Annotation
- Введение
- Обзор ключевых моментов
- 1) Конвейер RAG и чат-бот (Retrieval Augmented Generation)
- 2) Автоматизация рабочего процесса поддержки клиентов
- 3) Автоматизация создания контента для LinkedIn
- Понимание основных технологий
- Создание конвейера RAG и чат-бота: Пошаговая реализация
- Плюсы и минусы
- Заключение
- Часто задаваемые вопросы
n8n AI Рабочие процессы: Пошаговое руководство по созданию мощной автоматизации
Узнайте, как создавать автоматизацию на основе ИИ с помощью n8n для конвейеров RAG, поддержки клиентов и контента LinkedIn. Пошаговое руководство с практическими
Введение
В сегодняшнем быстро развивающемся цифровом ландшафте автоматизация стала необходимой для оптимизации операций и максимизации организационной эффективности. n8n, мощная платформа с открытым исходным кодом для автоматизации рабочих процессов, позволяет пользователям подключать различные сервисы и создавать пользовательские решения на основе ИИ без необходимости обширных знаний в программировании. Это всеобъемлющее руководство исследует три практических рабочих процесса ИИ, которые можно построить с использованием n8n, предоставляя подробные пошаговые инструкции, чтобы помочь вам внедрить эффективные стратегии автоматизации в вашем бизнесе или личных проектах.
Обзор ключевых моментов
- Создание конвейера Retrieval Augmented Generation (RAG) и чат-бота с использованием Pinecone, Google Drive и n8n
- Создание автоматизированного рабочего процесса поддержки клиентов с использованием Gmail, n8n AI Agent и Open Router
- Автоматизация создания контента для LinkedIn с помощью Tavily, Google Sheets и n8n AI Agent
- Понимание основных концепций, таких как векторные базы данных и Retrieval Augmented Generation (RAG)
- Настройка учетных данных и эффективное подключение различных сервисов в n8n
1) Конвейер RAG и чат-бот (Retrieval Augmented Generation)
Первый рабочий процесс, который мы рассмотрим, — это система конвейера Retrieval Augmented Generation (RAG) и чат-бота. RAG представляет собой продвинутую структуру ИИ, специально разработанную для улучшения качества и точности ответов, генерируемых большими языковыми моделями (LLM). По сути, RAG включает извлечение релевантной информации из внешних баз знаний и использование этих контекстных данных для дополнения существующих знаний LLM перед генерацией ответов. Этот подход значительно уменьшает галлюцинации и улучшает фактическую точность в контенте, создаваемом ИИ. В этой конкретной реализации рабочего процесса мы используем Pinecone в качестве нашей векторной базы данных, подключаемся к Google Drive и Google Docs для управления документами и применяем Open Router для доступа к различным моделям ИИ, включая модели от OpenAI и Anthropic.
- Pinecone: Специализированная векторная база данных, которая хранит данные в виде высокоразмерных векторов, обеспечивая эффективный поиск сходства и операции извлечения, crucial для реализаций RAG.
- Google Drive и Google Docs: Эти знакомые инструменты продуктивности служат доступными источниками данных для создания всеобъемлющих баз знаний, которые питают систему RAG.
- Open Router: Эта универсальная платформа обеспечивает бесшовное подключение к нескольким моделям ИИ, предоставляя гибкость в выборе модели и оптимизации затрат для различных случаев использования.
Конвейеры RAG значительно улучшают точность, релевантность и контекстное понимание чат-ботов ИИ, предоставляя им доступ к внешним, актуальным источникам информации. Основная цель — создать чат-боты ИИ, которые не только более эффективны в своих ответах, но и лучше информированы о конкретных доменах или организационных знаниях. Это делает их особенно ценными для приложений обслуживания клиентов, внутреннего управления знаниями и специализированных консультационных услуг, где точность и специфичность домена являются критическими требованиями.
2) Автоматизация рабочего процесса поддержки клиентов
Второй рабочий процесс расширяет основу RAG для создания комплексной системы автоматизации поддержки клиентов. Этот улучшенный рабочий процесс расширяет предыдущую реализацию, активно читая и извлекая данные из векторной базы данных Pinecone для генерации контекстно соответствующих ответов на запросы клиентов. Интегрируя сервисы, такие как Gmail и n8n AI Agents, этот рабочий процесс автоматически ищет релевантную информацию в векторной базе данных и формулирует точные, полезные ответы, которые могут быть отправлены непосредственно клиентам, значительно упрощая ваши операции поддержки клиентов и сокращая время ответа.
- Интеграция Gmail: Для эффективного получения входящих писем от клиентов и автоматической отправки персонализированных, точных ответов на основе извлеченной информации из базы знаний.
- n8n AI Agent: Для интеллектуальной обработки запросов клиентов, формулирования контекстно соответствующих ответов и обеспечения постоянного качества в коммуникациях с клиентами.
Автоматизируя первоначальный ответ на письма клиентов, организации могут значительно сократить объем тикетов поддержки, требующих вмешательства человека, позволяя командам поддержки сосредоточиться на более сложных проблемах, которые действительно требуют человеческого опыта и эмоционального интеллекта. Этот подход не только улучшает эффективность, но и повышает удовлетворенность клиентов за счет более быстрого времени ответа и последовательной доставки информации во всех взаимодействиях с клиентами.

3) Автоматизация создания контента для LinkedIn
Финальный рабочий процесс демонстрирует практическое применение для автоматизации создания и распространения контента в LinkedIn. Стратегически интегрируя инструменты, такие как Tavily для исследований и Google Sheets для управления данными, этот рабочий процесс использует n8n AI Agent и Open Router для исследования тем, генерации увлекательного контента и автоматического планирования публикаций. Эта автоматизация позволяет профессионалам и бизнесам поддерживать постоянное присутствие в LinkedIn с минимальными ручными усилиями, обеспечивая регулярную публикацию контента, которая стимулирует вовлеченность и строит профессиональный авторитет в их отрасли или нише.
- Интеграция Tavily: Используется для выполнения комплексных веб-поисков и предоставления актуального, релевантного контента агенту ИИ для создания контента и исследования тем.
- Google Sheets: Служит централизованным хранилищем для хранения исследовательских данных, идей контента, метрик производительности и информации о планировании.
Этот сложный рабочий процесс позволяет пользователям эффективно исследовать трендовые темы, генерировать убедительный и релевантный контент и планировать публикации в соответствии с оптимальным временем для вовлеченности, тем самым максимизируя их видимость и влияние в LinkedIn без необходимости постоянного ручного вмешательства. Автоматизация обеспечивает постоянное качество контента и частоту публикаций, которые являются crucial факторами для построения вовлеченности аудитории и профессиональной достоверности на платформе.
Понимание основных технологий
Объяснение векторных баз данных
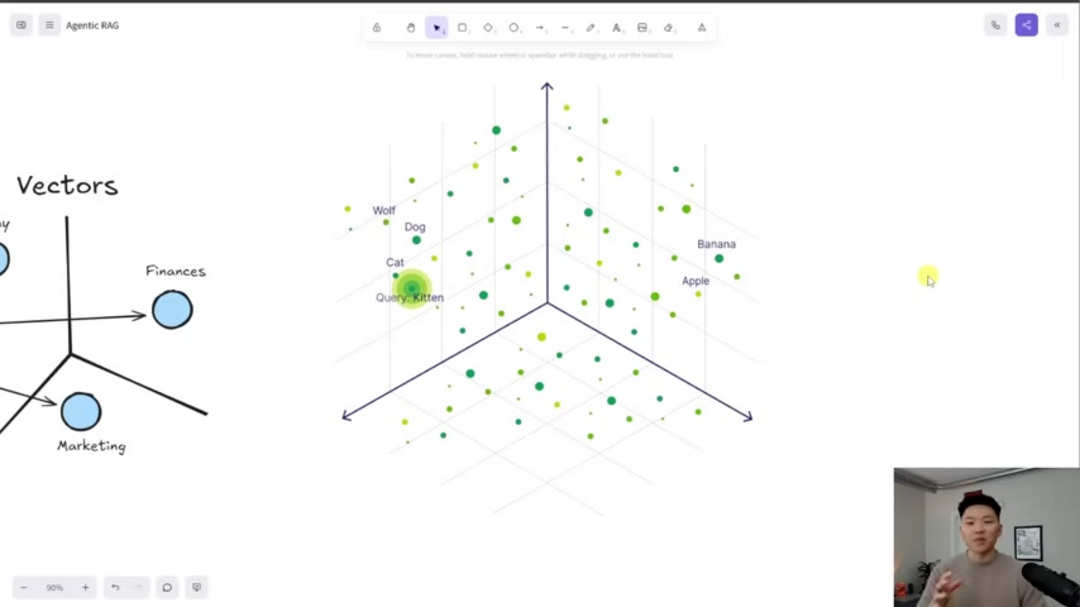
Векторные базы данных, такие как Pinecone, представляют специализированные системы баз данных, специально разработанные для хранения и индексации данных в виде высокоразмерных векторов. Эти математические векторы эффективно захватывают семантическое значение и контекстные отношения внутри данных, обеспечивая высокоэффективный поиск сходства и операции семантического сопоставления. В продвинутых приложениях ИИ векторные базы данных служат критической инфраструктурой для хранения эмбеддингов, генерируемых языковыми моделями, облегчая быстрое извлечение релевантной информации для задач, таких как реализации RAG, семантический поиск и системы рекомендаций контента.
Векторное хранение данных позволяет представлять информацию в многомерных математических пространствах, принципиально отличающихся от традиционных реляционных баз данных, которые используют табличные структуры. Этот многомерный подход преодолевает ограничения стандартных графиков с осями X и Y, с которыми люди обычно сталкиваются, позволяя гораздо более сложное распознавание паттернов и отображение отношений. Эта технологическая основа позволяет создавать высоко способные чат-боты и виртуальные помощники ИИ, значительно улучшая их понимание и возможности ответа в различных доменах и типах запросов.
Платформа Open Router
Open Router функционирует как уровень абстракции, который агрегирует доступ к различным большим языковым моделям (LLM) через унифицированный интерфейс. Этот архитектурный подход позволяет пользователям бесшовно переключаться между различными моделями ИИ, такими как модели от OpenAI, Anthropic и других поставщиков, без сложности управления множественными интеграциями API и системами аутентификации. Используя Open Router в рабочих процессах n8n, организации могут достичь большей гибкости, улучшенной устойчивости и повышенной рентабельности, так как они могут динамически выбирать наиболее подходящую модель ИИ для конкретных задач на основе требований производительности, соображений затрат и доступности.
Возможности поиска Tavily
Tavily представляет собой специализированную поисковую систему, которая предоставляет продвинутые возможности веб-скрапинга через удобный для разработчиков API интерфейс. Она специально разработана для того, чтобы позволить системам ИИ эффективно получать доступ и использовать данные в реальном времени из интернета. Tavily выполняет комплексные веб-поиски, извлекает структурированные данные с веб-сайтов и бесшовно интегрирует эту информацию в рабочие процессы на основе ИИ. Эта возможность значительно увеличивает точность и релевантность контента, генерируемого ИИ, предоставляя доступ к актуальной информации, что делает ее особенно ценной для задач, требующих обновленных данных, таких как анализ новостей, исследование рынка и мониторинг трендов в различных отраслях и темах.
Создание конвейера RAG и чат-бота: Пошаговая реализация
Шаг 1: Настройка Google Drive в качестве триггера
Чтобы инициировать рабочий процесс, начните с настройки триггера Google Drive в n8n. Этот триггер будет непрерывно отслеживать указанную папку в вашем аккаунте Google Drive на наличие новых документов или изменений файлов. Эта настройка гарантирует, что всякий раз, когда новый документ добавляется в назначенную папку, рабочий процесс автоматически активируется, создавая отзывчивую и событийно-управляемую систему автоматизации, которая не требует ручного вмешательства для начала обработки.
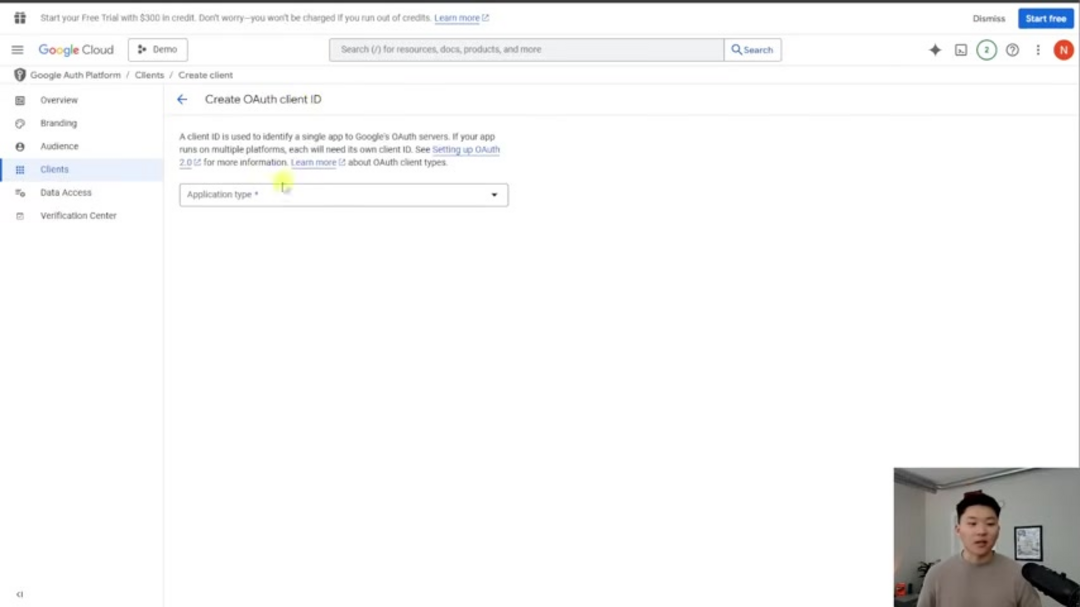
Шаг 2: Установление подключения к Google Drive
Далее создайте новые учетные данные Google Sheets в n8n и заполните необходимую информацию для аутентификации. Этот процесс включает создание проекта в Google Cloud Console, включение API Google Drive и правильную настройку экрана согласия OAuth с соответствующими разрешениями и областями. Эти технические шаги включают предоставление Google необходимой информации о том, как n8n будет безопасно подключаться к вашему аккаунту Google, сохраняя стандарты конфиденциальности и безопасности данных на протяжении всего процесса интеграции.
Шаг 3: Реализация функциональности загрузки файлов
Используйте ранее настроенный триггер Google Drive для автоматической загрузки файлов и установления безопасных подключений с вашим аккаунтом Google Drive. Эта реализация включает динамическое извлечение идентификаторов файлов с использованием системы переменных n8n, позволяя рабочему процессу гибко обрабатывать различные файлы, а не быть ограниченным одним статическим файлом. Этот динамический подход обеспечивает масштабируемость и адаптируемость по мере роста и эволюции вашей коллекции документов со временем.
Шаг 4: Интеграция векторной базы данных
Чтобы реализовать полную функциональность RAG, вам потребуется интегрировать векторную базу данных, такую как Pinecone, для обработки и хранения ваших Google Documents в виде поисковых векторов. После завершения процесса регистрации в Pinecone сгенерируйте безопасный API-ключ и правильно настройте эти учетные данные аутентификации в узле Pinecone Vector Store в n8n. Эта интеграция формирует ядро вашей системы RAG, обеспечивая возможности семантического поиска по вашей коллекции документов.
Шаг 5: Подключение n8n к Pinecone
После получения вашего API-ключа Pinecone вы должны определить, как n8n будет интегрироваться с инфраструктурой векторной базы данных. Это включает настройку узлов обработки текста, которые преобразуют содержимое документов в числовые векторные представления (обычно через процессы чанкинга и эмбеддинга). После преобразования эти контекстные векторы эффективно хранятся в Pinecone, создавая поисковую базу знаний, которую ваши приложения ИИ могут запрашивать для релевантной информации во время генерации ответов.
Шаг 6: Включение возможностей AI Agent
Используйте узлы ИИ n8n, такие как узел "Use Open AI", для установления подключений к большим языковым моделям для генерации и обработки текста. Современные LLM используют сложные системы, включая механизмы памяти и интеграцию внешних инструментов, чтобы улучшить их контекстное понимание и качество ответов. После настройки тщательно протестируйте AI Agent с различными типами запросов, чтобы проверить точность ответов и усовершенствовать систему на основе наблюдений за производительностью и требований пользователей.
Плюсы и минусы
Преимущества
- Значительно сокращает ручную нагрузку за счет интеллектуальной автоматизации
- Улучшает точность ответов с Retrieval Augmented Generation
- Обеспечивает бесшовную интеграцию между множеством платформ и сервисов
- Предоставляет рентабельную автоматизацию без обширных требований к программированию
- Предлагает гибкость для легкого переключения между различными моделями ИИ
- Улучшает обслуживание клиентов за счет более быстрого времени ответа
- Поддерживает постоянное качество контента во всех автоматизированных выходах
Недостатки
- Требует начального времени настройки и технической конфигурации
- Зависит от доступности сторонних API и лимитов скорости
- Может потребовать постоянного обслуживания по мере обновления API сервисов
- Начальная кривая обучения для понимания принципов дизайна рабочих процессов
- Потенциальные затраты, связанные с использованием премиальных моделей ИИ
Заключение
n8n предоставляет мощную и доступную платформу для реализации сложных рабочих процессов ИИ, которые могут преобразовать подход организаций к автоматизации. Три рабочих процесса, подробно описанные в этом руководстве – чат-боты на основе RAG, автоматизация поддержки клиентов и создание контента для LinkedIn – демонстрируют универсальность и практическую применимость платформы. Следуя пошаговым инструкциям по реализации, пользователи могут создавать эффективные решения автоматизации, которые улучшают эффективность, улучшают опыт клиентов и стимулируют рост бизнеса. По мере развития технологии ИИ гибкая архитектура n8n гарантирует, что ваши стратегии адаптируются к возникающим вызовам.
Часто задаваемые вопросы
Какова цель Tavily в рабочих процессах n8n?
Tavily предоставляет возможности веб-поиска в реальном времени для приложений ИИ, позволяя рабочим процессам получать доступ к актуальной информации из Интернета для генерации точного, современного контента и исследований.
Как я могу повысить точность рабочего процесса поддержки клиентов?
Повысьте точность, добавив прошлые заявки клиентов в вашу базу знаний, регулярно обновляя шаблоны ответов и обучая ИИ на примерах успешного разрешения, чтобы со временем улучшить качество ответов.
Можно ли полностью автоматизировать контент LinkedIn в n8n?
Да, реализуя триггеры на основе времени, n8n может автоматически исследовать, создавать и планировать публикации в LinkedIn без ручного вмешательства, обеспечивая постоянную публикацию контента.
Что такое n8n и как он работает?
n8n — это платформа автоматизации рабочих процессов с низким кодом, которая соединяет приложения и службы через визуальные рабочие процессы, позволяя пользователям создавать пользовательские автоматизации без обширных знаний программирования.
Можно ли интегрировать ChatGPT с рабочими процессами n8n?
Да, n8n легко интегрируется с ChatGPT от OpenAI и другими моделями ИИ через узлы и API, обеспечивая обработку естественного языка и генерацию текста в автоматизированных рабочих процессах.
Релевантные статьи об ИИ и технологических трендах
Будьте в курсе последних инсайтов, инструментов и инноваций, формирующих будущее ИИ и технологий.
Grok AI: Бесплатное неограниченное создание видео из текста и изображений | Руководство 2024
Grok AI предлагает бесплатное неограниченное создание видео из текста и изображений, делая профессиональное создание видео доступным для всех без навыков редактирования.
Настройка Grok 4 Fast в Janitor AI: Полное руководство по ролевой игре без фильтров
Пошаговое руководство по настройке Grok 4 Fast в Janitor AI для неограниченной ролевой игры, включая настройку API, параметры конфиденциальности и советы по оптимизации
Топ-3 бесплатных расширений для ИИ-программирования в VS Code 2025 - Повышение производительности
Откройте для себя лучшие бесплатные расширения для ИИ-программирования в Visual Studio Code в 2025 году, включая Gemini Code Assist, Tabnine и Cline, чтобы улучшить вашу