Annotation
- Introduction
- Comprendre la classification de texte zero-shot
- Approches de classification traditionnelle vs zero-shot
- Aperçu de la bibliothèque Hugging Face Transformers
- Améliorer les performances de la classification zero-shot
- Guide de mise en œuvre pratique
- Tarification et licence de Hugging Face
- Avantages et inconvénients
- Applications et cas d'utilisation réels
- Conclusion
- Questions fréquemment posées
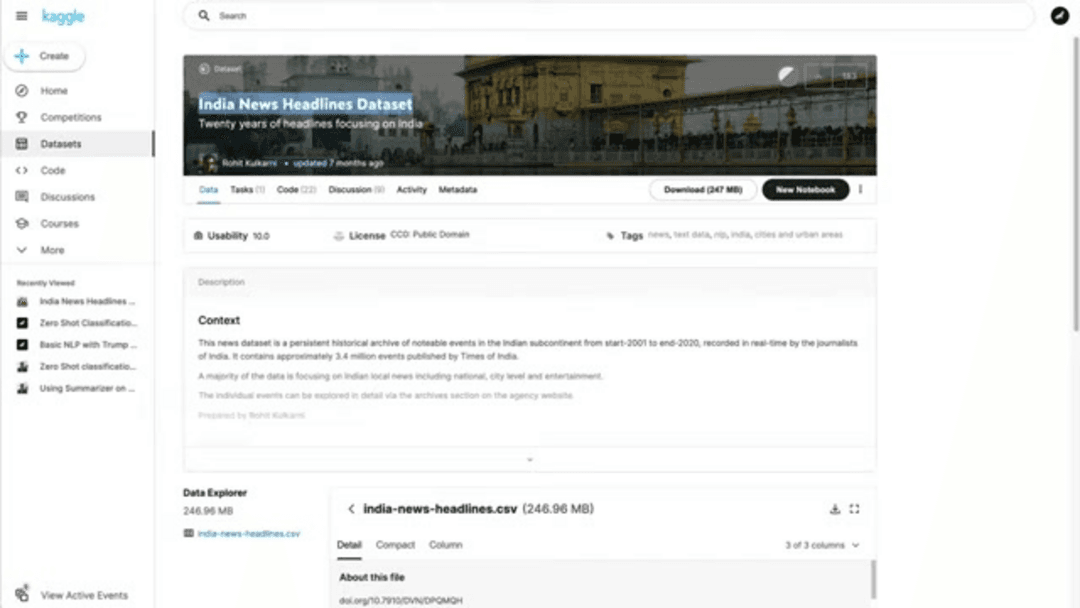
Classification de Texte Zero-Shot avec Hugging Face : Guide Pratique Complet
La classification de texte zero-shot avec Hugging Face permet de catégoriser du texte sans données d'entraînement. Ce guide couvre la mise en œuvre, les avantages et le code
Introduction
La classification de texte traditionnelle a longtemps reposé sur des ensembles de données étiquetés étendus, nécessitant un effort manuel et des ressources significatifs. Cependant, la classification de texte zero-shot représente un changement de paradigme dans le traitement du langage naturel, permettant aux modèles d'IA de catégoriser le texte en classes prédéfinies sans aucun entraînement préalable sur des exemples étiquetés. Cette approche révolutionnaire exploite la puissance des modèles de langage pré-entraînés de la bibliothèque Transformers de Hugging Face, rendant la classification de texte accessible même lorsque les données étiquetées sont indisponibles. Ce guide complet explore la mise en œuvre pratique, les avantages et les applications réelles de la classification zero-shot pour les développeurs et les scientifiques des données.
Comprendre la classification de texte zero-shot
Qu'est-ce que la classification de texte zero-shot ?
La classification de texte zero-shot représente une technique avancée d'apprentissage automatique où les modèles catégorisent le texte en classes qu'ils n'ont jamais rencontrées pendant l'entraînement. Contrairement aux approches traditionnelles qui nécessitent des ensembles de données étiquetés étendus, la classification zero-shot tire parti des capacités de compréhension sémantique des grands modèles de langage. Ces modèles, entraînés sur d'immenses corpus de texte, développent des représentations sophistiquées des relations linguistiques, leur permettant de généraliser à de nouvelles tâches de classification sans entraînement supplémentaire. Cette capacité est particulièrement précieuse dans des environnements dynamiques où les catégories changent fréquemment ou lorsque les données étiquetées sont rares.
Le mécanisme sous-jacent implique de comparer la similarité sémantique entre le texte d'entrée et les étiquettes candidates en utilisant les connaissances préexistantes du modèle. Lorsque vous fournissez un échantillon de texte et des catégories potentielles, le modèle évalue à quel point le texte s'aligne avec chaque étiquette en fonction de sa compréhension des modèles linguistiques et des relations contextuelles. Cette approche élimine le besoin d'étiquetage de données chronophage et de réentraînement du modèle, la rendant idéale pour le prototypage rapide et le déploiement en environnements de production.
Approches de classification traditionnelle vs zero-shot
La classification de texte traditionnelle suit un paradigme d'apprentissage supervisé, nécessitant des ensembles de données soigneusement organisés où chaque exemple de texte est manuellement étiqueté avec sa catégorie correspondante. Ce processus implique de collecter des milliers d'exemples, de les annoter avec les étiquettes appropriées et d'entraîner un modèle spécialisé qui apprend à reconnaître les modèles associés à chaque catégorie. Bien qu'efficace, cette approche demande des ressources substantielles et devient peu pratique lorsqu'il s'agit de sujets émergents ou de besoins de classification en évolution rapide.
La classification zero-shot diffère fondamentalement en utilisant des modèles qui ont déjà développé une compréhension complète du langage grâce à un pré-entraînement sur diverses sources de texte. Ces modèles peuvent déduire les relations entre un nouveau texte et des étiquettes candidates sans entraînement spécifique sur les catégories cibles. Les avantages vont au-delà de la simple élimination de l'étiquetage des données – la classification zero-shot offre une flexibilité remarquable, vous permettant de vous adapter instantanément à de nouveaux schémas de classification en modifiant simplement les étiquettes candidates. Cela la rend particulièrement précieuse pour les applications dans les chatbots IA et les outils d'IA conversationnelle où les requêtes des utilisateurs peuvent couvrir divers sujets.
Aperçu de la bibliothèque Hugging Face Transformers
La bibliothèque Hugging Face Transformers est devenue la ressource définitive pour le traitement moderne du langage naturel, fournissant un accès simplifié aux modèles pré-entraînés de pointe. Cette bibliothèque complète abstrait les complexités de l'architecture et de la mise en œuvre des modèles, permettant aux développeurs de se concentrer sur la résolution de problèmes pratiques plutôt que sur les détails techniques. Pour la classification zero-shot spécifiquement, Hugging Face propose des versions optimisées de modèles populaires comme BERT, RoBERTa et DistilBERT, chacun avec des forces distinctes et des caractéristiques de performance.
Ce qui rend la bibliothèque particulièrement puissante est son interface de pipeline intuitive, qui permet des tâches NLP complexes avec un code minimal. Le pipeline de classification zero-shot gère toute la complexité sous-jacente, y compris la tokenisation, l'inférence du modèle et l'interprétation des résultats, offrant une API propre et conviviale. Cette accessibilité a démocratisé les capacités NLP avancées, les rendant disponibles aux développeurs sans expertise approfondie en apprentissage automatique ou en architectures de transformateurs. La compatibilité de la bibliothèque avec diverses API et SDK d'IA améliore encore son utilité dans les environnements de production.
Améliorer les performances de la classification zero-shot
Sélection des modèles pré-entraînés optimaux
Choisir le bon modèle pré-entraîné a un impact significatif sur la précision et les performances de la classification zero-shot. Différents modèles excellent dans divers scénarios en fonction de leurs données d'entraînement, de leur architecture et de leurs cas d'utilisation prévus. BERT (Bidirectional Encoder Representations from Transformers) reste un choix populaire pour ses performances robustes sur divers types de texte, ayant été entraîné sur des données de Wikipédia et de corpus de livres. Son mécanisme d'attention bidirectionnelle lui permet de comprendre le contexte dans les deux directions, le rendant particulièrement efficace pour les tâches de classification nuancées.
RoBERTa (Robustly Optimized BERT Pretraining Approach) représente une version optimisée qui supprime l'objectif de prédiction de phrase suivante de BERT et emploie un entraînement plus étendu avec des lots plus grands et des séquences plus longues. Ces optimisations entraînent souvent des performances supérieures pour les tâches zero-shot. Pour les environnements à ressources limitées, DistilBERT offre une alternative convaincante – cette version distillée maintient environ 97 % des performances de BERT tout en étant 40 % plus petite et 60 % plus rapide, la rendant idéale pour les applications nécessitant une inférence rapide ou un déploiement sur du matériel limité.
Formulation stratégique des étiquettes candidates
La qualité et la formulation des étiquettes candidates influencent directement la précision de la classification dans les scénarios zero-shot. Les étiquettes efficaces doivent être descriptives, non ambiguës et sémantiquement distinctes les unes des autres. Au lieu d'utiliser des catégories à un seul mot comme « sports », envisagez des phrases plus descriptives comme « actualités sportives professionnelles » ou « activités athlétiques amateurs » qui fournissent des signaux sémantiques plus clairs au modèle. Cette spécificité aide le modèle à mieux comprendre les limites de catégorisation prévues et réduit la confusion entre des concepts similaires.
Lorsqu'on traite des systèmes de catégorisation hiérarchiques, vous pouvez structurer les étiquettes pour refléter ces relations. Par exemple, au lieu d'utiliser des étiquettes plates comme « basketball » et « football », vous pourriez mettre en œuvre une approche hiérarchique avec « sports - basketball - NBA » et « sports - football - NFL ». Cet étiquetage structuré peut améliorer la précision en tirant parti de la compréhension par le modèle des relations entre catégories. De plus, envisagez d'inclure des exemples négatifs ou des étiquettes hors du champ lorsque c'est approprié, car cela aide le modèle à mieux distinguer entre les classifications pertinentes et non pertinentes pour votre cas d'utilisation spécifique.
Stratégies de fine-tuning spécifiques au domaine
Bien que la classification zero-shot fonctionne remarquablement bien dès le départ, les performances peuvent être encore améliorées par un fine-tuning spécifique au domaine lorsque la terminologie ou le contexte spécialisé est impliqué. Le fine-tuning implique un entraînement supplémentaire sur un petit ensemble de données pertinent pour votre domaine spécifique, permettant au modèle d'adapter sa compréhension au vocabulaire et aux concepts spécialisés. Cette approche est particulièrement précieuse pour les domaines techniques comme la littérature médicale, les documents juridiques ou les articles scientifiques où les modèles de langage standards peuvent avoir du mal avec la terminologie spécifique au domaine.
Le processus de fine-tuning nécessite généralement un modeste ensemble de données d'exemples étiquetés de votre domaine cible – souvent, quelques centaines d'échantillons peuvent donner des améliorations significatives. Pendant le fine-tuning, le modèle ajuste ses paramètres pour mieux reconnaître les modèles et les relations spécifiques à votre domaine tout en conservant ses capacités de compréhension générale du langage. Cette approche hybride combine la flexibilité de la classification zero-shot avec la précision de l'adaptation au domaine, la rendant idéale pour les applications spécialisées dans les plateformes d'automatisation IA et les systèmes d'entreprise.
Guide de mise en œuvre pratique
Configuration de l'environnement et installation
Démarrer avec la classification zero-shot nécessite une configuration minimale, grâce à l'écosystème bien conçu de Hugging Face. Commencez par installer les packages Python nécessaires en utilisant pip. La bibliothèque transformers fournit les fonctionnalités principales, tandis que pandas offre des capacités de manipulation de données pratiques pour gérer les ensembles de données texte. Pour des performances optimales, assurez-vous d'utiliser un environnement Python avec la version 3.7 ou supérieure, et envisagez de configurer l'accélération GPU si disponible, car cela peut accélérer considérablement l'inférence pour les ensembles de données plus volumineux.
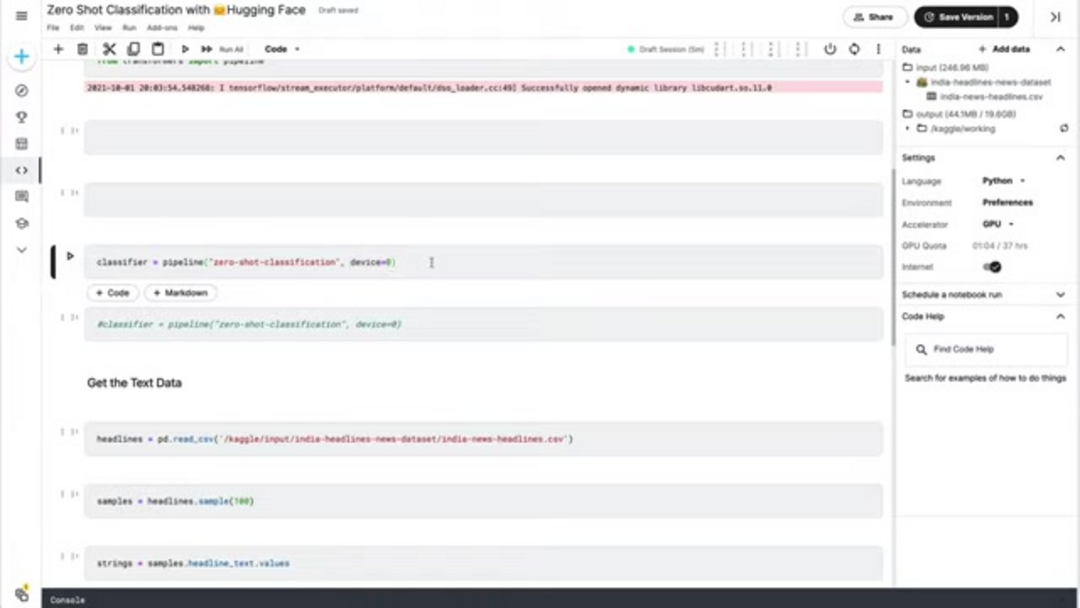
pip install transformers pandas torchAprès l'installation, importez les composants nécessaires dans votre script Python ou notebook. La fonction pipeline de transformers fournit l'interface de haut niveau pour la classification zero-shot, tandis que pandas facilite le chargement et la manipulation des données. Si vous avez un GPU compatible CUDA disponible, PyTorch l'utilisera automatiquement pour un calcul accéléré, bien que l'exécution sur CPU reste entièrement fonctionnelle pour les applications à petite échelle.
from transformers import pipeline
import pandas as pdPréparation des données et initialisation du classifieur
Une préparation appropriée des données est cruciale pour une classification zero-shot efficace. Commencez par charger vos données texte à partir de fichiers source – les formats courants incluent CSV, JSON ou des fichiers texte brut. À des fins de démonstration, nous supposerons un fichier CSV contenant des titres d'actualités, mais l'approche se généralise à toute source de texte. Assurez-vous que vos données texte sont propres et correctement formatées, car les caractères superflus ou les problèmes de formatage peuvent affecter la précision de la classification.
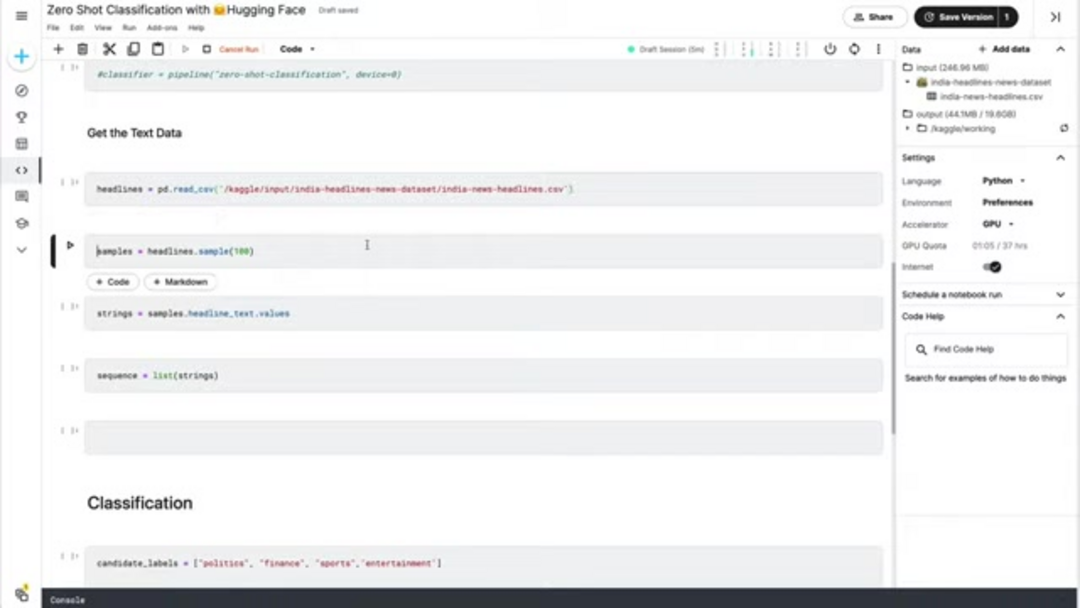
# Charger les données de titres depuis CSV
headlines_df = pd.read_csv('news_headlines.csv')
headline_samples = headlines_df['headline_text'].sample(100).tolist()Initialisez le classifieur zero-shot en utilisant la fonction pipeline de Hugging Face. Le paramètre device vous permet de spécifier si vous voulez utiliser le traitement CPU ou GPU – définir device=0 active le premier GPU disponible pour une inférence accélérée. Le classifieur télécharge et configure automatiquement un modèle pré-entraîné approprié, généralement une version de BERT optimisée pour les tâches zero-shot.
# Initialiser le classifieur avec accélération GPU
classifier = pipeline('zero-shot-classification', device=0)Exécution de la classification et analyse des résultats
Avec vos données préparées et le classifieur initialisé, définissez vos étiquettes candidates en fonction des catégories que vous voulez identifier. Ces étiquettes représentent les classifications potentielles pour vos données texte. Choisissez des étiquettes qui sont mutuellement exclusives et couvrent de manière exhaustive les types de contenu attendus dans votre ensemble de données. Pour la catégorisation des actualités, les étiquettes typiques pourraient inclure politique, affaires, sports, divertissement, technologie et santé.
candidate_labels = ['politics', 'business', 'sports', 'entertainment', 'technology', 'health']Exécutez la classification en passant vos échantillons de texte et étiquettes candidates au classifieur. Le modèle renvoie des scores de probabilité pour chaque étiquette, indiquant à quel point le texte s'aligne avec chaque catégorie. Vous pouvez traiter ces résultats pour attribuer l'étiquette de plus haute probabilité à chaque échantillon de texte ou mettre en œuvre un filtrage basé sur un seuil pour exclure les classifications à faible confiance.
# Effectuer la classification
classification_results = classifier(headline_samples, candidate_labels)
# Analyser et afficher les résultats
for i, result in enumerate(classification_results):
top_label = result['labels'][0]
confidence = result['scores'][0]
print(f"Échantillon {i+1}: {headline_samples[i][:50]}...")
print(f"Prédit : {top_label} (confiance : {confidence:.3f})")
print("---")Tarification et licence de Hugging Face
La bibliothèque principale Hugging Face Transformers et la plupart des modèles pré-entraînés sont disponibles sous des licences open-source, principalement Apache 2.0, permettant une utilisation gratuite pour les applications de recherche et commerciales. Cette accessibilité a été instrumentale dans l'adoption généralisée des modèles de transformateurs à travers les industries. La nature open-source permet aux développeurs d'inspecter, de modifier et d'étendre la base de code pour répondre à des exigences spécifiques sans restrictions de licence ou coûts.
Pour les utilisateurs d'entreprise nécessitant des capacités améliorées, Hugging Face propose des services premium incluant des API d'inférence accélérées, un support expert dédié et un hébergement de modèles privés. Ces services fonctionnent généralement sur des modèles d'abonnement avec une tarification basée sur le volume d'utilisation et les fonctionnalités requises. L'API d'inférence fournit une infrastructure de déploiement optimisée avec des SLA de performance garantis, tandis que le support expert offre un accès direct à l'équipe technique de Hugging Face pour une assistance avec les implémentations complexes et les défis d'optimisation. Ces services sont particulièrement précieux pour les organisations utilisant des solutions d'hébergement de modèles IA à grande échelle.
Avantages et inconvénients
Avantages
- Élimine le besoin d'étiquetage de données coûteux et chronophage
- Adaptable instantanément à de nouvelles catégories sans réentraînement du modèle
- Capacité de déploiement rapide pour la preuve de concept et la production
- Solution rentable pour les organisations avec des ressources ML limitées
- Excellentes performances sur la classification de texte de domaine général
- Évolutif à travers plusieurs langues et types de texte
- Amélioration continue à mesure que les modèles de base reçoivent des mises à jour
Inconvénients
- Précision inférieure par rapport aux modèles supervisés avec des données étiquetées abondantes
- Variabilité des performances à travers différents domaines et types de texte
- Dépendance à la qualité et à la spécificité des étiquettes candidates
- Contrôle limité sur le comportement du modèle et les frontières de décision
- Biais potentiel hérité des sources de données de pré-entraînement
Applications et cas d'utilisation réels
La classification de texte zero-shot trouve des applications dans de nombreuses industries et scénarios où une catégorisation de texte rapide et flexible est précieuse. Dans les systèmes de gestion de contenu, elle permet l'étiquetage automatique d'articles, de billets de blog et de documents sans intervention manuelle. Les organisations de presse tirent parti de la classification zero-shot pour catégoriser les articles entrants en sections thématiques, tandis que les plateformes de commerce électronique l'utilisent pour organiser les avis sur les produits et les retours des clients par thème ou sentiment.
Les opérations de service client bénéficient du routage automatique des tickets de support et des demandes vers les départements appropriés basé sur l'analyse du contenu. Les plateformes de médias sociaux et les communautés en ligne emploient la classification zero-shot pour la modération de contenu, identifiant le matériel inapproprié ou catégorisant le contenu généré par les utilisateurs. Les institutions de recherche utilisent la technique pour organiser les articles académiques et la littérature scientifique par domaine ou méthodologie. Ces applications démontrent la versatilité de la classification zero-shot à travers les agents et assistants IA et divers contextes commerciaux.
Conclusion
La classification de texte zero-shot représente une avancée significative dans le traitement du langage naturel, démocratisant l'accès à des capacités puissantes de catégorisation de texte sans l'exigence traditionnelle de données d'entraînement étiquetées. En exploitant les modèles pré-entraînés de la bibliothèque Transformers de Hugging Face, les développeurs et les organisations peuvent rapidement mettre en œuvre des systèmes de classification flexibles qui s'adaptent aux besoins évolutifs. Bien que l'approche ne corresponde pas toujours à la précision des méthodes entièrement supervisées avec des données étiquetées abondantes, sa flexibilité, sa rapidité et sa rentabilité la rendent inestimable pour de nombreuses applications pratiques. À mesure que les modèles de langage continuent de s'améliorer, les capacités de classification zero-shot s'étendront probablement davantage, ouvrant de nouvelles possibilités pour le traitement intelligent du texte à travers les industries et les cas d'utilisation. Pour ceux qui explorent diverses solutions IA, des répertoires d'outils IA complets peuvent fournir un contexte supplémentaire et des alternatives.
Questions fréquemment posées
Quels types de texte fonctionnent le mieux pour la classification zero-shot ?
La classification zero-shot fonctionne bien avec du texte de domaine général comme les articles de presse, les avis sur les produits, les e-mails et les publications sur les réseaux sociaux. Le contenu technique ou hautement spécialisé peut nécessiter une adaptation au domaine pour des résultats optimaux.
Combien d'étiquettes candidates dois-je utiliser ?
Utilisez 4-8 étiquettes bien définies et distinctes pour une performance optimale. Trop d'étiquettes non liées peuvent diluer les résultats, tandis que trop peu peuvent ne pas couvrir toutes les catégories pertinentes dans vos données textuelles.
La classification zero-shot surpasse-t-elle toujours la classification traditionnelle ?
Non – avec des données étiquetées abondantes et de haute qualité, les méthodes supervisées atteignent souvent une précision plus élevée. La classification zero-shot excelle lorsque les données étiquetées sont rares, que les catégories changent fréquemment ou que le déploiement rapide est priorisé.
Puis-je améliorer la précision de la classification zero-shot ?
Oui – essayez différents modèles pré-entraînés, affinez les étiquettes candidates pour plus de clarté, utilisez un étiquetage hiérarchique pour les catégories complexes et envisagez un réglage spécifique au domaine avec des données étiquetées limitées lorsqu'elles sont disponibles.
Comment la classification zero-shot gère-t-elle le texte ambigu ?
La classification zero-shot peut avoir du mal avec le texte ambigu, car elle repose sur la similarité sémantique. Utiliser des étiquettes candidates plus claires et du contexte peut aider à améliorer la précision dans de tels cas.
Articles pertinents sur l'IA et les tendances technologiques
Restez à jour avec les dernières informations, outils et innovations qui façonnent l'avenir de l'IA et de la technologie.
Grok AI : Génération Illimitée de Vidéos Gratuite à partir de Texte et d'Images | Guide 2024
Grok AI propose une génération illimitée de vidéos gratuite à partir de texte et d'images, rendant la création de vidéos professionnelles accessible à tous sans compétences en montage.
Configuration de Grok 4 Fast sur Janitor AI : Guide Complet de Jeu de Rôle Sans Filtre
Guide étape par étape pour configurer Grok 4 Fast sur Janitor AI pour un jeu de rôle sans restriction, incluant la configuration de l'API, les paramètres de confidentialité et les conseils d'optimisation
Top 3 des extensions de codage IA gratuites pour VS Code 2025 - Boostez votre productivité
Découvrez les meilleures extensions d'agents de codage IA gratuites pour Visual Studio Code en 2025, y compris Gemini Code Assist, Tabnine et Cline, pour améliorer votre