Annotation
- Introduction
- Comprendre les réseaux de neurones convolutionnels pour la reconnaissance d'images
- Configuration de l'environnement et outils requis
- Bibliothèques Python essentielles pour le développement de CNN
- Travailler avec le jeu de données CIFAR-10
- Construction de l'architecture CNN avec Keras
- Compilation du modèle et configuration de l'entraînement
- Étapes de mise en œuvre pratiques
- Avantages et inconvénients
- Conclusion
- Questions fréquemment posées
Tutoriel de Reconnaissance d'Images par CNN : Guide Python, Keras et TensorFlow
Apprenez à construire un Réseau de Neurones Convolutifs pour la reconnaissance d'images en utilisant Python et Keras. Ce tutoriel couvre l'architecture CNN, l'ensemble de données
Introduction
Les réseaux de neurones convolutionnels ont transformé la vision par ordinateur, permettant aux machines d'interpréter les données visuelles avec une précision sans précédent. Ce tutoriel complet vous guide à travers la construction d'un CNN pratique pour la reconnaissance d'images en utilisant Python, Keras et TensorFlow. Nous couvrirons tout, de la configuration de l'environnement à l'évaluation du modèle, en fournissant une expérience pratique avec une mise en œuvre réelle. Que vous exploriez tutoriels d'IA ou que vous construisiez des systèmes de production, ce guide fournit des connaissances actionnables pour des solutions efficaces de reconnaissance d'images.
Comprendre les réseaux de neurones convolutionnels pour la reconnaissance d'images
Les réseaux de neurones convolutionnels représentent une architecture spécialisée conçue spécifiquement pour traiter les données visuelles. Contrairement aux réseaux de neurones traditionnels qui traitent les données d'entrée comme des vecteurs plats, les CNN préservent les relations spatiales grâce à leur structure de couche unique. Cette conscience spatiale leur permet de détecter des motifs, des bords et des textures d'une manière qui imite le traitement visuel humain. La capacité d'extraction hiérarchique des caractéristiques rend les CNN particulièrement efficaces pour les tâches visuelles complexes où le contexte et les relations spatiales comptent.
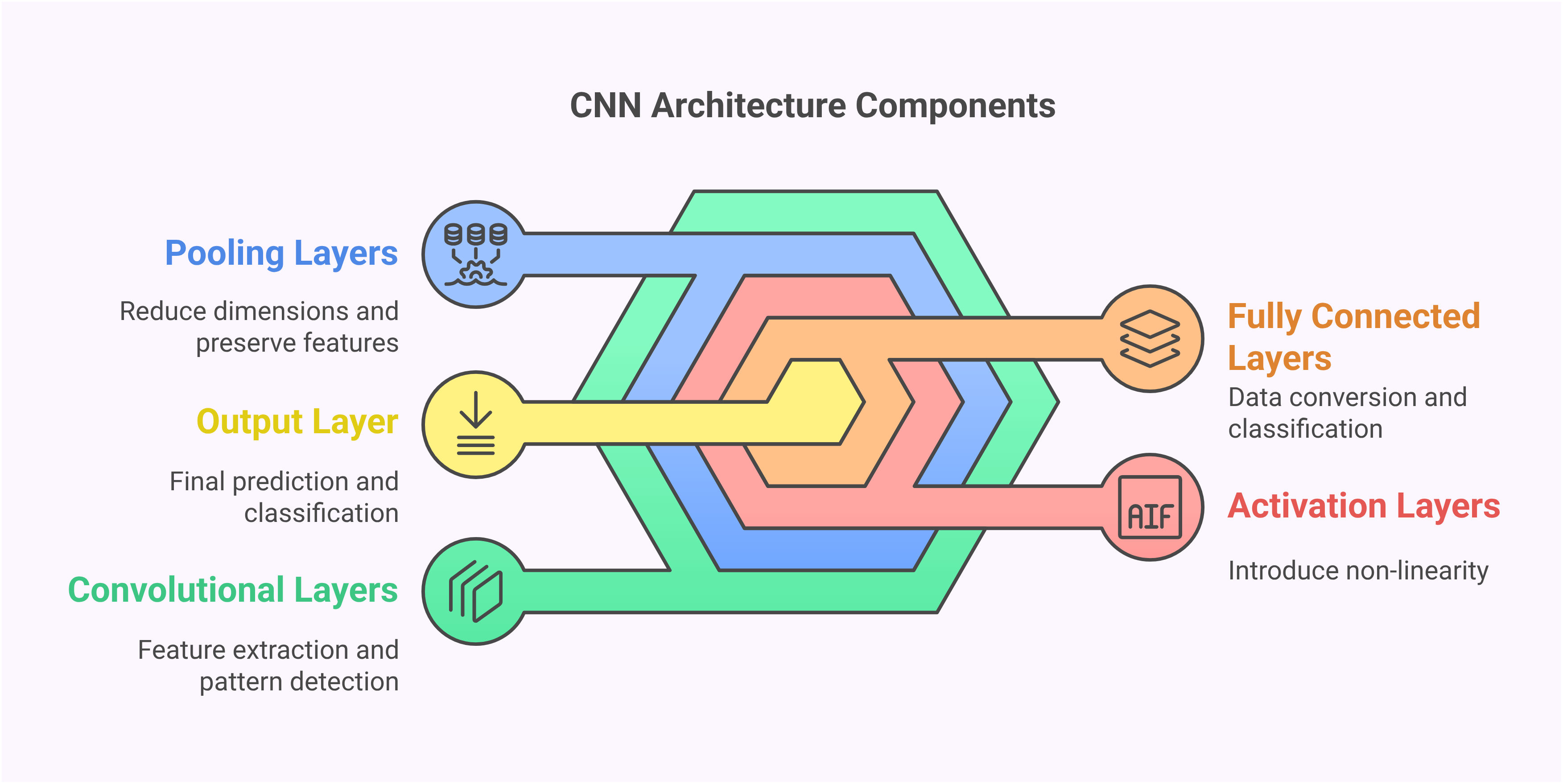
Les éléments de base fondamentaux des CNN incluent des couches convolutionnelles qui balayent les images avec des filtres pour détecter des caractéristiques, des couches de pooling qui réduisent la dimensionnalité tout en préservant les informations importantes, et des couches entièrement connectées qui effectuent la classification finale. Cette approche structurée permet aux CNN d'apprendre automatiquement des caractéristiques pertinentes sans ingénierie manuelle, les rendant idéaux pour diverses applications de reconnaissance d'images allant des diagnostics médicaux aux systèmes de conduite autonome.
Configuration de l'environnement et outils requis
Avant de mettre en œuvre votre CNN, une configuration appropriée de l'environnement est essentielle. Ce tutoriel utilise Python 3.7+ avec TensorFlow 2.x et Keras comme framework principal d'apprentissage profond. Le processus de configuration implique l'installation de plusieurs packages clés qui fournissent l'épine dorsale computationnelle pour les opérations de réseaux de neurones. Commencez par créer un environnement virtuel pour gérer les dépendances proprement, puis installez les packages requis en utilisant pip.
Les packages principaux incluent TensorFlow pour les calculs backend, Keras pour les API de haut niveau des réseaux de neurones, NumPy pour les opérations numériques et Matplotlib pour la visualisation. Les bibliothèques supplémentaires utiles incluent OpenCV pour le traitement avancé d'images et Scikit-learn pour les utilitaires de prétraitement des données. Ces outils fournissent collectivement une base robuste pour construire et expérimenter avec des modèles d'apprentissage profond à travers différentes configurations matérielles.
Bibliothèques Python essentielles pour le développement de CNN
L'importation des bonnes bibliothèques établit la base de votre système de reconnaissance d'images. Les imports clés incluent NumPy pour les opérations sur les tableaux, les couches Keras pour l'architecture du réseau, et les utilitaires de jeu de données pour charger les données d'entraînement. Chaque bibliothèque sert des objectifs spécifiques dans le pipeline CNN, de la manipulation des données à la définition et à l'entraînement du modèle.
Le modèle Sequential de Keras fournit une pile linéaire de couches, tandis que Conv2D implémente les opérations convolutionnelles. Les couches Dropout empêchent le surapprentissage, BatchNormalization stabilise l'entraînement, et MaxPooling2D réduit les dimensions spatiales. Comprendre le rôle de chaque composant aide à concevoir des architectures efficaces et à résoudre les problèmes pendant le développement. Ces bibliothèques forment le cœur des frameworks d'apprentissage profond modernes utilisés dans les environnements de production.
Travailler avec le jeu de données CIFAR-10
Le jeu de données CIFAR-10 sert d'excellent benchmark pour les tâches de reconnaissance d'images, contenant 60 000 images couleur réparties en 10 catégories incluant des avions, des automobiles, des oiseaux, des chats, des cerfs, des chiens, des grenouilles, des chevaux, des navires et des camions. Chaque image de 32x32 pixels représente des objets du monde réel avec des perspectives et des conditions d'éclairage variées, ce qui la rend suffisamment difficile pour démontrer les capacités des CNN tout en restant gérable computationnellement.
Le prétraitement des données implique de normaliser les valeurs des pixels dans la plage 0-1 en divisant par 255, ce qui stabilise l'entraînement et améliore la convergence. L'encodage one-hot transforme les étiquettes catégorielles en vecteurs binaires, permettant une classification multi-classes. Un prétraitement approprié garantit que le réseau reçoit une entrée standardisée, réduisant le temps d'entraînement et améliorant la précision finale. Ce jeu de données fournit une expérience pratique avec des techniques de validation de modèle réelles.
Construction de l'architecture CNN avec Keras
Concevoir l'architecture CNN implique d'empiler stratégiquement des couches pour extraire des caractéristiques de plus en plus complexes. L'exemple d'architecture commence par des couches convolutionnelles utilisant des filtres 3x3 et l'activation ReLU, suivies de dropout et de normalisation par lots pour la régularisation. Les couches de max pooling réduisent les dimensions spatiales tout en préservant les caractéristiques importantes, et le réseau se termine par des couches denses pour la classification.
Les décisions architecturales clés incluent les tailles de filtres, les stratégies de pooling et la profondeur des couches. Les filtres plus petits (3x3) capturent des détails fins tandis que les filtres plus grands reconnaissent des motifs plus larges. Le nombre de filtres augmente dans les couches plus profondes pour gérer des combinaisons de caractéristiques plus complexes. Cette complexité progressive permet au réseau d'apprendre des représentations hiérarchiques, des bords simples dans les premières couches aux parties complexes d'objets dans les couches plus profondes. De telles architectures forment la base des systèmes de vision par ordinateur modernes.
Compilation du modèle et configuration de l'entraînement
Compiler le modèle implique de spécifier la fonction de perte, l'optimiseur et les métriques d'évaluation. Pour la classification multi-classes, l'entropie croisée catégorielle mesure l'erreur de prédiction, tandis que l'optimiseur Adam adapte les taux d'apprentissage pendant l'entraînement. Les métriques de précision suivent les performances tout au long du processus d'entraînement, fournissant un retour immédiat sur l'amélioration du modèle.
Les paramètres d'entraînement comme la taille du lot et les époques impactent significativement les résultats. Les lots plus petits fournissent des mises à jour de poids plus fréquentes mais nécessitent plus de calcul, tandis que les lots plus grands offrent une stabilité mais peuvent converger plus lentement. La division de validation surveille les performances de généralisation, aidant à détecter le surapprentissage tôt. Ces configurations équilibrent l'efficacité de l'entraînement avec la qualité du modèle, essentielle pour développer des applications d'IA fiables.
Étapes de mise en œuvre pratiques
La mise en œuvre suit un flux de travail structuré commençant par la configuration de l'environnement et le chargement des données. Après avoir importé les bibliothèques nécessaires, chargez et prétraitez le jeu de données CIFAR-10, puis définissez l'architecture CNN en utilisant l'API Sequential de Keras. Compilez le modèle avec les fonctions de perte et les optimiseurs appropriés, puis entraînez-le en utilisant les données préparées avec surveillance de la validation.
L'évaluation implique de tester le modèle entraîné sur des données non vues et d'analyser les métriques de performance. L'approche étape par étape garantit la compréhension de chaque composant tout en construisant un système complet fonctionnel. Cette méthodologie s'applique à diverses tâches de reconnaissance d'images au-delà de la portée du tutoriel, fournissant des compétences transférables pour des projets réels.
Avantages et inconvénients
Avantages
- Apprend automatiquement des caractéristiques pertinentes sans ingénierie manuelle
- Atteint une haute précision sur des tâches complexes de reconnaissance d'images
- Robuste aux variations d'échelle, de rotation et de conditions d'éclairage
- Traitement efficace grâce au partage des paramètres dans les couches convolutionnelles
- Efficacité prouvée à travers diverses applications de vision par ordinateur
- Amélioration continue avec des jeux de données plus grands et de meilleures architectures
- Capacités de transfert d'apprentissage pour des tâches visuelles connexes
Inconvénients
- Entraînement intensif en calcul nécessitant des ressources significatives
- Grands jeux de données étiquetés nécessaires pour des performances optimales
- Sensible au surapprentissage sans régularisation appropriée
- Réglage complexe des hyperparamètres pour des résultats optimaux
- Nature de boîte noire rendant l'interprétation difficile
Conclusion
Ce tutoriel démontre la mise en œuvre pratique des réseaux de neurones convolutionnels pour la reconnaissance d'images en utilisant Python et Keras. De la configuration de l'environnement à l'évaluation du modèle, nous avons couvert les étapes essentielles pour construire des systèmes efficaces de vision par ordinateur. Le jeu de données CIFAR-10 fournit un terrain d'essai réaliste, tandis que l'architecture CNN montre les techniques modernes d'apprentissage profond. Alors que vous continuez à développer des solutions de reconnaissance d'images, rappelez-vous que les mises en œuvre réussies équilibrent la complexité architecturale avec l'efficacité computationnelle, et valident toujours les performances avec des tests rigoureux. Les compétences acquises ici fournissent une base solide pour relever des défis de vision par ordinateur plus avancés dans des applications réelles.
Questions fréquemment posées
Quel est le nombre idéal de couches pour un CNN ?
Il n'y a pas de réponse universelle - commencez par 3-5 couches convolutionnelles pour les tâches de base, en augmentant la profondeur pour la reconnaissance complexe. Équilibrez la profondeur avec les contraintes de calcul et les risques de surapprentissage grâce à des techniques de régularisation appropriées.
Comment puis-je améliorer la précision de mon modèle CNN ?
Améliorez la précision par l'augmentation des données, le réglage des hyperparamètres, l'optimisation architecturale, les méthodes de régularisation et l'apprentissage par transfert. Expérimentez avec différents optimiseurs, taux d'apprentissage et configurations de couches tout en surveillant les performances de validation.
Ce tutoriel fonctionne-t-il avec d'autres ensembles de données ?
Oui, la méthodologie s'applique à divers ensembles de données d'images. Ajustez les dimensions d'entrée, la normalisation et les couches de sortie pour correspondre aux caractéristiques spécifiques de vos données tout en conservant les principes fondamentaux de l'architecture CNN.
Comment le CNN gère-t-il les variations d'image comme la rotation et l'échelle ?
Les CNN utilisent des couches de pooling et l'augmentation des données pour maintenir l'invariance aux petites transformations, mais peuvent nécessiter des techniques spécifiques comme les transformateurs spatiaux pour les grandes variations de rotation et d'échelle.
Quels sont les paramètres clés à régler dans un modèle CNN ?
Les paramètres importants incluent les tailles de filtre, le nombre de couches, le taux d'apprentissage, la taille du lot et les techniques de régularisation comme le dropout pour optimiser les performances et prévenir le surapprentissage dans les tâches de reconnaissance d'images.
Articles pertinents sur l'IA et les tendances technologiques
Restez à jour avec les dernières informations, outils et innovations qui façonnent l'avenir de l'IA et de la technologie.
Grok AI : Génération Illimitée de Vidéos Gratuite à partir de Texte et d'Images | Guide 2024
Grok AI propose une génération illimitée de vidéos gratuite à partir de texte et d'images, rendant la création de vidéos professionnelles accessible à tous sans compétences en montage.
Configuration de Grok 4 Fast sur Janitor AI : Guide Complet de Jeu de Rôle Sans Filtre
Guide étape par étape pour configurer Grok 4 Fast sur Janitor AI pour un jeu de rôle sans restriction, incluant la configuration de l'API, les paramètres de confidentialité et les conseils d'optimisation
Top 3 des extensions de codage IA gratuites pour VS Code 2025 - Boostez votre productivité
Découvrez les meilleures extensions d'agents de codage IA gratuites pour Visual Studio Code en 2025, y compris Gemini Code Assist, Tabnine et Cline, pour améliorer votre