Annotation
- Введение
- Эволюция методов классификации текста
- Трансформерная революция в NLP
- Фреймворки глубокого обучения для классификации текста
- Трансферное обучение с предварительно обученными моделями
- Практическая реализация с ULMFiT
- Плюсы и минусы
- Реальные приложения и инструменты
- Корпоративный анализ текста с Gong.io
- Автоматическое тегирование и планирование электронной почты
- Будущие направления в классификации текста
- Заключение
- Часто задаваемые вопросы
Расширенное руководство по классификации текста: Фреймворки и методы глубокого обучения
Расширенное руководство по классификации текста, охватывающее фреймворки глубокого обучения, BERT, трансформеры, трансферное обучение и реальные приложения для точной

Введение
Классификация текста представляет собой фундаментальный столп обработки естественного языка, позволяя системам автоматически категоризировать и интерпретировать неструктурированные текстовые данные. Это всеобъемлющее руководство исследует, как фреймворки глубокого обучения преобразовали возможности классификации текста, обеспечивая беспрецедентную точность в категоризации документов, анализе настроений и автоматической организации контента. Независимо от того, создаёте ли вы автоматизацию обслуживания клиентов или системы модерации контента, понимание этих передовых методов необходимо для современных приложений искусственного интеллекта.
Эволюция методов классификации текста
Прогресс методологий классификации текста отражает более широкие достижения в вычислительной лингвистике и машинном обучении. Ранние подходы сильно полагались на статистические методы, которые рассматривали текст как простые коллекции слов, не учитывая семантические отношения или контекстуальное значение.

Модель "Мешок слов" появилась как ранний стандарт, представляя документы в виде векторов частот слов, полностью игнорируя грамматику, порядок слов и семантический контекст. Хотя простая в реализации и предоставляющая интерпретируемые результаты, BoW страдала от значительных ограничений, включая ограничения словаря и неспособность улавливать отношения между словами. Например, она рассматривала "кошка" и "котёнок" как совершенно разные сущности без семантической связи и обрабатывала "фильм был смешным и не скучным" идентично "фильм был скучным и не смешным" – что явно проблематично для точной классификации настроений.
По мере расширения вычислительных ресурсов и созревания архитектур нейронных сетей появились более сложные подходы. Сверточные нейронные сети (CNN) и рекуррентные нейронные сети (RNN) начали использовать распределенные представления слов, которые захватывали семантические сходства через модели векторных пространств. Этот прорыв позволил моделям понимать, что связанные слова должны иметь схожие векторные представления, значительно улучшив точность классификации в различных областях, включая AI чат-боты и системы автоматических ответов.
Трансформерная революция в NLP
Введение трансформерных архитектур в 2018 году стало переломным моментом для обработки естественного языка. Эти модели использовали механизмы самовнимания для одновременной обработки целых последовательностей, захватывая контекстуальные отношения между всеми словами в документе.
Модели, такие как BERT, ELMo и GPT, использовали трансформерные архитектуры для генерации контекстуальных векторных представлений слов – представлений, которые варьируются в зависимости от окружающих слов, а не сохраняют статические представления. Это контекстуальное понимание позволило достичь беспрецедентной производительности в задачах, требующих тонкого понимания языка, от анализа юридических документов до категоризации медицинских текстов. Вычислительные требования этих моделей обычно требуют ускорения на GPU, но улучшения точности оправдывают инвестиции в инфраструктуру для производственных систем, особенно в платформах автоматизации ИИ, где точность критически важна.
Фреймворки глубокого обучения для классификации текста
Современные конвейеры классификации текста обычно используют установленные фреймворки глубокого обучения, которые предоставляют комплексные инструменты для разработки, обучения и развертывания моделей. Экосистема значительно созрела, предлагая несколько надежных вариантов, подходящих для различных случаев использования и предпочтений команд.
TensorFlow, разработанный Google, предлагает готовую к производству экосистему с обширной документацией и поддержкой сообщества. Его статический граф вычислений предоставляет возможности оптимизации, которые выгодны для сценариев крупномасштабного развертывания. PyTorch, предпочитаемый исследовательскими сообществами, отличается динамическими графами вычислений, которые обеспечивают более гибкие архитектуры моделей и упрощенные рабочие процессы отладки. Оба фреймворка интегрируются бесшовно со специализированными библиотеками NLP, такими как spaCy, которая предоставляет промышленно-уровневую токенизацию, частеречную разметку и распознавание именованных сущностей – важные шаги предварительной обработки для эффективной классификации текста в API и SDK ИИ.
Трансферное обучение с предварительно обученными моделями
Трансферное обучение значительно сократило требования к данным и вычислениям для построения высокопроизводительных классификаторов текста. Вместо обучения моделей с нуля, практики могут дообучать модели, предварительно обученные на массивных текстовых корпусах, адаптируя общее понимание языка к конкретным задачам классификации.
Этот подход использует лингвистические знания, закодированные в моделях, таких как BERT, которые изучили грамматические структуры, семантические отношения и даже фактические знания из обучения на Википедии, книгах и веб-контенте. Дообучение требует значительно меньших размеченных наборов данных – иногда всего сотни или тысячи примеров вместо миллионов – делая сложную классификацию текста доступной для организаций без массивных ресурсов данных. Эта методология оказалась особенно ценной для инструментов письма на ИИ, которым необходимо категоризировать контент по тону, стилю или тематике.
Практическая реализация с ULMFiT
Подход Universal Language Model Fine-tuning (ULMFiT) предоставляет структурированную методологию для адаптации предварительно обученных языковых моделей к конкретным задачам классификации текста. Этот трехэтапный процесс стал стандартным рабочим процессом для многих практиков NLP.
Во-первых, начните с языковой модели, предварительно обученной на большом общем корпусе, таком как Википедия. Эта модель уже изучила общие языковые паттерны и семантические отношения. Во-вторых, дообучите эту языковую модель на текстах из конкретной области – даже неразмеченный текст из вашей целевой области улучшает производительность. Наконец, добавьте слой классификации и дообучите всю модель на вашем размеченном наборе данных для классификации. Этот подход постепенной специализации обычно превосходит обучение классификаторов непосредственно на ограниченных размеченных данных.
Для пользовательских векторных представлений слов процесс включает использование Gensim для реализации генератора предложений, который подает текст алгоритмам Word2Vec, обучая векторные представления для конкретной области, которые затем могут быть интегрированы с конвейерами spaCy для последующих задач классификации. Этот подход особенно ценен для инструментов разговорного ИИ, которым необходимо понимать терминологию и паттерны формулировок конкретной области.
Плюсы и минусы
Преимущества
- Контекстуальное понимание захватывает нюансы значения языка
- Трансферное обучение значительно сокращает требования к данным
- Предварительно обученные модели обеспечивают сильную базовую производительность
- Экосистемы фреймворков предлагают обширные инструменты и поддержку
- Масштабируемые архитектуры обрабатывают большие объемы документов
- Непрерывное улучшение через дообучение моделей
- Многоязычная поддержка через кросс-лингвальные векторные представления
Недостатки
- Вычислительная интенсивность требует ресурсов GPU
- Проблемы интерпретируемости моделей для бизнес-пользователей
- Адаптация к области все еще требует технической экспертизы
- Ограничения словаря для высокоспециализированной терминологии
- Сложность развертывания в производственных средах
Реальные приложения и инструменты
Корпоративный анализ текста с Gong.io
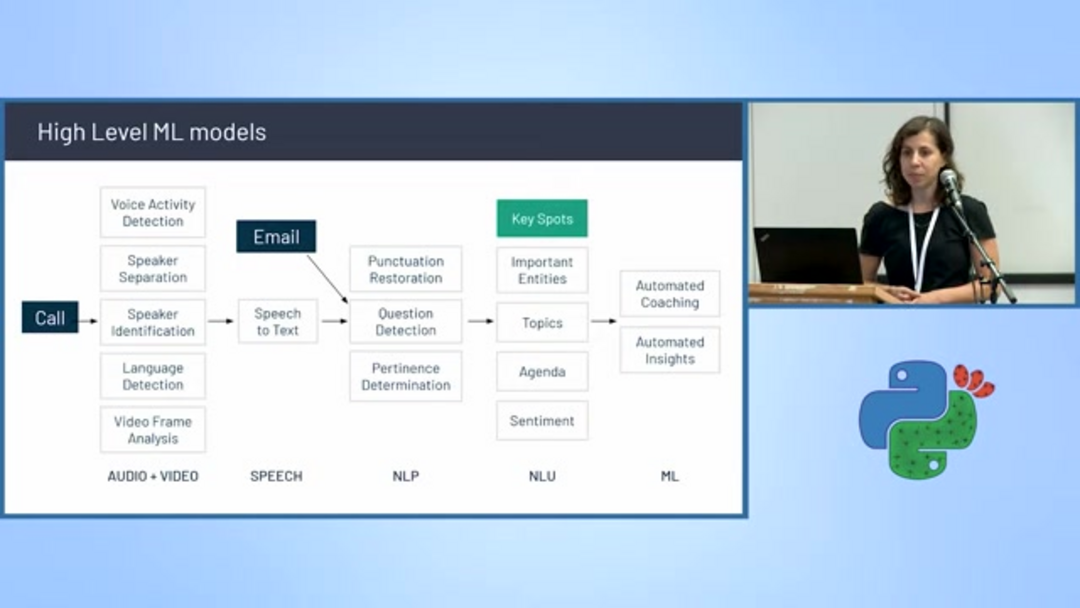
Коммерческие платформы, такие как Gong.io, демонстрируют, как передовая классификация текста преобразует бизнес-операции, особенно в областях продаж и успеха клиентов. Платформа записывает, транскрибирует и анализирует разговоры о продажах, используя сложный конвейер моделей машинного обучения.
Архитектура Gong включает несколько специализированных классификаторов, включая обнаружение голосовой активности, разделение и идентификацию говорящих, обнаружение языка и преобразование речи в текст. Помимо базовой транскрипции, система выполняет расширенный анализ, включая восстановление пунктуации, обнаружение вопросов, тематическое моделирование, определение релевантности, отслеживание повестки дня, анализ настроений и извлечение сущностей. Этот всеобъемлющий подход позволяет агентам и ассистентам ИИ предоставлять действенные инсайты командам продаж, выделяя упоминания конкурентов, обсуждения ценностных предложений и паттерны обработки возражений.
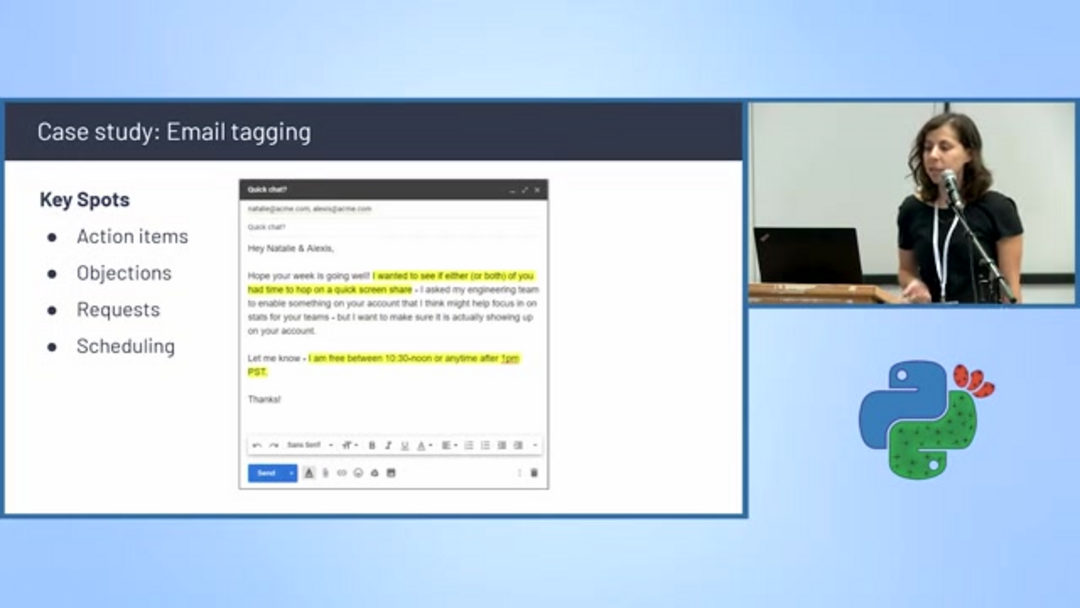
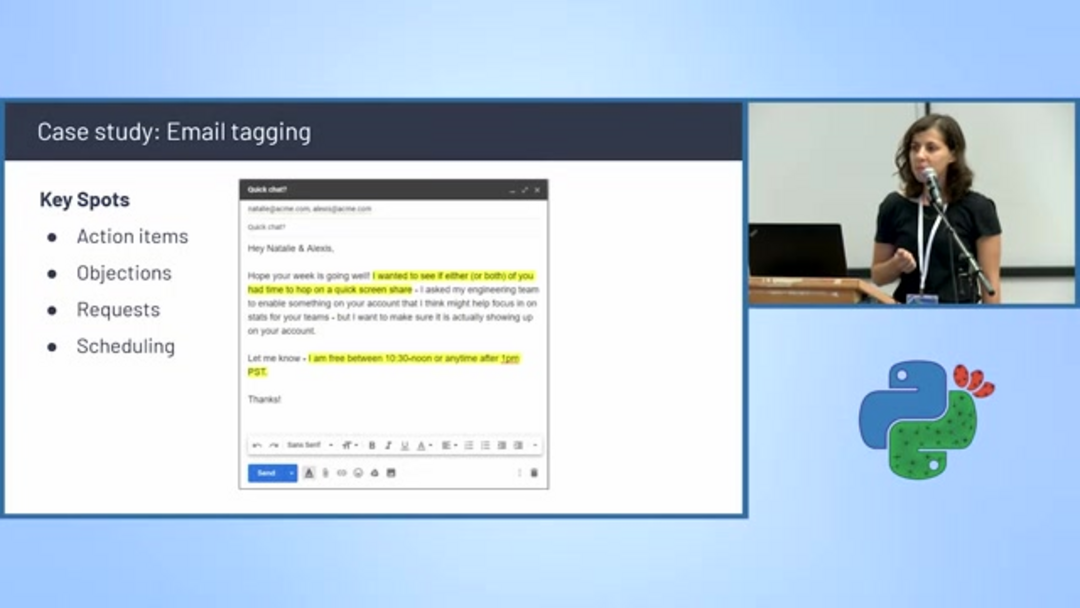
Автоматическое тегирование и планирование электронной почты
Классификация текста питает интеллектуальные системы управления электронной почтой, которые автоматически категоризируют сообщения и извлекают информацию для действий. Алгоритмы обнаружения планирования идентифицируют письма, содержащие предложения о встречах, обсуждения доступности и координацию календаря, автоматически тегируя их для приоритетной обработки.
Эти системы анализируют ключевые элементы разговора, включая пункты действий, возражения, конкретные запросы и упоминания планирования. Фильтруя и категоризируя письма на основе содержания, предприятия могут оптимизировать управление рабочими процессами и обеспечить своевременное отслеживание критических коммуникаций. Эта возможность особенно ценна для ассистентов электронной почты на ИИ, которые помогают управлять переполненными почтовыми ящиками и расставлять приоритеты ответов.
Будущие направления в классификации текста
Поле продолжает быстро развиваться, с несколькими перспективными направлениями исследований, решающими текущие ограничения и расширяющими возможности приложений. Объяснимый ИИ (XAI) фокусируется на том, чтобы сделать решения моделей интерпретируемыми для пользователей-людей, строя доверие и облегчая анализ ошибок. Моделирование языков с ограниченными ресурсами направлено на расширение возможностей сложной классификации для языков с ограниченными цифровыми текстовыми ресурсами.
Мультимодальные подходы интегрируют текст с другими типами данных, такими как изображения и аудио, создавая более богатые контексты понимания – особенно ценно для анализа социальных сетей, где текст и визуальный контент взаимодействуют. Стратегии активного обучения оптимизируют усилия по аннотированию, идентифицируя наиболее информативные образцы для человеческого обзора, в то время как методы обучения с малым количеством примеров позволяют эффективную адаптацию моделей с минимальными тренировочными примерами, решая одну из самых значительных проблем в развертывании машинного обучения.
Заключение
Классификация текста эволюционировала от простых статистических методов до сложных подходов глубокого обучения, которые понимают контекстуальные нюансы и семантические отношения. Комбинация трансформерных архитектур, трансферного обучения и комплексных фреймворков сделала высокоточную классификацию доступной в различных областях и приложениях. Поскольку исследования продолжают продвигать объяснимость, эффективность и мультимодальные возможности, классификация текста станет все более интегральной частью интеллектуальных систем, которые обрабатывают, организуют и извлекают инсайты из постоянно растущих объемов цифрового текста. Освоение этих методов предоставляет значительное конкурентное преимущество в разработке решений на основе ИИ, которые понимают и категоризируют человеческий язык с пониманием, подобным человеческому.
Часто задаваемые вопросы
Почему порядок слов важен в классификации текста?
Порядок слов несет решающее смысловое значение – изменение последовательности может полностью изменить значение предложения. Модели, игнорирующие порядок слов, не могут различить «фильм был смешным и не скучным» и «фильм был скучным и не смешным», что приводит к неточным результатам классификации, особенно в анализе настроений.
Каковы основные шаги для обучения пользовательских векторных представлений слов?
Обучение пользовательских векторных представлений включает три ключевых шага: реализовать генератор предложений с использованием Gensim для подачи текста в модель, запустить Word2Vec или аналогичные алгоритмы для обучения векторных представлений на вашем предметном корпусе, затем интегрировать обученную модель с spaCy или другими NLP-конвейерами для последующих задач классификации, требующих понимания предметно-ориентированного языка.
Как трансферное обучение помогает в классификации текста?
Трансферное обучение позволяет тонко настраивать предварительно обученные модели на конкретных задачах, сокращая потребности в данных и повышая точность за счет использования знаний из больших наборов данных, что делает его эффективным для адаптации к предметной области.
Каковы ключевые преимущества моделей-трансформеров в NLP?
Модели-трансформеры используют самовнимание для параллельной обработки последовательностей, захватывая контекстные отношения между словами, что приводит к лучшей производительности в таких задачах, как классификация текста и анализ настроений.
Как классификация текста может применяться в бизнес-среде?
Классификация текста используется в автоматизации обслуживания клиентов, модерации контента, категоризации электронной почты и анализе продаж, помогая предприятиям автоматизировать процессы и получать информацию из текстовых данных.
Релевантные статьи об ИИ и технологических трендах
Будьте в курсе последних инсайтов, инструментов и инноваций, формирующих будущее ИИ и технологий.
Grok AI: Бесплатное неограниченное создание видео из текста и изображений | Руководство 2024
Grok AI предлагает бесплатное неограниченное создание видео из текста и изображений, делая профессиональное создание видео доступным для всех без навыков редактирования.
Топ-3 бесплатных расширений для ИИ-программирования в VS Code 2025 - Повышение производительности
Откройте для себя лучшие бесплатные расширения для ИИ-программирования в Visual Studio Code в 2025 году, включая Gemini Code Assist, Tabnine и Cline, чтобы улучшить вашу
Настройка Grok 4 Fast в Janitor AI: Полное руководство по ролевой игре без фильтров
Пошаговое руководство по настройке Grok 4 Fast в Janitor AI для неограниченной ролевой игры, включая настройку API, параметры конфиденциальности и советы по оптимизации