Annotation
- Introduction
- Comprendre le rôle de l'IA dans la génération de données
- Construire un générateur de Pokémon : Exploiter les tableaux
- Créer un classificateur de sentiment : Tirer parti des énumérations
- Comparaison de la génération de tableaux et d'énumérations
- Personnalisation des sorties de données IA avec Zod
- Avantages et inconvénients
- Conclusion
- Questions fréquemment posées
Données Structurées IA : Guide des Tableaux et Énumérations pour Développeurs | ToolPicker
Ce guide explore l'utilisation des tableaux et des énumérations dans les SDK IA pour la génération de données structurées, avec des exemples pratiques comme les générateurs Pokémon et l'analyse de sentiments.

Introduction
Alors que l'intelligence artificielle continue de transformer le développement logiciel, maîtriser la génération de données structurées devient essentiel pour construire des applications robustes. Ce guide complet explore comment les développeurs peuvent exploiter les tableaux et les énumérations dans les SDK d'IA pour créer des sorties organisées et prévisibles. Ces structures de données permettent un traitement plus efficace, une meilleure sécurité des types et une expérience utilisateur améliorée dans les applications pilotées par l'IA à travers divers domaines.
Comprendre le rôle de l'IA dans la génération de données
Le développement logiciel traditionnel nécessite souvent une définition manuelle des structures de données, mais les SDK d'IA permettent désormais une génération dynamique qui s'adapte à des exigences spécifiques. Ce changement de paradigme permet aux applications de devenir plus flexibles et réactives aux besoins des utilisateurs. Les tableaux et les énumérations représentent deux modèles fondamentaux que les développeurs peuvent mettre en œuvre pour structurer efficacement les sorties de l'IA. Les tableaux organisent les éléments connexes en listes, tandis que les énumérations classent les données en catégories prédéfinies, offrant tous deux des avantages significatifs pour la validation des données et l'efficacité du traitement.
L'intégration de ces structures avec les outils de développement modernes crée des combinaisons puissantes pour construire des applications intelligentes. Lorsque vous travaillez avec les API et SDK d'IA, comprendre comment mettre correctement en œuvre les tableaux et les énumérations peut considérablement améliorer la cohérence des sorties et la fiabilité des applications.
Construire un générateur de Pokémon : Exploiter les tableaux
Les tableaux servent de fondement pour gérer les collections d'objets similaires dans les données générées par l'IA. Considérez un exemple pratique où vous devez générer des listes de Pokémon basées sur des types spécifiques comme 'feu' ou 'eau'. En utilisant un SDK d'IA, vous pouvez demander au modèle de produire des tableaux structurés contenant les noms des Pokémon et leurs capacités associées. Cette approche nécessite de définir un schéma clair pour les objets Pokémon individuels, puis d'encapsuler ce schéma dans une structure de tableau.
La mise en œuvre implique généralement l'utilisation de Zod, une bibliothèque de validation de schéma axée sur TypeScript, pour définir la structure de données :
import { z } from "zod";
export const pokemonSchema = z.object({
name: z.string(),
abilities: z.array(z.string()),
});
export const pokemonUISchema = z.array(pokemonSchema);Cette définition de schéma garantit que chaque objet Pokémon contient une chaîne de nom et un tableau de chaînes de capacités. Le pokemonUISchema spécifie ensuite que l'IA doit générer plusieurs instances de ces objets, créant une liste cohérente. L'aspect d'ingénierie des prompts implique d'instruire l'IA pour 'Générer une liste de 5 Pokémon de type {type}', où le paramètre de type s'ajuste dynamiquement en fonction de l'entrée utilisateur.
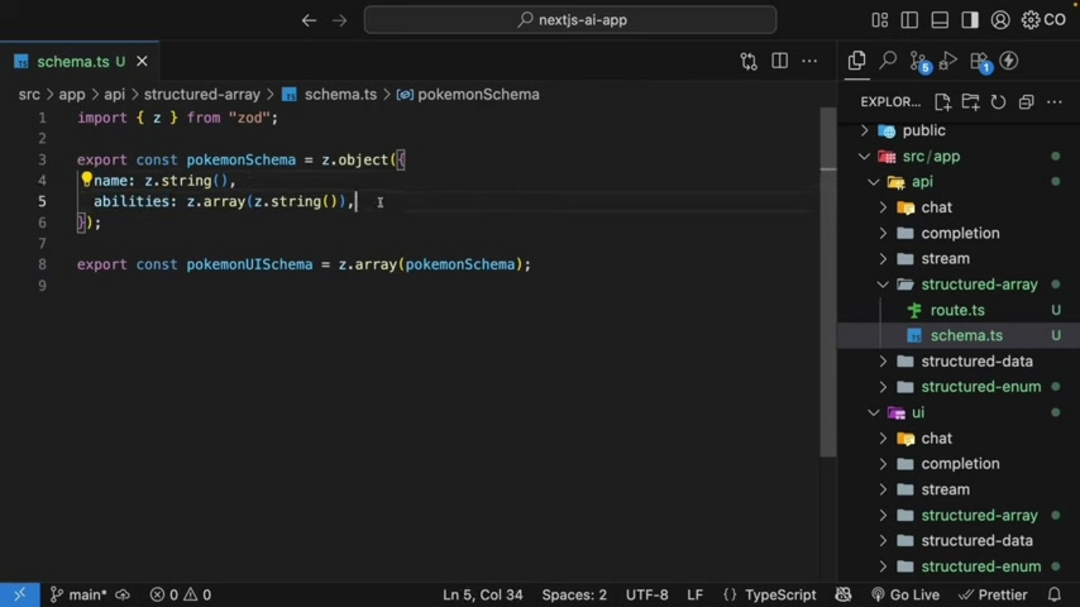
Les considérations clés de mise en œuvre incluent une validation de schéma appropriée, la spécification des sorties dans les gestionnaires de routes, et s'assurer que l'IA comprend le contexte du tableau. Cette approche démontre comment les tableaux peuvent organiser des collections de données complexes pour les applications nécessitant plusieurs objets similaires, ce qui est particulièrement utile pour les plateformes d'automatisation IA qui gèrent des tâches répétitives de génération de données.
Créer un classificateur de sentiment : Tirer parti des énumérations
Les énumérations offrent une approche structurée pour les tâches de classification où les sorties doivent appartenir à des catégories prédéfinies. Un classificateur d'analyse de sentiment illustre parfaitement ce concept, où le texte doit être catégorisé comme positif, négatif ou neutre. Contrairement aux tableaux, les énumérations ne nécessitent pas de définitions de schéma complexes – à la place, les développeurs spécifient directement les valeurs possibles dans le gestionnaire de route.
La mise en œuvre utilise généralement la fonction generateObject plutôt que des approches de streaming :
import { generateObject } from "ai";
import { openAI } from "@ai-sdk/openai";
export async function POST(req: Request) {
try {
const { text } = await req.json();
const result = await generateObject({
model: openAI("gpt-4.1-mini"),
output: "enum",
enum: ["positive", "negative", "neutral"],
prompt: `Classify the sentiment in this text: ${text}`,
});
return result.toJsonResponse();
} catch (error) {
console.error("Error generating sentiment", error);
return new Response("Failed to generate sentiment", { status: 500 });
}
}
Les facteurs critiques pour une mise en œuvre réussie des énumérations incluent la sélection du modèle – les modèles plus capables comme GPT-4.1-mini offrent une meilleure cohérence – et une définition claire des valeurs d'énumération. Cette approche garantit que les sorties de l'IA restent dans les limites attendues, ce qui est inestimable pour les agents et assistants IA qui nécessitent des capacités de classification fiables.
Comparaison de la génération de tableaux et d'énumérations
Comprendre les distinctions entre la génération de tableaux et d'énumérations aide les développeurs à sélectionner la structure de données appropriée pour des cas d'utilisation spécifiques. Les tableaux excellent dans la gestion de collections d'objets, tandis que les énumérations se spécialisent dans les tâches de classification où les sorties doivent se conformer à des catégories prédéfinies. Les différences de mise en œuvre vont au-delà des exigences de schéma pour inclure les fonctions SDK d'IA utilisées et la façon dont les données sont traitées.
Les tableaux fonctionnent généralement avec streamObject pour une génération de données progressive, les rendant adaptés aux grands ensembles de données ou aux applications en temps réel. Les énumérations, cependant, fonctionnent mieux avec generateObject puisqu'elles produisent des valeurs de classification uniques. Le tableau ci-dessous met en évidence les différences clés :
| Fonctionnalité | Tableaux | Énumérations |
|---|---|---|
| Structure de données | Liste d'objets | Catégories prédéfinies |
| Schéma requis | Oui, définit la structure de l'objet | Non, valeurs définies dans le gestionnaire |
| Type de sortie | tableau | énumération |
| Fonction SDK IA | streamObject | generateObject |
| Cas d'utilisation | Collections d'objets similaires | Classification et catégorisation |
| Traitement des données | Retourne un tableau d'objets | Retourne une valeur classifiée unique |
Ces différences structurelles impactent la façon dont les développeurs abordent l'ingénierie des prompts IA et la gestion des sorties, rendant une sélection appropriée cruciale pour le succès de l'application.
Personnalisation des sorties de données IA avec Zod
Zod offre des capacités étendues pour définir et valider les schémas dans les applications TypeScript, proposant une validation sécurisée par types qui garantit que les données générées par l'IA répondent à des exigences structurelles spécifiques. Au-delà des implémentations de base des tableaux et des énumérations, Zod prend en charge des scénarios de validation complexes qui améliorent la fiabilité des données et la robustesse des applications.
Les fonctionnalités avancées de Zod incluent la validation d'objets complexes pour les structures de données imbriquées, les fonctions de validation personnalisées pour les règles spécifiques à l'application, et les transformations de données qui modifient les sorties pour mieux s'adapter aux besoins de l'application. Ces capacités deviennent particulièrement précieuses lorsque vous travaillez avec les outils d'écriture IA qui génèrent du contenu structuré ou lorsque vous mettez en œuvre des règles de formatage de code pour les sorties générées.
En combinant la puissance de validation de Zod avec la génération de données IA, les développeurs peuvent créer des applications plus fiables qui gèrent efficacement les données structurées tout en maintenant la sécurité des types et l'intégrité des données tout au long du pipeline de traitement.
Avantages et inconvénients
Avantages
- Amélioration de la cohérence et de la prévisibilité des données dans les sorties IA
- Sécurité des types améliorée et réduction des erreurs d'exécution
- Organisation structurée des données pour une meilleure architecture d'application
- Flux de travail de validation et de traitement des données plus faciles
- Meilleure intégration avec les outils et bibliothèques de développement existants
- Code d'application IA plus maintenable et évolutif
- Séparation claire entre la structure des données et la logique métier
Inconvénients
- Complexité supplémentaire dans la définition et la validation des schémas
- Surcharge de performance potentielle avec des validations complexes
- Courbe d'apprentissage pour les développeurs nouveaux dans les données structurées IA
- Flexibilité limitée pour les modèles de données dynamiques ou imprévisibles
- Dépendance à des modèles IA spécifiques pour la cohérence des énumérations
Conclusion
Maîtriser les tableaux et les énumérations pour la génération de données structurées IA représente une avancée significative dans le développement logiciel moderne. Ces structures de données fournissent la base pour construire des applications IA fiables et maintenables qui produisent des sorties cohérentes et validées. En comprenant quand utiliser les tableaux pour les collections d'objets et les énumérations pour les tâches de classification, les développeurs peuvent créer des applications plus robustes qui exploitent efficacement les capacités de l'IA. L'intégration avec des bibliothèques de validation comme Zod améliore encore la fiabilité des données, tandis que des considérations de mise en œuvre appropriées assurent des performances optimales et une expérience utilisateur améliorée à travers diverses applications pilotées par l'IA.
Questions fréquemment posées
Quel est le principal avantage d'utiliser des tableaux pour les données générées par IA ?
Les tableaux offrent une organisation structurée pour les listes de points de données connexes, permettant une itération prévisible et le traitement de plusieurs éléments. Ceci est essentiel lorsque l'IA génère des collections d'objets similaires comme des produits ou des résultats de recherche, améliorant la gestion des données et la fiabilité de l'application.
Quand les développeurs doivent-ils choisir les énumérations plutôt que d'autres structures de données ?
Les énumérations sont idéales pour les tâches de classification où les sorties doivent correspondre à des catégories prédéfinies. Elles restreignent les réponses de l'IA à des valeurs spécifiques, garantissant la cohérence dans l'analyse des sentiments, la classification des statuts et les processus de prise de décision, tout en améliorant la robustesse de l'application.
Les énumérations peuvent-elles fonctionner avec streamObject dans les SDK IA ?
Non, les énumérations sont conçues spécifiquement pour generateObject, qui renvoie des valeurs de classification uniques. Pour les données en flux, les développeurs doivent utiliser des tableaux ou d'autres structures qui prennent en charge la génération de sortie progressive et le traitement en temps réel.
Pourquoi la sélection du modèle est-elle importante pour la génération d'énumérations ?
Les modèles d'IA plus performants offrent une meilleure cohérence dans la génération de valeurs d'énumération correctes. Les modèles moins avancés peuvent avoir du mal avec les catégories prédéfinies, conduisant à des résultats imprévisibles. La sélection de modèles appropriés garantit une sortie de classification fiable.
Comment Zod améliore-t-il la validation des données IA ?
Zod fournit une validation de schéma type-safe qui garantit que les données générées par l'IA répondent aux exigences structurelles, réduisant les erreurs et améliorant la fiabilité de l'application grâce à des schémas définis pour les tableaux, les énumérations et les objets complexes.
Articles pertinents sur l'IA et les tendances technologiques
Restez à jour avec les dernières informations, outils et innovations qui façonnent l'avenir de l'IA et de la technologie.
Grok AI : Génération Illimitée de Vidéos Gratuite à partir de Texte et d'Images | Guide 2024
Grok AI propose une génération illimitée de vidéos gratuite à partir de texte et d'images, rendant la création de vidéos professionnelles accessible à tous sans compétences en montage.
Configuration de Grok 4 Fast sur Janitor AI : Guide Complet de Jeu de Rôle Sans Filtre
Guide étape par étape pour configurer Grok 4 Fast sur Janitor AI pour un jeu de rôle sans restriction, incluant la configuration de l'API, les paramètres de confidentialité et les conseils d'optimisation
Top 3 des extensions de codage IA gratuites pour VS Code 2025 - Boostez votre productivité
Découvrez les meilleures extensions d'agents de codage IA gratuites pour Visual Studio Code en 2025, y compris Gemini Code Assist, Tabnine et Cline, pour améliorer votre