Annotation
- Introduction
- Évolution des techniques de classification de texte
- La révolution des transformeurs en TAL
- Frameworks d'apprentissage profond pour la classification de texte
- Apprentissage par transfert avec des modèles pré-entraînés
- Implémentation pratique avec ULMFiT
- Avantages et inconvénients
- Applications et outils du monde réel
- Analyse de texte d'entreprise avec Gong.io
- Étiquetage et planification automatisés des e-mails
- Directions futures en classification de texte
- Conclusion
- Questions fréquemment posées
Guide Avancé de Classification de Texte : Cadres et Techniques d'Apprentissage Profond
Guide avancé de classification de texte couvrant les cadres d'apprentissage profond, BERT, les transformateurs, l'apprentissage par transfert et les applications réelles pour une précision

Introduction
La classification de texte représente un pilier fondamental du traitement du langage naturel, permettant aux systèmes de catégoriser et d'interpréter automatiquement les données textuelles non structurées. Ce guide complet explore comment les frameworks d'apprentissage profond ont transformé les capacités de classification de texte, permettant une précision sans précédent dans la catégorisation de documents, l'analyse des sentiments et l'organisation automatisée du contenu. Que vous construisiez des systèmes d'automatisation du service client ou de modération de contenu, comprendre ces techniques avancées est essentiel pour les applications modernes de l'IA.
Évolution des techniques de classification de texte
La progression des méthodologies de classification de texte reflète les avancées plus larges en linguistique computationnelle et en apprentissage automatique. Les premières approches reposaient largement sur des méthodes statistiques qui traitaient le texte comme de simples collections de mots sans considérer les relations sémantiques ou le sens contextuel.

Le modèle Bag of Words est apparu comme une norme précoce, représentant les documents comme des vecteurs de fréquence de mots tout en ignorant complètement la grammaire, l'ordre des mots et le contexte sémantique. Bien que simple à mettre en œuvre et fournissant des résultats interprétables, BoW souffrait de limitations significatives, y compris des contraintes de vocabulaire et une incapacité à capturer les relations entre les mots. Par exemple, il traitait « chat » et « chaton » comme des entités complètement distinctes sans connexion sémantique, et traitait « le film était drôle et pas ennuyeux » de manière identique à « le film était ennuyeux et pas drôle » – clairement problématique pour une classification précise des sentiments.
Alors que les ressources computationnelles s'étendaient et que les architectures de réseaux neuronaux mûrissaient, des approches plus sophistiquées ont émergé. Les réseaux neuronaux convolutifs (CNN) et les réseaux neuronaux récurrents (RNN) ont commencé à exploiter des représentations de mots distribuées qui capturaient les similitudes sémantiques via des modèles d'espace vectoriel. Cette percée a permis aux modèles de comprendre que les mots apparentés devraient avoir des représentations vectorielles similaires, améliorant considérablement la précision de la classification dans divers domaines, y compris les chatbots IA et les systèmes de réponse automatisée.
La révolution des transformeurs en TAL
L'introduction en 2018 des architectures transformeurs a marqué un tournant décisif pour le traitement du langage naturel. Ces modèles utilisaient des mécanismes d'auto-attention pour traiter des séquences entières simultanément tout en capturant les relations contextuelles entre tous les mots d'un document.
Des modèles comme BERT, ELMo et GPT ont exploité les architectures transformeurs pour générer des plongements de mots contextuels – des représentations qui varient en fonction des mots environnants plutôt que de maintenir des représentations statiques. Cette compréhension contextuelle a permis des performances sans précédent dans les tâches nécessitant une compréhension nuancée du langage, de l'analyse de documents juridiques à la catégorisation de textes médicaux. Les demandes computationnelles de ces modèles nécessitent généralement une accélération GPU, mais les améliorations de précision justifient l'investissement en infrastructure pour les systèmes de production, particulièrement dans les plateformes d'automatisation IA où la précision est critique.
Frameworks d'apprentissage profond pour la classification de texte
Les pipelines modernes de classification de texte exploitent généralement des frameworks d'apprentissage profond établis qui fournissent des outils complets pour le développement, l'entraînement et le déploiement de modèles. L'écosystème a considérablement mûri, offrant plusieurs options robustes adaptées à différents cas d'utilisation et préférences d'équipe.
TensorFlow, développé par Google, offre un écosystème prêt pour la production avec une documentation étendue et un support communautaire. Son graphe de calcul statique fournit des opportunités d'optimisation qui bénéficient aux scénarios de déploiement à grande échelle. PyTorch, favorisé par les communautés de recherche, propose des graphes de calcul dynamiques qui permettent des architectures de modèles plus flexibles et des workflows de débogage plus faciles. Les deux frameworks s'intègrent de manière transparente avec des bibliothèques TAL spécialisées comme spaCy, qui fournit une tokenisation, un étiquetage morphosyntaxique et une reconnaissance d'entités nommées de qualité industrielle – des étapes de prétraitement essentielles pour une classification de texte efficace dans les API et SDK IA.
Apprentissage par transfert avec des modèles pré-entraînés
L'apprentissage par transfert a considérablement réduit les besoins en données et en calcul pour construire des classificateurs de texte haute performance. Au lieu d'entraîner des modèles à partir de zéro, les praticiens peuvent affiner des modèles pré-entraînés sur d'énormes corpus de texte, adaptant la compréhension générale du langage à des tâches de classification spécifiques.
Cette approche tire parti des connaissances linguistiques encodées dans des modèles comme BERT, qui ont appris des structures grammaticales, des relations sémantiques et même des connaissances factuelles en s'entraînant sur Wikipédia, des livres et du contenu web. L'affinage nécessite des ensembles de données étiquetés significativement plus petits – parfois seulement des centaines ou des milliers d'exemples plutôt que des millions – rendant la classification de texte sophistiquée accessible aux organisations sans ressources de données massives. Cette méthodologie s'est avérée particulièrement précieuse pour les outils d'écriture IA qui doivent catégoriser le contenu par ton, style ou sujet.
Implémentation pratique avec ULMFiT
L'approche Universal Language Model Fine-tuning (ULMFiT) fournit une méthodologie structurée pour adapter des modèles de langage pré-entraînés à des tâches spécifiques de classification de texte. Ce processus en trois phases est devenu un workflow standard pour de nombreux praticiens du TAL.
Premièrement, commencez avec un modèle de langage pré-entraîné sur un grand corpus général comme Wikipédia. Ce modèle a déjà appris des modèles de langage généraux et des relations sémantiques. Deuxièmement, affinez ce modèle de langage sur du texte spécifique au domaine – même du texte non étiqueté de votre domaine cible améliore les performances. Enfin, ajoutez une couche de classification et affinez l'ensemble du modèle sur votre ensemble de données de classification étiqueté. Cette approche de spécialisation progressive surpasse généralement l'entraînement direct de classificateurs sur des données étiquetées limitées.
Pour les plongements de mots personnalisés, le processus implique d'utiliser Gensim pour implémenter un générateur de phrases qui alimente les algorithmes Word2Vec, entraînant des plongements spécifiques au domaine qui peuvent ensuite être intégrés aux pipelines spaCy pour des tâches de classification en aval. Cette approche est particulièrement précieuse pour les outils d'IA conversationnelle qui doivent comprendre la terminologie spécifique au domaine et les modèles de formulation.
Avantages et inconvénients
Avantages
- La compréhension contextuelle capture la signification nuancée du langage
- L'apprentissage par transfert réduit significativement les besoins en données
- Les modèles pré-entraînés fournissent une performance de base solide
- Les écosystèmes de frameworks offrent des outils et un support étendus
- Les architectures évolutives gèrent de grands volumes de documents
- Amélioration continue grâce à l'affinage des modèles
- Support multilingue via des plongements translinguistiques
Inconvénients
- L'intensité computationnelle nécessite des ressources GPU
- Défis d'interprétabilité des modèles pour les utilisateurs métier
- L'adaptation au domaine nécessite encore une expertise technique
- Limitations de vocabulaire pour la terminologie hautement spécialisée
- Complexité de déploiement dans les environnements de production
Applications et outils du monde réel
Analyse de texte d'entreprise avec Gong.io
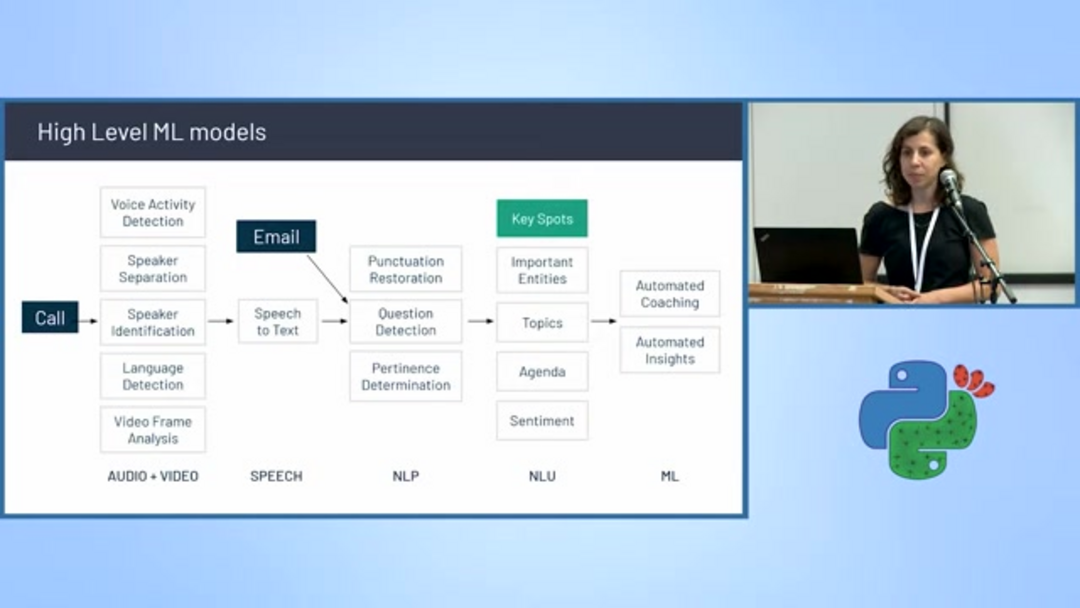
Les plateformes commerciales comme Gong.io démontrent comment la classification de texte avancée transforme les opérations commerciales, particulièrement dans les domaines des ventes et de la réussite client. La plateforme enregistre, transcrit et analyse les conversations de vente en utilisant un pipeline sophistiqué de modèles d'apprentissage automatique.
L'architecture de Gong intègre plusieurs classificateurs spécialisés, y compris la détection d'activité vocale, la séparation et l'identification des locuteurs, la détection de langue et la conversion parole-texte. Au-delà de la transcription de base, le système effectue une analyse avancée incluant la restauration de la ponctuation, la détection de questions, la modélisation de sujets, la détermination de la pertinence, le suivi de l'ordre du jour, l'analyse des sentiments et l'extraction d'entités. Cette approche complète permet aux agents et assistants IA de fournir des insights actionnables aux équipes de vente, mettant en évidence les mentions concurrentielles, les discussions sur les propositions de valeur et les modèles de gestion des objections.
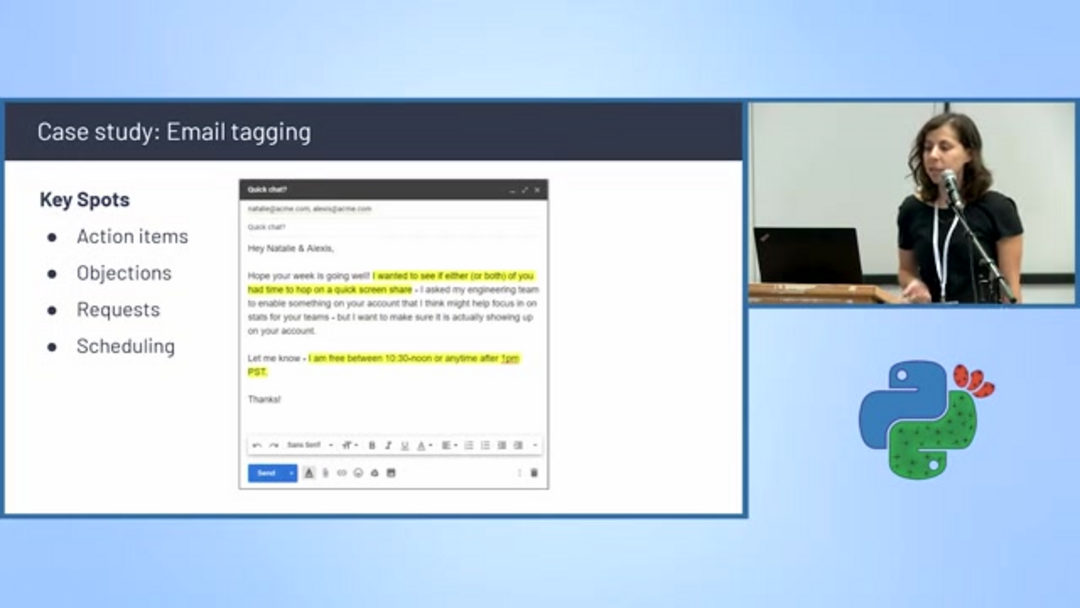
Étiquetage et planification automatisés des e-mails
La classification de texte alimente les systèmes de gestion intelligente des e-mails qui catégorisent automatiquement les messages et extraient des informations actionnables. Les algorithmes de détection de planification identifient les e-mails contenant des propositions de réunion, des discussions sur la disponibilité et la coordination des calendriers, les étiquetant automatiquement pour un traitement prioritaire.
Ces systèmes analysent les éléments clés de la conversation, y compris les éléments d'action, les objections, les demandes spécifiques et les mentions de planification. En filtrant et en catégorisant les e-mails en fonction du contenu, les entreprises peuvent rationaliser la gestion des workflows et assurer un suivi rapide des communications critiques. Cette capacité est particulièrement précieuse pour les assistants e-mail IA qui aident à gérer les boîtes de réception débordantes et à prioriser les réponses.
Directions futures en classification de texte
Le domaine continue d'évoluer rapidement, avec plusieurs directions de recherche prometteuses abordant les limitations actuelles et élargissant les possibilités d'application. L'IA explicable (XAI) se concentre sur la rendue des décisions des modèles interprétables pour les utilisateurs humains, construisant la confiance et facilitant l'analyse des erreurs. La modélisation du langage à faible ressource vise à étendre les capacités de classification sophistiquées aux langues avec des ressources textuelles numériques limitées.
Les approches multimodales intègrent le texte avec d'autres types de données comme les images et l'audio, créant des contextes de compréhension plus riches – particulièrement précieux pour l'analyse des médias sociaux où le texte et le contenu visuel interagissent. Les stratégies d'apprentissage actif optimisent les efforts d'annotation en identifiant les échantillons les plus informatifs pour l'examen humain, tandis que les techniques d'apprentissage en peu de coups permettent une adaptation efficace des modèles avec un minimum d'exemples d'entraînement, abordant l'un des points douloureux les plus significatifs dans le déploiement de l'apprentissage automatique.
Conclusion
La classification de texte a évolué de méthodes statistiques simples à des approches d'apprentissage profond sophistiquées qui comprennent la nuance contextuelle et les relations sémantiques. La combinaison des architectures transformeurs, de l'apprentissage par transfert et des frameworks complets a rendu la classification haute précision accessible à travers divers domaines et applications. Alors que la recherche continue d'avancer en expliquabilité, en efficacité et en capacités multimodales, la classification de texte deviendra de plus en plus intégrante aux systèmes intelligents qui traitent, organisent et tirent des insights des volumes toujours croissants de texte numérique. Maîtriser ces techniques procure un avantage concurrentiel significatif dans le développement de solutions alimentées par l'IA qui comprennent et catégorisent le langage humain avec une compréhension semblable à celle de l'homme.
Questions fréquemment posées
Pourquoi l'ordre des mots est-il important dans la classification de texte ?
L'ordre des mots porte un sens sémantique crucial - changer la séquence peut complètement altérer le sens d'une phrase. Les modèles qui ignorent l'ordre des mots ne peuvent pas distinguer entre 'le film était drôle et pas ennuyeux' et 'le film était ennuyeux et pas drôle', conduisant à des résultats de classification inexacts, particulièrement dans l'analyse des sentiments.
Quelles sont les principales étapes pour entraîner des plongements de mots personnalisés ?
L'entraînement de plongements personnalisés implique trois étapes clés : implémenter un générateur de phrases utilisant Gensim pour alimenter le modèle en texte, exécuter Word2Vec ou des algorithmes similaires pour entraîner les plongements sur votre corpus de domaine, puis intégrer le modèle entraîné avec spaCy ou d'autres pipelines TAL pour les tâches de classification en aval nécessitant une compréhension du langage spécifique au domaine.
Comment l'apprentissage par transfert profite-t-il à la classification de texte ?
L'apprentissage par transfert permet de fine-tuner des modèles pré-entraînés sur des tâches spécifiques, réduisant les besoins en données et améliorant la précision en tirant parti des connaissances de grands ensembles de données, le rendant efficace pour l'adaptation de domaine.
Quels sont les principaux avantages des modèles transformateurs en TAL ?
Les modèles transformateurs utilisent l'auto-attention pour traiter les séquences en parallèle, capturant les relations contextuelles entre les mots, conduisant à de meilleures performances dans des tâches comme la classification de texte et l'analyse des sentiments.
Comment la classification de texte peut-elle être appliquée dans les environnements commerciaux ?
La classification de texte est utilisée dans l'automatisation du service client, la modération de contenu, la catégorisation des e-mails et l'analyse des ventes, aidant les entreprises à automatiser les processus et à tirer des insights des données textuelles.
Articles pertinents sur l'IA et les tendances technologiques
Restez à jour avec les dernières informations, outils et innovations qui façonnent l'avenir de l'IA et de la technologie.
Grok AI : Génération Illimitée de Vidéos Gratuite à partir de Texte et d'Images | Guide 2024
Grok AI propose une génération illimitée de vidéos gratuite à partir de texte et d'images, rendant la création de vidéos professionnelles accessible à tous sans compétences en montage.
Configuration de Grok 4 Fast sur Janitor AI : Guide Complet de Jeu de Rôle Sans Filtre
Guide étape par étape pour configurer Grok 4 Fast sur Janitor AI pour un jeu de rôle sans restriction, incluant la configuration de l'API, les paramètres de confidentialité et les conseils d'optimisation
Top 3 des extensions de codage IA gratuites pour VS Code 2025 - Boostez votre productivité
Découvrez les meilleures extensions d'agents de codage IA gratuites pour Visual Studio Code en 2025, y compris Gemini Code Assist, Tabnine et Cline, pour améliorer votre