Annotation
- Введение
- Сила письменного языка и решений на основе данных
- Проблема неструктурированных данных
- Историческая перспектива записи данных
- От OCR к интеллекту документов: эволюция и вызовы
- Модели GPT: прорыв в понимании документов
- Использование LLM и агентов ИИ для интеллекта документов
- Плюсы и минусы
- Заключение
- Часто задаваемые вопросы
Искусственный интеллект для документов: Преобразуйте неструктурированные данные в бизнес-инсайты
Искусственный интеллект для документов использует модели GPT и машинное обучение для извлечения инсайтов из неструктурированных данных, таких как контракты и отчеты, обеспечивая
Введение
В современном бизнес-ландшафте, основанном на данных, организации сталкиваются с критической проблемой: извлечение значимых инсайтов из огромных объемов неструктурированных данных, скрытых в документах. От контрактов и отчетов до электронных писем и счетов-фактур, эта информация представляет неиспользованный потенциал для принятия обоснованных решений. Решения на основе искусственного интеллекта для анализа документов революционизируют то, как компании обрабатывают, анализируют и используют эти данные, превращая хаотичный текст в структурированную, действенную информацию, которая повышает операционную эффективность и стратегическое преимущество.
Сила письменного языка и решений на основе данных
Письменный язык представляет собой одно из самых значительных технологических достижений человечества, эволюционировав от древних наскальных рисунков до современных цифровых документов. Эрик Притчетт, президент/COO компании Terzo, подчеркивает, что письменная коммуникация служит основой для записи истории, обмена знаниями и накопления коллективной мудрости. Каждое достижение – от иероглифов до печатного станка Гутенберга и современных цифровых форматов – постепенно улучшало нашу способность передавать сложные идеи и сохранять институциональные знания. В современных бизнес-средах проблема сместилась от простой записи информации к эффективному извлечению из нее ценности. Организации ежегодно генерируют миллионы документов, однако большинство из них остаются неиспользованными из-за их неструктурированной природы. Это представляет огромную возможность для платформ автоматизации на основе ИИ изменить то, как компании используют свои документированные активы знаний.
Проблема неструктурированных данных
Неструктурированные документы представляют сложный ландшафт для традиционных систем обработки данных. В отличие от структурированных баз данных с предопределенными полями и отношениями, документы содержат свободный текст, различное форматирование, таблицы и контекстуальную информацию, которую машины с трудом интерпретируют последовательно. Эти неструктурированные данные охватывают все: от юридических контрактов со специализированной терминологией до финансовых отчетов, содержащих сложные числовые отношения. Разнообразие типов документов создает значительные проблемы обработки, включая контракты с различными юридическими оговорками, финансовые отчеты со встроенными таблицами, техническую документацию со специализированной лексикой и клиентские коммуникации с неформальными языковыми шаблонами. Традиционные подходы требуют обширного ручного просмотра и ввода данных, создавая узкие места и увеличивая риск человеческой ошибки. Именно здесь агенты и ассистенты ИИ демонстрируют свою ценность, автоматизируя процесс извлечения и структурирования.
Историческая перспектива записи данных
Путь человечества с записью данных раскрывает устойчивую модель технологических инноваций, направленных на сохранение и обмен информацией. Ранние цивилизации использовали наскальные рисунки для документирования успехов охоты и сезонных закономерностей, в то время как древние египтяне разработали иероглифы для записи административных и религиозных текстов. Эти ранние системы установили фундаментальную потребность в надежной документации, которая сохраняется в современных бизнес-контекстах. Печатная революция демократизировала доступ к письменным знаниям, а ксерокопирование и цифровые форматы еще больше ускорили распространение информации. Сегодня мы находимся на очередном переломном моменте, когда системы на основе ИИ могут не только хранить и распространять документы, но и понимать их содержание и автоматически извлекать значимые инсайты. Современные инструменты редактирования документов включают эти интеллектуальные возможности непосредственно в рабочие процессы.
От OCR к интеллекту документов: эволюция и вызовы
Технология оптического распознавания символов представляла собой важный шаг вперед в оцифровке документов, позволяя преобразовывать сканированные изображения в машиночитаемый текст. Однако OCR работает на поверхностном уровне – она распознает символы и слова, но не понимает их значение или отношения. При обработке сложных документов, таких как счета-фактуры или контракты, OCR генерирует сырой текст без понимания семантических связей между точками данных. Рассмотрим, как OCR обрабатывает финансовую таблицу: она точно идентифицирует числа и метки, но не распознает, что «Выручка за 3 квартал» относится к «2,4 млн долл.» в соседней ячейке. Это ограничение становится особенно проблематичным при многоколоночных макетах, рукописных аннотациях, сканах низкого разрешения и документах со смешанными языками. Эти ограничения подчеркивают необходимость в более сложных решениях, которые выходят за рамки распознавания символов к подлинному пониманию документов. Современные платформы интеллекта документов представляют собой квантовый скачок по сравнению с базовой технологией OCR. Комбинируя обработку естественного языка, машинное обучение и компьютерное зрение, эти системы могут понимать содержание документов на концептуальном уровне. Они не просто читают текст – они понимают контекст, идентифицируют сущности, извлекают отношения и классифицируют информацию согласно бизнес-правилам. Возможности включают семантическое понимание, интеллектуальное извлечение данных, классификацию документов, отображение отношений и проверку качества. Эти возможности делают интеллект документов особенно ценным для рабочих процессов редактирования и обработки PDF, где документы часто содержат критическую бизнес-информацию.
Модели GPT: прорыв в понимании документов
Генеративные предварительно обученные трансформеры революционизировали интеллект документов, привнося человеческое понимание в автоматизированные системы. Эти большие языковые модели, обученные на массивных корпусах текстов, демонстрируют замечательную способность понимать нюансы, контекст и тонкие языковые паттерны, которые ускользали от предыдущих технологий. Модели GPT преуспевают в контекстуальном понимании специализированной терминологии, идентификации подразумеваемых отношений, суммировании сложных документов, адаптации к различным стилям письма и генерации структурированных выходных данных из неструктурированных входных. Техническая архитектура включает слои эмбеддингов, механизмы внимания, блоки трансформеров, слои нормализации и проекции выходных данных, которые работают согласованно для эффективной обработки информации.
Использование LLM и агентов ИИ для интеллекта документов
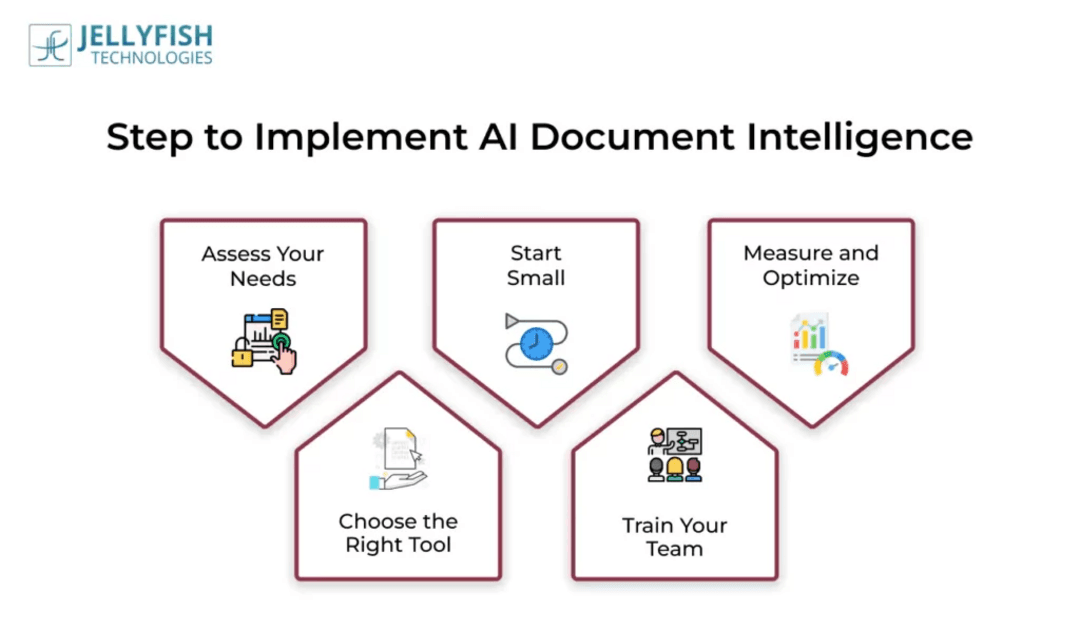
Внедрение эффективной системы интеллекта документов требует тщательного планирования и стратегического выполнения. Организации должны подходить к этой трансформации методично, чтобы обеспечить успешное внедрение и максимальную отдачу от инвестиций. Ключевые шаги включают определение четких целей, выбор подходящей технологии, подготовку данных, внедрение постепенной автоматизации, интеграцию с бизнес-системами, установление протоколов мониторинга и планирование эволюции. Успешное внедрение часто включает использование API и SDK ИИ для создания пользовательских интеграций, которые решают конкретные организационные потребности. Ландшафт цен на решения для интеллекта документов варьируется в зависимости от модели развертывания, набора функций и требований масштаба, причем такие факторы, как ценообразование на основе объема, уровни функций, варианты развертывания и услуги поддержки, влияют на затраты. Многие поставщики предлагают гибкие модели, включая плату за документ, ежемесячные подписки и корпоративные соглашения.
Плюсы и минусы
Преимущества
- Значительно сокращает время ручного ввода и обработки данных
- Улучшает точность и согласованность данных по различным типам документов
- Обеспечивает более быстрое принятие решений с извлечением данных в реальном времени
- Эффективно масштабируется для обработки растущих объемов документов
- Выявляет паттерны и инсайты, скрытые в неструктурированных данных
- Снижает операционные затраты за счет автоматизации повторяющихся задач
- Улучшает соответствие требованиям за счет последовательной обработки документов
Недостатки
- Требует первоначальных инвестиций в технологию и внедрение
- Может производить ошибки во время начального развертывания и обучения
- Требует постоянного обслуживания и доработки моделей
- Может внести предвзятость, если обучающие данные не репрезентативны
- Требует технической экспертизы для оптимальной конфигурации
Заключение
Интеллект документов на основе ИИ представляет собой трансформационную технологию, которая решает одну из самых устойчивых проблем бизнеса: раскрытие ценности, запертой в неструктурированных документах. Переходя от базового распознавания символов к подлинному пониманию, эти системы позволяют организациям автоматизировать сложные рабочие процессы обработки документов, извлекать действенные инсайты и принимать решения на основе данных с беспрецедентной скоростью и точностью. По мере того как технология продолжает развиваться, компании, которые принимают интеллект документов, получат значительные конкурентные преимущества за счет улучшенной эффективности, сниженных затрат и расширенных возможностей принятия решений во всех операционных областях.
Часто задаваемые вопросы
Что такое интеллект документов и чем он отличается от базового OCR?
Интеллект документов выходит за рамки простого OCR, используя технологии ИИ, такие как обработка естественного языка и машинное обучение, для понимания содержания документов, извлечения конкретных точек данных, выявления взаимосвязей и автоматизации принятия решений на основе всестороннего анализа документов.
Как модели GPT улучшают возможности интеллекта документов?
Модели GPT привносят человеческое понимание в интеллект документов, понимая контекст, нюансы и специализированную терминологию. Они могут выявлять подразумеваемые отношения, суммировать сложные документы и адаптироваться к различным стилям письма, которые бросают вызов традиционным методам обработки.
Какие шаги должны предпринять организации при внедрении интеллекта документов?
Успешное внедрение начинается с определения бизнес-целей, выбора подходящей технологии, подготовки данных, постепенной автоматизации, интеграции с бизнес-системами, установления протоколов мониторинга и планирования эволюции для обеспечения долгосрочного успеха.
Каковы ключевые преимущества искусственного интеллекта для документов для бизнеса?
Искусственный интеллект для документов сокращает ручной ввод данных, повышает точность, обеспечивает более быстрое принятие решений, эффективно масштабируется, выявляет скрытые инсайты, снижает операционные расходы и улучшает соответствие требованиям за счет автоматизированной и последовательной обработки документов.
Насколько точна обработка документов на основе ИИ по сравнению с ручными методами?
Обработка документов на основе ИИ может достигать высоких показателей точности, часто превосходя ручные методы, особенно для повторяющихся задач, но требует надлежащего обучения, качественных данных и постоянного совершенствования для минимизации ошибок и адаптации к сложным документам.
Релевантные статьи об ИИ и технологических трендах
Будьте в курсе последних инсайтов, инструментов и инноваций, формирующих будущее ИИ и технологий.
Grok AI: Бесплатное неограниченное создание видео из текста и изображений | Руководство 2024
Grok AI предлагает бесплатное неограниченное создание видео из текста и изображений, делая профессиональное создание видео доступным для всех без навыков редактирования.
Настройка Grok 4 Fast в Janitor AI: Полное руководство по ролевой игре без фильтров
Пошаговое руководство по настройке Grok 4 Fast в Janitor AI для неограниченной ролевой игры, включая настройку API, параметры конфиденциальности и советы по оптимизации
Топ-3 бесплатных расширений для ИИ-программирования в VS Code 2025 - Повышение производительности
Откройте для себя лучшие бесплатные расширения для ИИ-программирования в Visual Studio Code в 2025 году, включая Gemini Code Assist, Tabnine и Cline, чтобы улучшить вашу