Annotation
- Введение
- Понимание сверточных нейронных сетей для распознавания изображений
- Настройка окружения и необходимые инструменты
- Необходимые библиотеки Python для разработки CNN
- Работа с набором данных CIFAR-10
- Построение архитектуры CNN с Keras
- Компиляция модели и конфигурация обучения
- Практические шаги реализации
- Плюсы и минусы
- Заключение
- Часто задаваемые вопросы
Руководство по распознаванию изображений с помощью CNN: Python, Keras и TensorFlow
Узнайте, как построить сверточную нейронную сеть для распознавания изображений с помощью Python и Keras. Этот учебник охватывает архитектуру CNN, набор данных
Введение
Сверточные нейронные сети преобразовали компьютерное зрение, позволив машинам интерпретировать визуальные данные с беспрецедентной точностью. Это комплексное руководство проведет вас через создание практической CNN для распознавания изображений с использованием Python, Keras и TensorFlow. Мы рассмотрим все от настройки окружения до оценки модели, предоставляя практический опыт с реальной реализацией. Независимо от того, изучаете ли вы уроки по ИИ или создаете производственные системы, это руководство предоставляет полезные знания для эффективных решений по распознаванию изображений.
Понимание сверточных нейронных сетей для распознавания изображений
Сверточные нейронные сети представляют собой специализированную архитектуру, разработанную специально для обработки визуальных данных. В отличие от традиционных нейронных сетей, которые обрабатывают входные данные как плоские векторы, CNN сохраняют пространственные отношения через свою уникальную структуру слоев. Эта пространственная осведомленность позволяет им обнаруживать паттерны, края и текстуры способами, имитирующими человеческую визуальную обработку. Иерархическая способность извлечения признаков делает CNN особенно эффективными для сложных визуальных задач, где важны контекст и пространственные отношения.
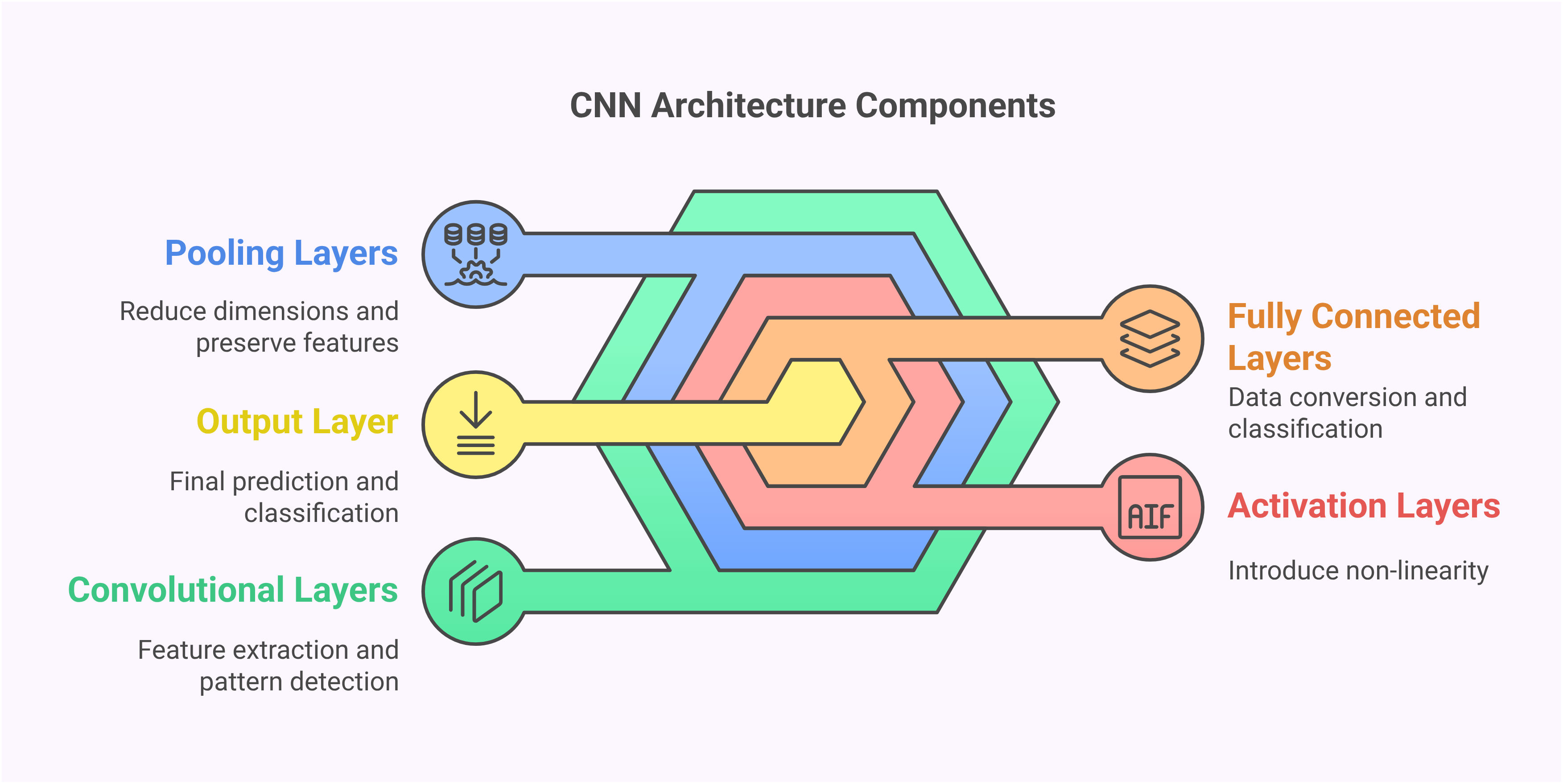
Основные строительные блоки CNN включают сверточные слои, которые сканируют изображения с фильтрами для обнаружения признаков, пулинговые слои, которые уменьшают размерность, сохраняя важную информацию, и полностью связанные слои, выполняющие окончательную классификацию. Этот структурированный подход позволяет CNN автоматически изучать релевантные признаки без ручного проектирования, делая их идеальными для различных приложений распознавания изображений от медицинской диагностики до систем автономного вождения.
Настройка окружения и необходимые инструменты
Перед реализацией вашей CNN правильная конфигурация окружения необходима. Это руководство использует Python 3.7+ с TensorFlow 2.x и Keras в качестве основной платформы глубокого обучения. Процесс настройки включает установку нескольких ключевых пакетов, которые обеспечивают вычислительную основу для операций нейронных сетей. Начните с создания виртуального окружения для чистого управления зависимостями, затем установите необходимые пакеты с помощью pip.
Основные пакеты включают TensorFlow для вычислительных операций, Keras для высокоуровневых API нейронных сетей, NumPy для численных операций и Matplotlib для визуализации. Дополнительные полезные библиотеки включают OpenCV для расширенной обработки изображений и Scikit-learn для утилит предобработки данных. Эти инструменты в совокупности обеспечивают надежную основу для создания и экспериментирования с моделями глубокого обучения в различных аппаратных конфигурациях.
Необходимые библиотеки Python для разработки CNN
Импорт правильных библиотек устанавливает основу для вашей системы распознавания изображений. Ключевые импорты включают NumPy для операций с массивами, слои Keras для архитектуры сети и утилиты наборов данных для загрузки обучающих данных. Каждая библиотека служит определенным целям в конвейере CNN, от манипуляции данными до определения и обучения модели.
Последовательная модель из Keras предоставляет линейный стек слоев, в то время как Conv2D реализует сверточные операции. Слои Dropout предотвращают переобучение, BatchNormalization стабилизирует обучение, а MaxPooling2D уменьшает пространственные размерности. Понимание роли каждого компонента помогает в проектировании эффективных архитектур и устранении проблем во время разработки. Эти библиотеки формируют ядро современных фреймворков глубокого обучения, используемых в производственных средах.
Работа с набором данных CIFAR-10
Набор данных CIFAR-10 служит отличным эталоном для задач распознавания изображений, содержа 60 000 цветных изображений по 10 категориям, включая самолеты, автомобили, птиц, кошек, оленей, собак, лягушек, лошадей, корабли и грузовики. Каждое изображение размером 32x32 пикселя представляет реальные объекты с различными перспективами и условиями освещения, что делает его достаточно сложным для демонстрации возможностей CNN, оставаясь вычислительно управляемым.
Предобработка данных включает нормализацию значений пикселей в диапазон 0-1 путем деления на 255, что стабилизирует обучение и улучшает сходимость. One-hot кодирование преобразует категориальные метки в бинарные векторы, позволяя многоклассовую классификацию. Правильная предобработка гарантирует, что сеть получает стандартизированный ввод, сокращая время обучения и улучшая окончательную точность. Этот набор данных предоставляет практический опыт с реальными методами валидации моделей.
Построение архитектуры CNN с Keras
Проектирование архитектуры CNN включает стратегическое наслоение слоев для извлечения все более сложных признаков. Примерная архитектура начинается со сверточных слоев с использованием фильтров 3x3 и активации ReLU, за которыми следуют dropout и batch normalization для регуляризации. Слои макс-пулинга уменьшают пространственные размерности, сохраняя важные признаки, и сеть завершается плотными слоями для классификации.
Ключевые архитектурные решения включают размеры фильтров, стратегии пулинга и глубину слоев. Меньшие фильтры (3x3) захватывают мелкие детали, в то время как большие фильтры распознают более широкие паттерны. Количество фильтров увеличивается в более глубоких слоях для обработки более сложных комбинаций признаков. Эта прогрессирующая сложность позволяет сети изучать иерархические представления, от простых краев в ранних слоях до сложных частей объектов в более глубоких слоях. Такие архитектуры формируют основу современных систем компьютерного зрения.
Компиляция модели и конфигурация обучения
Компиляция модели включает указание функции потерь, оптимизатора и метрик оценки. Для многоклассовой классификации категориальная перекрестная энтропия измеряет ошибку предсказания, в то время как оптимизатор Adam адаптирует скорости обучения во время тренировки. Метрики точности отслеживают производительность на протяжении процесса обучения, предоставляя немедленную обратную связь об улучшении модели.
Параметры обучения, такие как размер пакета и эпохи, значительно влияют на результаты. Меньшие пакеты обеспечивают более частые обновления весов, но требуют больше вычислений, в то время как большие пакеты предлагают стабильность, но могут сходиться медленнее. Разделение валидации отслеживает производительность обобщения, помогая обнаружить переобучение рано. Эти конфигурации балансируют эффективность обучения с качеством модели, что необходимо для разработки надежных приложений ИИ.
Практические шаги реализации
Реализация следует структурированному рабочему процессу, начиная с настройки окружения и загрузки данных. После импорта необходимых библиотек загрузите и предобработайте набор данных CIFAR-10, затем определите архитектуру CNN с использованием Keras Sequential API. Скомпилируйте модель с подходящими функциями потерь и оптимизаторами, затем обучите, используя подготовленные данные с мониторингом валидации.
Оценка включает тестирование обученной модели на невидимых данных и анализ метрик производительности. Пошаговый подход обеспечивает понимание каждого компонента при построении полной рабочей системы. Эта методология применима к различным задачам распознавания изображений за пределами объема руководства, предоставляя передаваемые навыки для реальных проектов.
Плюсы и минусы
Преимущества
- Автоматически изучает релевантные признаки без ручного проектирования
- Достигает высокой точности на сложных задачах распознавания изображений
- Устойчив к вариациям масштаба, вращения и условий освещения
- Эффективная обработка через разделение параметров в сверточных слоях
- Доказанная эффективность в различных приложениях компьютерного зрения
- Непрерывное улучшение с большими наборами данных и лучшими архитектурами
- Возможности трансферного обучения для связанных визуальных задач
Недостатки
- Вычислительно интенсивное обучение, требующее значительных ресурсов
- Большие размеченные наборы данных необходимы для оптимальной производительности
- Подвержен переобучению без надлежащей регуляризации
- Сложная настройка гиперпараметров для оптимальных результатов
- Природа черного ящика, затрудняющая интерпретацию
Заключение
Это руководство демонстрирует практическую реализацию сверточных нейронных сетей для распознавания изображений с использованием Python и Keras. От настройки окружения до оценки модели мы рассмотрели основные шаги для построения эффективных систем компьютерного зрения. Набор данных CIFAR-10 предоставляет реалистичную тестовую площадку, в то время как архитектура CNN демонстрирует современные техники глубокого обучения. По мере того как вы продолжаете разрабатывать решения для распознавания изображений, помните, что успешные реализации балансируют архитектурную сложность с вычислительной эффективностью и всегда проверяют производительность с помощью строгого тестирования. Навыки, полученные здесь, предоставляют прочную основу для решения более сложных задач компьютерного зрения в реальных приложениях.
Часто задаваемые вопросы
Какое идеальное количество слоев для CNN?
Нет универсального ответа — начните с 3-5 сверточных слоев для базовых задач, увеличивая глубину для сложного распознавания. Сбалансируйте глубину с вычислительными ограничениями и рисками переобучения с помощью надлежащих методов регуляризации.
Как я могу повысить точность моей модели CNN?
Повысьте точность с помощью аугментации данных, настройки гиперпараметров, оптимизации архитектуры, методов регуляризации и трансферного обучения. Экспериментируйте с различными оптимизаторами, скоростями обучения и конфигурациями слоев, отслеживая производительность валидации.
Работает ли этот учебник с другими наборами данных?
Да, методология применима к различным наборам данных изображений. Настройте входные размеры, нормализацию и выходные слои в соответствии с характеристиками ваших конкретных данных, сохраняя основные принципы архитектуры CNN.
Как CNN обрабатывает вариации изображений, такие как поворот и масштаб?
CNN используют слои пулинга и аугментацию данных для сохранения инвариантности к малым преобразованиям, но могут потребовать специальных методов, таких как пространственные трансформаторы, для больших вариаций поворота и масштаба.
Какие ключевые параметры нужно настраивать в модели CNN?
Важные параметры включают размеры фильтров, количество слоев, скорость обучения, размер пакета и методы регуляризации, такие как dropout, для оптимизации производительности и предотвращения переобучения в задачах распознавания изображений.
Релевантные статьи об ИИ и технологических трендах
Будьте в курсе последних инсайтов, инструментов и инноваций, формирующих будущее ИИ и технологий.
Grok AI: Бесплатное неограниченное создание видео из текста и изображений | Руководство 2024
Grok AI предлагает бесплатное неограниченное создание видео из текста и изображений, делая профессиональное создание видео доступным для всех без навыков редактирования.
Настройка Grok 4 Fast в Janitor AI: Полное руководство по ролевой игре без фильтров
Пошаговое руководство по настройке Grok 4 Fast в Janitor AI для неограниченной ролевой игры, включая настройку API, параметры конфиденциальности и советы по оптимизации
Топ-3 бесплатных расширений для ИИ-программирования в VS Code 2025 - Повышение производительности
Откройте для себя лучшие бесплатные расширения для ИИ-программирования в Visual Studio Code в 2025 году, включая Gemini Code Assist, Tabnine и Cline, чтобы улучшить вашу