Annotation
- 引言
- 理解YOLO和现代物体检测
- 环境设置:Google Colab和本地开发
- 构建高质量自定义数据集
- 使用Label Studio进行高效标注
- 在Google Colab中训练模型
- 本地部署和实际实现
- 优点和缺点
- 结论
- 常见问题
YOLOv11 目标检测:2024 完整训练指南
学习如何使用 Google Colab 和 Label Studio 训练和部署 YOLOv11 进行目标检测。本指南涵盖数据集创建、标注、模型
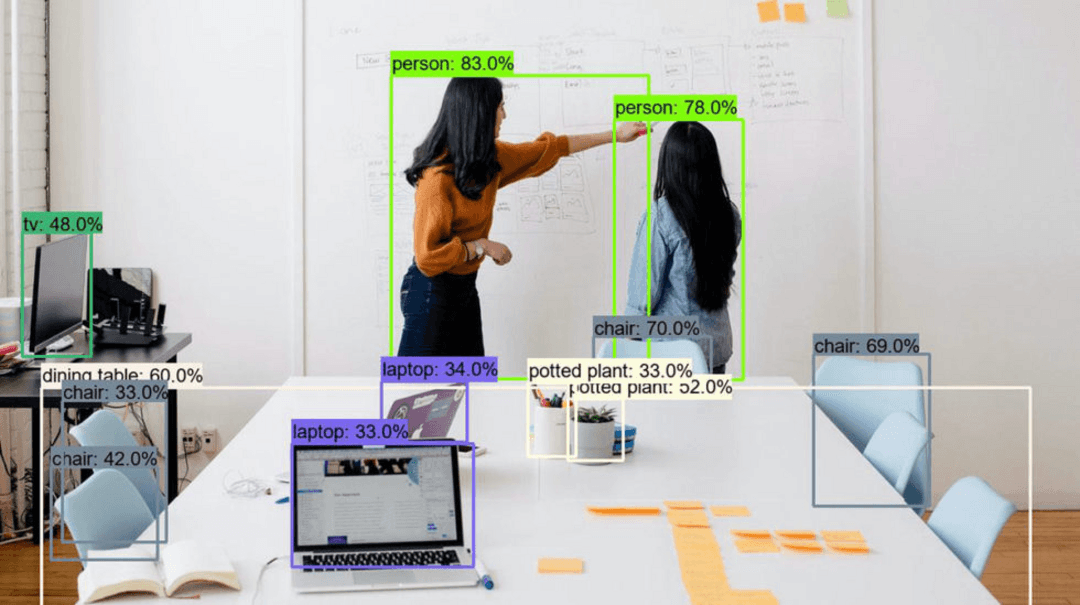
引言
YOLOv11代表了实时物体检测技术的前沿,建立在革命性的“你只看一次”架构之上。本综合指南将引导您使用像Google Colab这样的易用工具训练自定义YOLO模型,创建专门的数据集,并将训练好的模型部署到实际应用中。无论您是为自动驾驶车辆、零售分析还是创意项目开发计算机视觉系统,本教程都为您构建稳健的物体检测解决方案提供了基础。
理解YOLO和现代物体检测
YOLO(你只看一次)通过将物体检测整合为一个单阶段过程,彻底改变了计算机视觉,相比传统的两阶段框架带来了显著的速度提升。YOLOv11延续了这一创新,通过架构优化提高了准确性和效率。该模型在神经网络的一次前向传播中处理整个图像,同时预测边界框和类别概率。这种方法使YOLOv11在延迟至关重要的实时应用中特别有价值,例如视频监控、自主导航和交互系统。
物体检测代表了超越基本图像分类的重大进步。虽然分类仅识别图像中的内容,但检测通过边界框精确定位物体并分配适当的标签。这种细粒度的理解使得应用能够跨越众多AI自动化平台,从工业质量控制到医学影像分析。该技术的多功能性使其对使用各种AI API和SDK进行集成到更大系统的开发人员来说是可访问的。
环境设置:Google Colab和本地开发
Google Colab为YOLO模型训练提供了一个理想的起点,提供免费的GPU资源访问,显著加速了计算密集型过程。这个基于云的平台消除了对昂贵硬件投资的需求,使深度学习对个人开发者和小组队变得可访问。首先,确保您有一个活跃的Google账户,并导航到colab.research.google.com。平台的Jupyter笔记本界面简化了代码执行和实验。
对于本地部署和测试,Anaconda提供了一个强大的解决方案来管理Python环境和依赖项。从anaconda.com下载发行版并遵循安装向导。此设置提供了隔离的环境,您可以在其中安装特定的包版本而不会发生冲突。为不同项目创建专用环境确保了可重复性,并简化了跨多个AI模型托管场景和部署目标的依赖管理。
构建高质量自定义数据集
任何成功的物体检测模型的基础在于其训练数据。一个结构良好、多样化的数据集直接影响模型的准确性和泛化能力。对于概念验证项目,目标是100-200张精心策划的图像,代表模型在生产中将遇到的各种条件。这包括不同的光照场景、背景、物体方向和可能的遮挡。
数据收集策略根据项目需求而变化。对于像我们的糖果检测示例这样的自定义应用,使用智能手机或网络摄像头在多种环境中捕获图像。通过从Roboflow Universe或Kaggle等平台公开可用的数据集补充您的收藏,但始终验证标签的准确性和与您特定用例的相关性。将您的图像组织在逻辑文件夹结构中,例如一个主“yolo”目录,其中包含不同物体类别或数据源的子文件夹。
使用Label Studio进行高效标注
Label Studio通过直观的Web界面和强大的自动化功能简化了关键的标注过程。这个开源工具支持各种标注类型,边界框对于物体检测任务至关重要。安装过程从创建一个专用的Conda环境开始,以保持干净的依赖项:conda create --name yolo-env python=3.12 后跟 pip install label-studio。
标注工作流程包括创建一个新项目,批量导入图像(一次最多100个以避免服务器限制),并为物体检测配置标注界面。用您特定的类名替换默认标签,然后通过围绕目标物体绘制边界框来系统地对每个图像进行标注。利用键盘快捷键提高效率 – 按下对应于类索引的数字键可以显著加快过程。一旦标注完成,以YOLO格式导出您的数据,该格式将图像和相应的标签文件打包成可下载的存档。
在Google Colab中训练模型
准备好标注数据后,转移到Google Colab进行模型训练。通过运行时→更改运行时类型→GPU启用GPU加速,以利用Tensor Processing Units进行更快计算。训练过程涉及几个可配置参数:模型架构(YOLOv11s用于速度 vs. YOLOv11用于准确性)、输入分辨率(通常为640x640像素)和训练持续时间(周期)。
通过像损失、精确度、召回率和平均精确度(mAP)这样的指标监控训练进度。这些指标帮助识别模型何时收敛或需要调整。对于性能不理想的情况,考虑策略如数据增强、学习率调度或架构修改。训练过程在输出目录中生成模型权重(best.pt)和全面的结果可视化,为迭代改进和与各种AI代理和助手的集成提供见解。
本地部署和实际实现
在本地部署训练好的模型需要Ultralytics库(pip install ultralytics)和您导出的模型权重。创建Python脚本,加载模型,处理输入图像或视频流,并显示检测结果。部署脚本应处理各种输入源 – 静态图像、视频文件或实时摄像头馈送 – 同时提供可配置的参数用于置信度阈值和输出格式。
对于糖果卡路里计数器应用,通过将检测到的糖果类型映射到营养信息来扩展基本检测功能。这展示了物体检测如何作为更复杂应用的基础,这些应用结合了计算机视觉和业务逻辑。这样的实现展示了将YOLO模型与屏幕捕获工具和图像转换实用程序集成以实现全面工作流程解决方案的实际价值。
优点和缺点
优点
- 对视频和实时流的实时处理能力
- 单阶段架构提供卓越的速度
- 开源实现,拥有活跃的社区支持
- 针对特定物体类型的灵活定制
- 兼容各种部署平台
- 通过版本更新持续改进
- 广泛的文档和教程资源
缺点
- 训练需要大量标注数据
- 训练阶段计算密集
- 对非常小或重叠的物体处理困难
- 更快模型变体的准确性权衡
- 专业应用需要领域适应
结论
YOLOv11通过尖端性能和易用工具民主化了高级物体检测。本指南使开发人员能够在没有广泛机器学习专业知识的情况下构建自定义视觉系统。YOLO的速度和准确性对于实际应用是不可或缺的。掌握这些技术,使用AI工具目录来连接理论与实践,促进创新。
常见问题
我可以使用现有数据集进行 YOLO 训练吗?
是的,像 Roboflow Universe、Kaggle 和 Google Open Images 这样的平台提供预标注的数据集。在训练前,请务必验证数据质量及其与您特定用例的相关性。
如何提高 YOLO 模型的性能?
通过验证标签准确性、增加训练周期、使用更大的模型架构、扩展数据集多样性以及实施数据增强技术来提高性能。
Google Colab 对 YOLO 训练有哪些优势?
Google Colab 提供免费的 GPU 访问,无需本地硬件要求,具备协作功能,并包含预安装的机器学习库,便于快速开发。
YOLOv11 有哪些关键改进?
YOLOv11 引入了增强的架构以提高准确性和效率,改进了训练技术,并针对实时检测优化了性能,相比早期版本。
训练 YOLOv11 模型需要多长时间?
训练时间因数据集大小、模型架构和硬件而异。使用带有 GPU 的 Google Colab,对于标准数据集可能需要几小时到一天。
相关AI和技术趋势文章
了解塑造AI和技术未来的最新见解、工具和创新。
Grok AI:从文本和图像免费无限生成视频 | 2024指南
Grok AI 提供从文本和图像免费无限生成视频,使每个人无需编辑技能即可进行专业视频创作。
2025年VS Code三大免费AI编程扩展 - 提升生产力
探索2025年Visual Studio Code的最佳免费AI编程助手扩展,包括Gemini Code Assist、Tabnine和Cline,以提升您的
Grok 4 Fast Janitor AI 设置:完整无过滤角色扮演指南
逐步指南:在 Janitor AI 上配置 Grok 4 Fast 进行无限制角色扮演,包括 API 设置、隐私设置和优化技巧