Annotation
- Введение
- Понимание проблемы обнаружения дипфейков
- Стратегия набора данных для надежного обучения модели
- Реализация архитектуры Vision Transformer
- Оценка производительности и анализ метрик
- Архитектура полного стека развертывания
- Сквозной рабочий процесс пользователя
- Практические приложения и варианты использования
- Техническая основа: Революция трансформеров
- Плюсы и минусы
- Заключение
- Часто задаваемые вопросы
Проект обнаружения дипфейк-изображений: руководство по реализации Vision Transformer
Полное руководство по созданию системы обнаружения дипфейк-изображений с использованием Vision Transformers, охватывающее подготовку данных, обучение модели, оценку

Введение
По мере того как искусственный интеллект продолжает развиваться, способность отличать подлинный визуальный контент от манипулированного становится все более критически важной. Это всеобъемлющее руководство исследует полный проект глубокого обучения, который использует передовую архитектуру трансформера для обнаружения дипфейк-изображений с замечательной точностью. От подготовки данных до веб-развертывания, мы пройдем через каждый компонент построения надежной системы обнаружения дипфейков, которая сочетает современные методы ИИ с практическими стратегиями реализации.
Понимание проблемы обнаружения дипфейков
Технология дипфейков представляет собой одну из самых значительных проблем в области аутентичности цифровых медиа сегодня. Эти манипуляции, созданные ИИ, могут варьироваться от тонких изменений лица до полных подделок, которые почти неотличимы от реальных изображений для человеческого глаза. Проект, который мы рассматриваем, решает эту проблему напрямую, внедряя сложную систему обнаружения, которая анализирует визуальные артефакты и несоответствия, часто выдающие контент, созданный ИИ. Этот подход особенно актуален для профессионалов, работающих с генераторами изображений ИИ, которым необходимо проверять аутентичность контента.
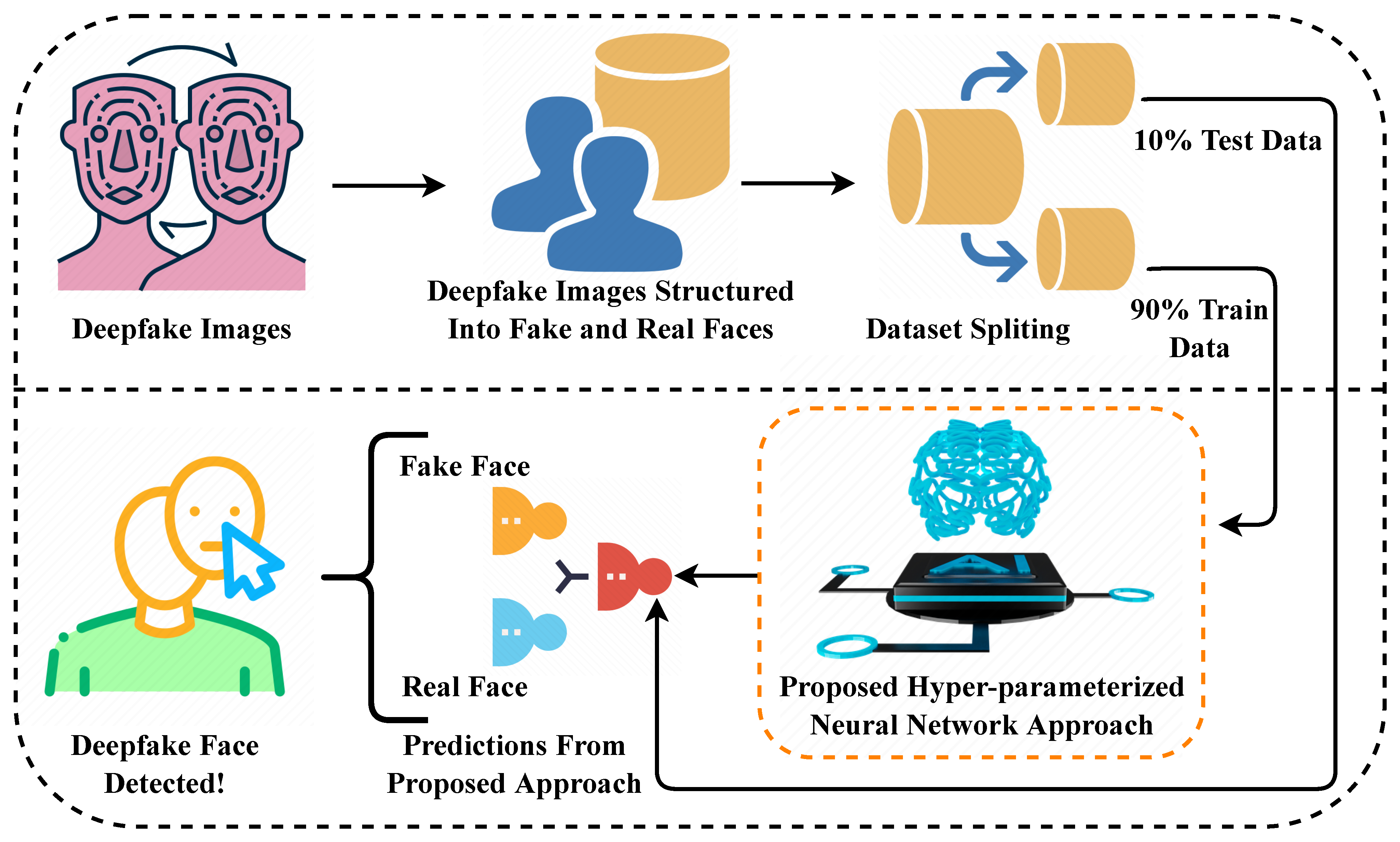
Стратегия набора данных для надежного обучения модели
Основой любой эффективной модели глубокого обучения являются ее обучающие данные. Для этого проекта обнаружения дипфейков набор данных был тщательно отобран, чтобы включить разнообразные примеры как подлинных, так и манипулированных изображений в различных сценариях и уровнях качества. Это разнообразие гарантирует, что модель научится распознавать дипфейки независимо от конкретной техники генерации или тематики изображения.
Набор данных следует структурированному трехчастному разделению, которое необходимо для правильной разработки модели:
- Обучающие данные (70%): Самая большая часть знакомит модель с тысячами разнообразных примеров, обучая ее распознавать тонкие паттерны и артефакты, которые отличают реальные изображения от дипфейков в различных условиях освещения, разрешениях и техниках манипуляции.
- Валидационные данные (15%): Используются во время обучения для мониторинга производительности и предотвращения переобучения, этот поднабор помогает тонко настраивать гиперпараметры и гарантирует, что модель хорошо обобщает, а не запоминает обучающие примеры.
- Тестовые данные (15%): Полностью удерживаются до финальной оценки, эти данные предоставляют объективную оценку того, как модель будет работать на никогда не виденных ранее изображениях в реальных сценариях.
Реализация архитектуры Vision Transformer
В основе этой системы обнаружения лежит модель Vision Transformer (ViT), что представляет значительный отход от традиционных сверточных нейронных сетей для анализа изображений. Архитектура трансформера, изначально разработанная для обработки естественного языка, продемонстрировала замечательную производительность в задачах компьютерного зрения, захватывая дальние зависимости и глобальный контекст внутри изображений.
Процесс реализации в среде Jupyter notebook следует систематическому подходу:
- Настройка окружения: Импорт необходимых библиотек, включая TensorFlow, Keras и специализированные реализации трансформеров, а также инструментов для манипуляции данными и визуализации.
- Построение конвейера данных: Создание эффективных загрузчиков данных, которые обрабатывают изменение размера изображений, нормализацию и техники аугментации, такие как вращение, отражение и корректировка яркости, чтобы улучшить устойчивость модели.
- Конфигурация модели: Определение архитектуры Vision Transformer с подходящими размерами патчей, размерностями встраивания и головками внимания, адаптированными для задачи обнаружения дипфейков.
- Применение трансферного обучения: Использование предварительно обученных весов из крупномасштабных наборов данных изображений и тонкая настройка модели специально для обнаружения дипфейков, что значительно сокращает время обучения и улучшает производительность.
- Оптимизация обучения: Внедрение планирования скорости обучения, ранней остановки и обрезки градиентов для обеспечения стабильной и эффективной сходимости модели.
Оценка производительности и анализ метрик
Оценка модели обнаружения дипфейков требует комплексных метрик, выходящих за рамки простой точности. Проект реализует множественные подходы к оценке, чтобы тщательно оценить производительность модели и выявить потенциальные слабости.
Анализ матрицы ошибок раскрывает критические инсайты о поведении модели:
| Предсказано Реальное | Предсказано Фейковое | |
|---|---|---|
| Истинно Реальное | 37,831 | 249 |
| Истинно Фейковое | 326 | 37,755 |
Эта матрица демонстрирует отличную производительность с минимальными ложными срабатываниями и пропусками. Модель достигает приблизительно 99,2% точности, с метриками точности и полноты, превышающими 99% для обоих классов. Эти результаты указывают на хорошо сбалансированную модель, которая работает последовательно, независимо от того, обнаруживает ли она реальные или фейковые изображения.
Архитектура полного стека развертывания
Чтобы сделать возможности обнаружения дипфейков доступными для конечных пользователей, проект реализует полное веб-приложение с отдельными фронтенд и бэкенд компонентами. Эта архитектура следует современным практикам веб-разработки, обеспечивая эффективное обслуживание модели и отзывчивый пользовательский опыт.
Стек развертывания включает:
- Бэкенд API (Flask): Легковесный веб-фреймворк на Python, который размещает обученную модель и предоставляет RESTful эндпоинты для обработки изображений и предсказаний. Бэкенд обрабатывает предобработку изображений, вывод модели и форматирование результатов, делая его совместимым с различными API и SDK ИИ.
- Фронтенд интерфейс: Отзывчивое веб-приложение, построенное на HTML, CSS и JavaScript, которое предоставляет интуитивно понятный интерфейс перетаскивания для загрузки изображений, индикаторы обработки в реальном времени и четкое представление результатов.
- Оптимизация обслуживания модели: Внедрение механизмов кэширования, очередей запросов и ускорения на GPU для обеспечения быстрого времени отклика даже при высокой нагрузке, аналогично возможностям, найденным в профессиональных платформах хостинга моделей ИИ.
Сквозной рабочий процесс пользователя
Полная система работает через оптимизированный рабочий процесс, который балансирует удобство пользователя с технической надежностью:
- Отправка изображения: Пользователи загружают изображения через веб-интерфейс, с поддержкой распространенных форматов (JPEG, PNG) и автоматической проверкой размера файла и размеров.
- Обработка на бэкенде: Flask API получает изображение, применяет необходимую предобработку (изменение размера, нормализацию) и выполняет конвейер вывода модели.
- Анализ в реальном времени: Vision Transformer обрабатывает изображение, анализируя пространственные отношения и текстуры, чтобы идентифицировать артефакты манипуляции, характерные для техник генерации дипфейков.
- Оценка уверенности: Модель генерирует как классификацию (реальное/фейковое), так и оценку уверенности, которая указывает на определенность предсказания, помогая пользователям понять надежность каждого результата.
- Доставка результата: Фронтенд отображает исход анализа с визуальными индикаторами и пояснительным текстом, делая технические результаты доступными для неэкспертных пользователей.
Практические приложения и варианты использования
Практические применения надежного обнаружения дипфейков распространяются на множество областей, где визуальная аутентичность имеет первостепенное значение. Новостные организации могут интегрировать такие системы для проверки пользовательского контента перед публикацией, в то время как социальные медиа-платформы могли бы развернуть подобные технологии для автоматического маркирования потенциально манипулированных изображений. Юридические и криминалистические профессионалы выигрывают от инструментов, предоставляющих предварительный анализ аутентичности доказательств, хотя экспертный обзор человека остается необходимым для критических случаев. Технология также дополняет существующие инструменты редактора фотографий, добавляя возможности проверки.
В корпоративных средах обнаружение дипфейков помогает защищаться от сложных атак социальной инженерии, использующих манипулированные изображения для обмана идентичности. Образовательные учреждения могут использовать эти системы для обучения цифровой грамотности и навыкам критической оценки медиа. Растущая интеграция подобных технологий в платформы автоматизации ИИ демонстрирует возрастающую важность проверки контента в автоматизированных рабочих процессах.
Техническая основа: Революция трансформеров
Этот проект строится на новаторской работе, представленной в исследовательской статье "Attention Is All You Need", которая представила архитектуру трансформера, с тех пор революционизировавшую как обработку естественного языка, так и компьютерное зрение. Механизм самовнимания в сердце трансформеров позволяет модели динамически взвешивать важность различных областей изображения, делая его особенно эффективным для обнаружения тонких, глобально распределенных артефактов, характеризующих манипуляции дипфейками.
В отличие от традиционных сверточных сетей, которые обрабатывают изображения через локальные фильтры, трансформеры могут захватывать дальние зависимости по всему изображению одновременно. Эта глобальная перспектива критически важна для идентификации несоответствий в освещении, текстурах и анатомических пропорциях, которые часто выдают контент, созданный ИИ. Масштабируемость архитектуры также позволяет ей выигрывать от больших наборов данных и больше вычислительных ресурсов, следуя трендам, наблюдаемым в комплексных каталогах инструментов ИИ, которые отслеживают возможности моделей.
Плюсы и минусы
Преимущества
- Исключительная точность обнаружения, превышающая 99% на тестовых данных
- Комплексная сквозная реализация от данных до развертывания
- Открытая архитектура, позволяющая настройку и расширение
- Архитектура Vision Transformer захватывает глобальный контекст изображения
- Пользовательский веб-интерфейс, доступный для нетехнических пользователей
- Надежная производительность на разнообразных типах и качествах изображений
- Быстрое время вывода, подходящее для приложений реального времени
Недостатки
- Значительные вычислительные требования для обучения
- Требует существенного опыта в машинном обучении для модификации
- Производительность зависит от качества и разнообразия обучающих данных
- Потенциальные ложные срабатывания с сильно сжатыми изображениями
- Ограниченная эффективность против никогда не виденных ранее техник манипуляции
Заключение
Этот проект обнаружения дипфейк-изображений демонстрирует мощное сочетание современной архитектуры трансформера с практической полностековой реализацией. Используя Vision Transformers, система достигает исключительной точности в различении подлинных изображений от манипуляций, созданных ИИ, сохраняя доступность через пользовательский веб-интерфейс. Полный рабочий процесс—от подготовки данных и обучения модели до развертывания и оценки—предоставляет надежную структуру, которая может быть адаптирована к различным сценариям аутентификации изображений. Поскольку технология дипфейков продолжает развиваться, такие системы обнаружения будут играть все более важную роль в поддержании цифрового доверия и борьбе с визуальной дезинформацией на платформах и в отраслях.
Часто задаваемые вопросы
Что такое обнаружение дипфейк-изображений?
Обнаружение дипфейк-изображений использует искусственный интеллект для идентификации изображений, манипулированных методами глубокого обучения, анализируя визуальные артефакты и несоответствия, которые отличают контент, созданный ИИ, от подлинных фотографий.
Насколько точен этот детектор дипфейков?
Детектор на основе Vision Transformer достигает точности более 99% на тестовых наборах данных, со сбалансированной производительностью по классам как реальных, так и поддельных изображений, хотя производительность может варьироваться в зависимости от качества изображения и новых методов манипуляции.
Какие технологии питают эту систему обнаружения?
Система сочетает архитектуру Vision Transformer для анализа изображений, TensorFlow/Keras для глубокого обучения, Flask для бэкенд-API и современные веб-технологии для интерфейса фронтенда, создавая полное полнофункциональное приложение.
Могут ли студенты использовать этот проект для обучения?
Да, проект отлично подходит для образовательных целей, включая курсовые работы, исследовательские проекты или дипломные проекты. Открытый подход позволяет студентам изучать и модифицировать реализацию, изучая современные методы ИИ.
Каковы системные требования?
Для обучения требуются значительные ресурсы GPU, но развернутое веб-приложение может работать на стандартных серверах. Для разработки необходимы Python 3.8+, TensorFlow 2.x и распространенные библиотеки для науки о данных, аналогично многим средам разработки ИИ.
Релевантные статьи об ИИ и технологических трендах
Будьте в курсе последних инсайтов, инструментов и инноваций, формирующих будущее ИИ и технологий.
Grok AI: Бесплатное неограниченное создание видео из текста и изображений | Руководство 2024
Grok AI предлагает бесплатное неограниченное создание видео из текста и изображений, делая профессиональное создание видео доступным для всех без навыков редактирования.
Топ-3 бесплатных расширений для ИИ-программирования в VS Code 2025 - Повышение производительности
Откройте для себя лучшие бесплатные расширения для ИИ-программирования в Visual Studio Code в 2025 году, включая Gemini Code Assist, Tabnine и Cline, чтобы улучшить вашу
Настройка Grok 4 Fast в Janitor AI: Полное руководство по ролевой игре без фильтров
Пошаговое руководство по настройке Grok 4 Fast в Janitor AI для неограниченной ролевой игры, включая настройку API, параметры конфиденциальности и советы по оптимизации