Annotation
- Введение
- Понимание роли AI в генерации данных
- Создание генератора Покемонов: Использование массивов
- Создание классификатора настроений: Использование перечислений
- Сравнение генерации массивов и перечислений
- Настройка выхода данных AI с Zod
- Плюсы и минусы
- Заключение
- Часто задаваемые вопросы
Структурированные данные ИИ: Руководство по массивам и перечислениям для разработчиков | ToolPicker
Это руководство исследует использование массивов и перечислений в SDK ИИ для генерации структурированных данных, с практическими примерами, такими как генераторы покемонов и анализ настроений.

Введение
Поскольку искусственный интеллект продолжает преобразовывать разработку программного обеспечения, освоение генерации структурированных данных становится необходимым для создания надежных приложений. Это всеобъемлющее руководство исследует, как разработчики могут использовать массивы и перечисления в AI SDK для создания организованных, предсказуемых выходных данных. Эти структуры данных обеспечивают более эффективную обработку, лучшую типобезопасность и улучшенный пользовательский опыт в AI-приложениях в различных областях.
Понимание роли AI в генерации данных
Традиционная разработка программного обеспечения часто требует ручного определения структуры данных, но AI SDK теперь позволяют динамическую генерацию, которая адаптируется к конкретным требованиям. Этот сдвиг парадигмы позволяет приложениям становиться более гибкими и отзывчивыми к потребностям пользователей. Массивы и перечисления представляют две фундаментальные паттерны, которые разработчики могут реализовать для эффективной структуризации AI выходов. Массивы организуют связанные элементы в списки, в то время как перечисления классифицируют данные в предопределенные категории, оба предоставляя значительные преимущества для валидации данных и эффективности обработки.
Интеграция этих структур с современными инструментами разработки создает мощные комбинации для построения интеллектуальных приложений. При работе с AI API и SDK, понимание того, как правильно реализовать массивы и перечисления, может dramatically улучшить согласованность выходов и надежность приложений.
Создание генератора Покемонов: Использование массивов
Массивы служат основой для управления коллекциями похожих объектов в AI-генерируемых данных. Рассмотрим практический пример, где вам нужно сгенерировать списки Покемонов на основе конкретных типов, таких как 'огонь' или 'вода'. Используя AI SDK, вы можете указать модели производить структурированные массивы, содержащие имена Покемонов и их связанные способности. Этот подход требует определения четкой схемы для отдельных объектов Покемонов, затем обертывания этой схемы в структуру массива.
Реализация обычно включает использование Zod, библиотеки валидации схем с приоритетом TypeScript, для определения структуры данных:
import { z } from "zod";
export const pokemonSchema = z.object({
name: z.string(),
abilities: z.array(z.string()),
});
export const pokemonUISchema = z.array(pokemonSchema);Это определение схемы гарантирует, что каждый объект Покемона содержит строку имени и массив строк способностей. Затем pokemonUISchema указывает, что AI должен генерировать несколько экземпляров этих объектов, создавая связный список. Аспект инженерии промптов включает указание AI 'Сгенерировать список из 5 Покемонов типа {type}', где параметр type динамически настраивается на основе пользовательского ввода.
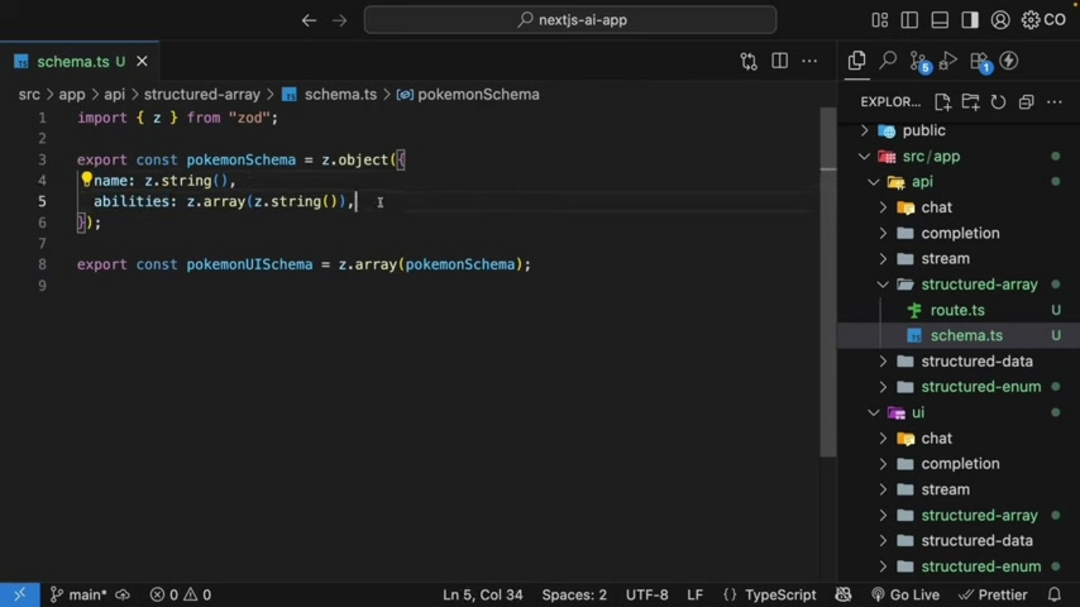
Ключевые соображения по реализации включают правильную валидацию схемы, спецификацию выхода в обработчиках маршрутов и обеспечение того, что AI понимает контекст массива. Этот подход демонстрирует, как массивы могут организовывать сложные коллекции данных для приложений, требующих множества похожих объектов, делая его особенно полезным для платформ AI автоматизации, которые обрабатывают повторяющиеся задачи генерации данных.
Создание классификатора настроений: Использование перечислений
Перечисления предоставляют структурированный подход к задачам классификации, где выходы должны попадать в предопределенные категории. Классификатор анализа настроений идеально иллюстрирует эту концепцию, где текст должен быть категоризован как положительный, отрицательный или нейтральный. В отличие от массивов, перечисления не требуют сложных определений схем – вместо этого разработчики непосредственно указывают возможные значения в обработчике маршрута.
Реализация обычно использует функцию generateObject вместо потоковых подходов:
import { generateObject } from "ai";
import { openAI } from "@ai-sdk/openai";
export async function POST(req: Request) {
try {
const { text } = await req.json();
const result = await generateObject({
model: openAI("gpt-4.1-mini"),
output: "enum",
enum: ["positive", "negative", "neutral"],
prompt: `Classify the sentiment in this text: ${text}`,
});
return result.toJsonResponse();
} catch (error) {
console.error("Error generating sentiment", error);
return new Response("Failed to generate sentiment", { status: 500 });
}
}
Критические факторы для успешной реализации перечисления включают выбор модели – более способные модели, такие как GPT-4.1-mini, обеспечивают лучшую согласованность – и четкое определение значений перечисления. Этот подход гарантирует, что AI выходы остаются в ожидаемых границах, делая его неоценимым для AI агентов и ассистентов, которые требуют надежных возможностей классификации.
Сравнение генерации массивов и перечислений
Понимание различий между генерацией массивов и перечислений помогает разработчикам выбирать подходящую структуру данных для конкретных случаев использования. Массивы превосходны в управлении коллекциями объектов, в то время как перечисления специализируются на задачах классификации, где выходы должны соответствовать предопределенным категориям. Различия в реализации выходят за рамки требований к схеме и включают используемые функции AI SDK и то, как данные обрабатываются.
Массивы обычно работают с streamObject для прогрессивной генерации данных, делая их подходящими для больших наборов данных или приложений реального времени. Перечисления, однако, лучше всего работают с generateObject, поскольку они производят единые значения классификации. Таблица ниже выделяет ключевые различия:
| Особенность | Массивы | Перечисления |
|---|---|---|
| Структура данных | Список объектов | Предопределенные категории |
| Схема требуется | Да, определяет структуру объекта | Нет, значения определены в обработчике |
| Тип выхода | array | enum |
| Функция AI SDK | streamObject | generateObject |
| Случай использования | Коллекции похожих объектов | Классификация и категоризация |
| Обработка данных | Возвращает массив объектов | Возвращает единое классифицированное значение |
Эти структурные различия влияют на то, как разработчики подходят к инженерии AI промптов и обработке выходов, делая правильный выбор crucial для успеха приложения.
Настройка выхода данных AI с Zod
Zod предоставляет обширные возможности для определения и валидации схем в приложениях TypeScript, предлагая типобезопасную валидацию, которая гарантирует, что AI-генерируемые данные соответствуют конкретным структурным требованиям. Помимо базовых реализаций массивов и перечислений, Zod поддерживает сложные сценарии валидации, которые улучшают надежность данных и robustность приложения.
Продвинутые функции Zod включают сложную валидацию объектов для вложенных структур данных, пользовательские функции валидации для правил, специфичных для приложения, и преобразования данных, которые модифицируют выходы для лучшего соответствия потребностям приложения. Эти возможности становятся особенно ценными при работе с инструментами AI написания, которые генерируют структурированный контент, или при реализации правил форматирования кода для сгенерированных выходов.
Комбинируя силу валидации Zod с генерацией данных AI, разработчики могут создавать более надежные приложения, которые эффективно обрабатывают структурированные данные, сохраняя типобезопасность и целостность данных на протяжении всего конвейера обработки.
Плюсы и минусы
Преимущества
- Улучшенная согласованность и предсказуемость данных в AI выходах
- Улучшенная типобезопасность и уменьшенные ошибки времени выполнения
- Организация структурированных данных для лучшей архитектуры приложения
- Более легкие рабочие процессы валидации и обработки данных
- Лучшая интеграция с существующими инструментами и библиотеками разработки
- Более поддерживаемый и масштабируемый код AI приложения
- Четкое разделение между структурой данных и бизнес-логикой
Недостатки
- Дополнительная сложность в определении и валидации схемы
- Потенциальные накладные расходы на производительность со сложными валидациями
- Кривая обучения для разработчиков, новых в структурированных данных AI
- Ограниченная гибкость для динамических или непредсказуемых паттернов данных
- Зависимость от конкретных AI моделей для согласованности перечислений
Заключение
Освоение массивов и перечислений для генерации структурированных данных AI представляет значительное продвижение в современной разработке программного обеспечения. Эти структуры данных предоставляют основу для построения надежных, поддерживаемых AI приложений, которые производят согласованные, валидированные выходы. Понимая, когда использовать массивы для коллекций объектов и перечисления для задач классификации, разработчики могут создавать более robustные приложения, которые эффективно используют возможности AI. Интеграция с библиотеками валидации, такими как Zod, дополнительно улучшает надежность данных, в то время как правильные соображения по реализации обеспечивают оптимальную производительность и пользовательский опыт в различных AI-управляемых приложениях.
Часто задаваемые вопросы
Каково основное преимущество использования массивов для данных, сгенерированных ИИ?
Массивы обеспечивают структурированную организацию для списков связанных точек данных, позволяя предсказуемую итерацию и обработку нескольких элементов. Это важно, когда ИИ генерирует коллекции похожих объектов, таких как продукты или результаты поиска, улучшая управление данными и надежность приложения.
Когда разработчикам следует выбирать перечисления вместо других структур данных?
Перечисления идеально подходят для задач классификации, где выходные данные должны соответствовать предопределенным категориям. Они ограничивают ответы ИИ конкретными значениями, обеспечивая согласованность в анализе настроений, классификации статусов и процессах принятия решений, одновременно повышая надежность приложения.
Могут ли перечисления работать с streamObject в SDK ИИ?
Нет, перечисления специально разработаны для generateObject, который возвращает единичные значения классификации. Для потоковых данных разработчики должны использовать массивы или другие структуры, поддерживающие прогрессивную генерацию вывода и обработку в реальном времени.
Почему выбор модели важен для генерации перечислений?
Более способные модели ИИ обеспечивают лучшую согласованность в генерации правильных значений перечислений. Менее продвинутые модели могут испытывать трудности с предопределенными категориями, что приводит к непредсказуемым результатам. Выбор подходящих моделей гарантирует надежный вывод классификации.
Как Zod улучшает валидацию данных ИИ?
Zod обеспечивает типобезопасную валидацию схем, гарантируя, что данные, сгенерированные ИИ, соответствуют структурным требованиям, уменьшая ошибки и повышая надежность приложения через определенные схемы для массивов, перечислений и сложных объектов.
Релевантные статьи об ИИ и технологических трендах
Будьте в курсе последних инсайтов, инструментов и инноваций, формирующих будущее ИИ и технологий.
Grok AI: Бесплатное неограниченное создание видео из текста и изображений | Руководство 2024
Grok AI предлагает бесплатное неограниченное создание видео из текста и изображений, делая профессиональное создание видео доступным для всех без навыков редактирования.
Настройка Grok 4 Fast в Janitor AI: Полное руководство по ролевой игре без фильтров
Пошаговое руководство по настройке Grok 4 Fast в Janitor AI для неограниченной ролевой игры, включая настройку API, параметры конфиденциальности и советы по оптимизации
Топ-3 бесплатных расширений для ИИ-программирования в VS Code 2025 - Повышение производительности
Откройте для себя лучшие бесплатные расширения для ИИ-программирования в Visual Studio Code в 2025 году, включая Gemini Code Assist, Tabnine и Cline, чтобы улучшить вашу