisez les raccourcis clavier pour l'efficacité – appuyer sur les touches numériques correspondant aux indices de classe accélère considérablement le processus. Une fois l'annotation terminée, exportez vos données au format YOLO, qui emballe les images et les fichiers d'étiquettes correspondants dans une archive téléchargeable.
Entraînement du modèle dans Google Colab
Avec les données annotées préparées, passez à Google Colab pour l'entraînement du modèle. Activez l'accélération GPU via Runtime → Changer le type d'exécution → GPU pour tirer parti des unités de traitement Tensor pour des calculs plus rapides. Le processus d'entraînement implique plusieurs paramètres configurables : l'architecture du modèle (YOLOv11s pour la vitesse vs YOLOv11 pour la précision), la résolution d'entrée (généralement 640x640 pixels) et la durée d'entraînement (époques).
Surveillez la progression de l'entraînement grâce à des métriques comme la perte, la précision, le rappel et la précision moyenne moyenne (mAP). Ces indicateurs aident à identifier quand les modèles convergent ou nécessitent des ajustements. Pour des performances sous-optimales, envisagez des stratégies comme l'augmentation des données, la planification du taux d'apprentissage ou des modifications architecturales. Le processus d'entraînement génère des poids de modèle (best.pt) et des visualisations complètes des résultats dans le répertoire de sortie, fournissant des insights pour l'amélioration itérative et l'intégration avec divers agents et assistants IA.
Déploiement local et mise en œuvre pratique
Le déploiement de modèles entraînés localement nécessite la bibliothèque Ultralytics (pip install ultralytics) et vos poids de modèle exportés. Créez des scripts Python qui chargent le modèle, traitent les images d'entrée ou les flux vidéo, et affichent les résultats de détection. Le script de déploiement doit gérer diverses sources d'entrée – images statiques, fichiers vidéo ou flux caméra en temps réel – tout en fournissant des paramètres configurables pour les seuils de confiance et le formatage de sortie.
Pour l'application de compteur de calories de bonbons, étendez la fonctionnalité de détection de base en associant les types de bonbons détectés à des informations nutritionnelles. Cela démontre comment la détection d'objets sert de fondation pour des applications plus complexes qui combinent la vision par ordinateur avec la logique métier. De telles implémentations mettent en valeur la valeur pratique de l'intégration des modèles YOLO avec des outils de capture d'écran et des utilitaires de conversion d'image pour des solutions de workflow complètes.
Avantages et inconvénients
Avantages
- Capacités de traitement en temps réel pour la vidéo et les flux en direct
- L'architecture en une seule étape offre une vitesse exceptionnelle
- Implémentation open-source avec un support communautaire actif
- Personnalisation flexible pour des types d'objets spécifiques
- Compatibilité avec diverses plateformes de déploiement
- Améliorations continues grâce aux mises à jour de version
- Documentation étendue et ressources de tutoriel
Inconvénients
- Nécessite des données étiquetées substantielles pour l'entraînement
- Intensif en calcul pendant la phase d'entraînement
- Difficultés avec les objets très petits ou qui se chevauchent
- Compromis de précision avec les variantes de modèle plus rapides
- Adaptation au domaine nécessaire pour les applications spécialisées
Conclusion
YOLOv11 démocratise la détection d'objets avancée avec des performances de pointe et des outils accessibles. Ce guide permet aux développeurs de construire des systèmes de vision personnalisés sans expertise ML étendue. La vitesse et la précision de YOLO sont indispensables pour les applications du monde réel. Maîtrisez ces techniques pour relier la théorie et la pratique en utilisant des répertoires d'outils IA pour l'innovation.
Questions fréquemment posées
Puis-je utiliser des ensembles de données préexistants pour l'entraînement YOLO ?
Oui, des plateformes comme Roboflow Universe, Kaggle et Google Open Images proposent des ensembles de données pré-étiquetés. Vérifiez toujours la qualité des données et leur pertinence pour votre cas d'utilisation spécifique avant l'entraînement.
Comment puis-je améliorer les performances du modèle YOLO ?
Améliorez les performances en vérifiant la précision des étiquettes, en augmentant les époques d'entraînement, en utilisant des architectures de modèle plus grandes, en élargissant la diversité des jeux de données et en mettant en œuvre des techniques d'augmentation des données.
Quels sont les avantages de Google Colab pour l'entraînement YOLO ?
Google Colab offre un accès gratuit au GPU, élimine les besoins en matériel local, propose des fonctionnalités collaboratives et inclut des bibliothèques d'apprentissage automatique préinstallées pour un développement rapide.
Quelles sont les améliorations clés dans YOLOv11 ?
YOLOv11 introduit une architecture améliorée pour une meilleure précision et efficacité, des techniques d'entraînement améliorées et des performances optimisées pour la détection en temps réel par rapport aux versions antérieures.
Combien de temps faut-il pour entraîner un modèle YOLOv11 ?
Le temps d'entraînement varie en fonction de la taille du jeu de données, de l'architecture du modèle et du matériel. En utilisant Google Colab avec GPU, cela peut prendre de quelques heures à une journée pour des jeux de données standard.
Articles pertinents sur l'IA et les tendances technologiques
Restez à jour avec les dernières informations, outils et innovations qui façonnent l'avenir de l'IA et de la technologie.
Grok AI : Génération Illimitée de Vidéos Gratuite à partir de Texte et d'Images | Guide 2024
Grok AI propose une génération illimitée de vidéos gratuite à partir de texte et d'images, rendant la création de vidéos professionnelles accessible à tous sans compétences en montage.
Top 3 des extensions de codage IA gratuites pour VS Code 2025 - Boostez votre productivité
Découvrez les meilleures extensions d'agents de codage IA gratuites pour Visual Studio Code en 2025, y compris Gemini Code Assist, Tabnine et Cline, pour améliorer votre
Configuration de Grok 4 Fast sur Janitor AI : Guide Complet de Jeu de Rôle Sans Filtre
Guide étape par étape pour configurer Grok 4 Fast sur Janitor AI pour un jeu de rôle sans restriction, incluant la configuration de l'API, les paramètres de confidentialité et les conseils d'optimisation