Annotation
- Introduction
- Understanding the Deepfake Detection Challenge
- Dataset Strategy for Robust Model Training
- Vision Transformer Architecture Implementation
- Performance Evaluation and Metrics Analysis
- Full-Stack Deployment Architecture
- End-to-End User Workflow
- Real-World Applications and Use Cases
- Technical Foundation: Transformer Revolution
- Pros and Cons
- Conclusion
- Frequently Asked Questions
Deepfake Image Detection Project: Vision Transformer Implementation Guide
A comprehensive guide on building a deepfake image detection system using Vision Transformers, covering data preparation, model training, evaluation

Introduction
As artificial intelligence continues to advance, the ability to distinguish between authentic and manipulated visual content has become increasingly critical. This comprehensive guide explores a complete deep learning project that leverages cutting-edge transformer architecture to detect deepfake images with remarkable accuracy. From data preparation to web deployment, we'll walk through every component of building a robust deepfake detection system that combines modern AI techniques with practical implementation strategies.
Understanding the Deepfake Detection Challenge
Deepfake technology represents one of the most significant challenges in digital media authenticity today. These AI-generated manipulations can range from subtle facial alterations to complete fabrications that are nearly indistinguishable from real images to human observers. The project we're examining addresses this challenge head-on by implementing a sophisticated detection system that analyzes visual artifacts and inconsistencies that often betray AI-generated content. This approach is particularly relevant for professionals working with AI image generators who need to verify content authenticity.
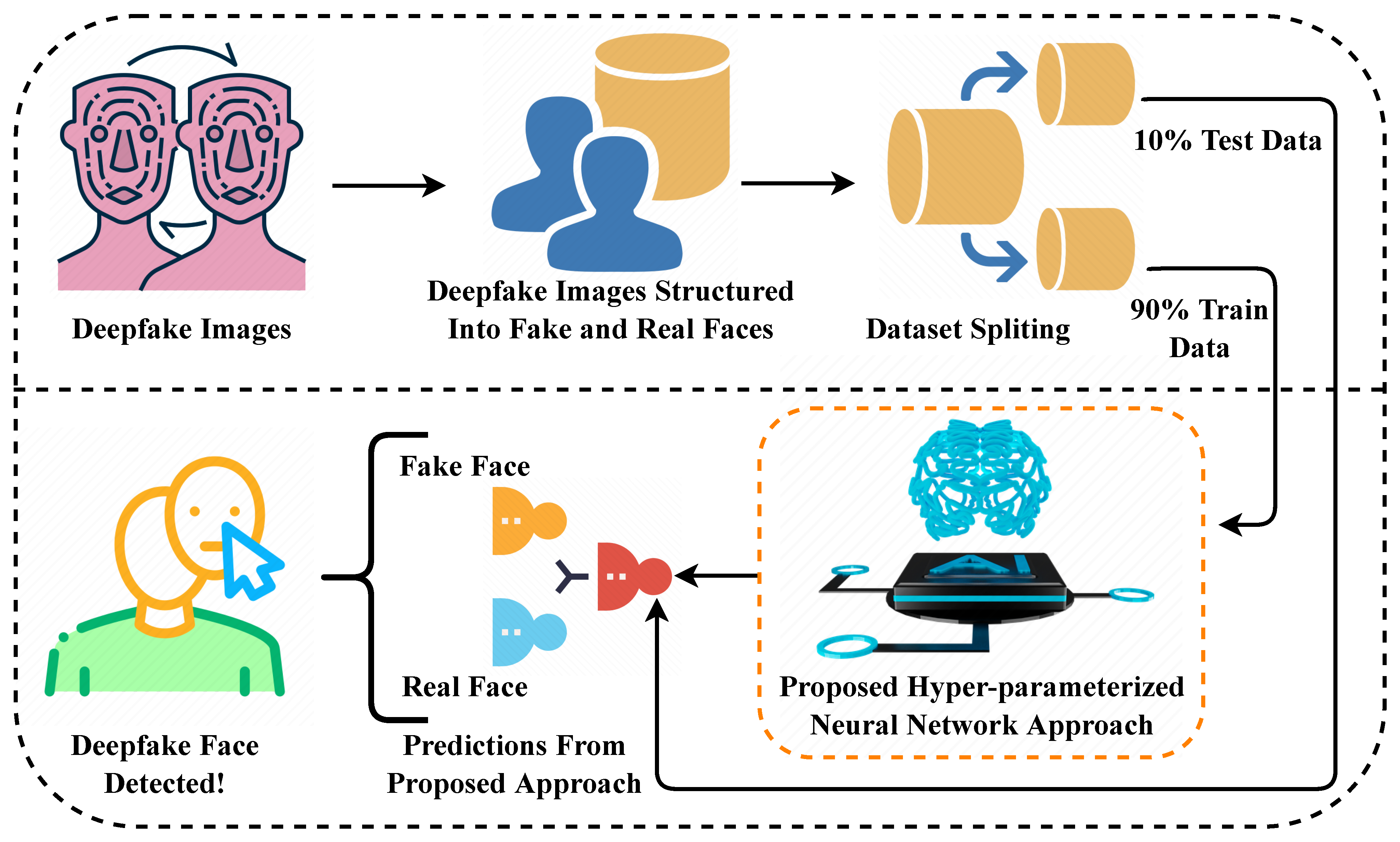
Dataset Strategy for Robust Model Training
The foundation of any effective deep learning model lies in its training data. For this deepfake detection project, the dataset was meticulously curated to include diverse examples of both authentic and manipulated images across various scenarios and quality levels. This diversity ensures the model learns to recognize deepfakes regardless of the specific generation technique used or the image subject matter.
The dataset follows a structured three-part division that's essential for proper model development:
- Training Data (70%): The largest portion exposes the model to thousands of varied examples, teaching it to recognize the subtle patterns and artifacts that distinguish real images from deepfakes across different lighting conditions, resolutions, and manipulation techniques.
- Validation Data (15%): Used during training to monitor performance and prevent overfitting, this subset helps fine-tune hyperparameters and ensures the model generalizes well rather than memorizing the training examples.
- Testing Data (15%): Completely withheld until final evaluation, this data provides an unbiased assessment of how the model will perform on never-before-seen images in real-world scenarios.
Vision Transformer Architecture Implementation
At the core of this detection system lies a Vision Transformer (ViT) model, which represents a significant departure from traditional convolutional neural networks for image analysis. The transformer architecture, originally developed for natural language processing, has demonstrated remarkable performance in computer vision tasks by capturing long-range dependencies and global context within images.
The implementation process within the Jupyter notebook environment follows a systematic approach:
- Environment Setup: Importing essential libraries including TensorFlow, Keras, and specialized transformer implementations, along with data manipulation and visualization tools.
- Data Pipeline Construction: Building efficient data loaders that handle image resizing, normalization, and augmentation techniques like rotation, flipping, and brightness adjustments to improve model robustness.
- Model Configuration: Defining the Vision Transformer architecture with appropriate patch sizes, embedding dimensions, and attention heads tailored for the deepfake detection task.
- Transfer Learning Application: Leveraging pre-trained weights from large-scale image datasets and fine-tuning the model specifically for deepfake detection, significantly reducing training time and improving performance.
- Training Optimization: Implementing learning rate scheduling, early stopping, and gradient clipping to ensure stable and efficient model convergence.
Performance Evaluation and Metrics Analysis
Evaluating a deepfake detection model requires comprehensive metrics that go beyond simple accuracy. The project implements multiple evaluation approaches to thoroughly assess model performance and identify potential weaknesses.
The confusion matrix analysis reveals critical insights into model behavior:
| Predicted Real | Predicted Fake | |
|---|---|---|
| True Real | 37,831 | 249 |
| True Fake | 326 | 37,755 |
This matrix demonstrates excellent performance with minimal false positives and false negatives. The model achieves approximately 99.2% accuracy, with precision and recall metrics both exceeding 99% across both classes. These results indicate a well-balanced model that performs consistently regardless of whether it's detecting real or fake images.
Full-Stack Deployment Architecture
To make the deepfake detection capabilities accessible to end-users, the project implements a complete web application with separate frontend and backend components. This architecture follows modern web development practices while ensuring efficient model serving and responsive user experience.
The deployment stack includes:
- Backend API (Flask): A lightweight Python web framework that hosts the trained model and provides RESTful endpoints for image processing and prediction. The backend handles image preprocessing, model inference, and result formatting, making it compatible with various AI APIs and SDKs.
- Frontend Interface: A responsive web application built with HTML, CSS, and JavaScript that provides an intuitive drag-and-drop interface for image upload, real-time processing indicators, and clear result presentation.
- Model Serving Optimization: Implementation of caching mechanisms, request queuing, and GPU acceleration to ensure fast response times even under heavy load, similar to capabilities found in professional AI model hosting platforms.
End-to-End User Workflow
The complete system operates through a streamlined workflow that balances user convenience with technical robustness:
- Image Submission: Users upload images through the web interface, with support for common formats (JPEG, PNG) and automatic validation for file size and dimensions.
- Backend Processing: The Flask API receives the image, applies necessary preprocessing (resizing, normalization), and executes the model inference pipeline.
- Real-time Analysis: The Vision Transformer processes the image, analyzing spatial relationships and texture patterns to identify manipulation artifacts that are characteristic of deepfake generation techniques.
- Confidence Scoring: The model generates both a classification (real/fake) and a confidence score that indicates the certainty of the prediction, helping users understand the reliability of each result.
- Result Delivery: The frontend displays the analysis outcome with visual indicators and explanatory text, making the technical results accessible to non-expert users.
Real-World Applications and Use Cases
The practical applications of robust deepfake detection extend across multiple domains where visual authenticity is paramount. News organizations can integrate such systems to verify user-submitted content before publication, while social media platforms could deploy similar technology to flag potentially manipulated images automatically. Legal and forensic professionals benefit from tools that provide preliminary analysis of evidence authenticity, though human expert review remains essential for critical cases. The technology also complements existing photo editor tools by adding verification capabilities.
In corporate environments, deepfake detection helps protect against sophisticated social engineering attacks that use manipulated images for identity deception. Educational institutions can use these systems to teach digital literacy and critical media evaluation skills. The growing integration of similar technologies into AI automation platforms demonstrates the increasing importance of content verification in automated workflows.
Technical Foundation: Transformer Revolution
This project builds upon the groundbreaking work presented in the "Attention Is All You Need" research paper, which introduced the transformer architecture that has since revolutionized both natural language processing and computer vision. The self-attention mechanism at the heart of transformers allows the model to weigh the importance of different image regions dynamically, making it particularly effective for detecting the subtle, globally distributed artifacts that characterize deepfake manipulations.
Unlike traditional convolutional networks that process images through local filters, transformers can capture long-range dependencies across the entire image simultaneously. This global perspective is crucial for identifying inconsistencies in lighting, texture patterns, and anatomical proportions that often betray AI-generated content. The architecture's scalability also allows it to benefit from larger datasets and more computational resources, following trends seen in comprehensive AI tool directories that track model capabilities.
Pros and Cons
Advantages
- Exceptional detection accuracy exceeding 99% on test data
- Comprehensive end-to-end implementation from data to deployment
- Open-source architecture allowing customization and extension
- Vision Transformer architecture captures global image context
- User-friendly web interface accessible to non-technical users
- Robust performance across diverse image types and qualities
- Fast inference times suitable for real-time applications
Disadvantages
- Substantial computational requirements for training
- Requires significant machine learning expertise to modify
- Performance dependent on training data quality and diversity
- Potential false positives with highly compressed images
- Limited effectiveness against never-before-seen manipulation techniques
Conclusion
This deepfake image detection project demonstrates the powerful combination of modern transformer architecture with practical full-stack implementation. By leveraging Vision Transformers, the system achieves exceptional accuracy in distinguishing authentic images from AI-generated manipulations while maintaining accessibility through a user-friendly web interface. The complete workflow—from data preparation and model training to deployment and evaluation—provides a robust framework that can be adapted to various image authentication scenarios. As deepfake technology continues to evolve, such detection systems will play an increasingly vital role in maintaining digital trust and combating visual misinformation across platforms and industries.
Frequently Asked Questions
What is deepfake image detection?
Deepfake image detection uses artificial intelligence to identify images manipulated by deep learning techniques, analyzing visual artifacts and inconsistencies that distinguish AI-generated content from authentic photographs.
How accurate is this deepfake detector?
The Vision Transformer-based detector achieves over 99% accuracy on test datasets, with balanced performance across both real and fake image classes, though performance may vary with image quality and novel manipulation techniques.
What technologies power this detection system?
The system combines Vision Transformer architecture for image analysis, TensorFlow/Keras for deep learning, Flask for backend API, and modern web technologies for the frontend interface, creating a complete full-stack application.
Can students use this project for learning?
Yes, the project is excellent for educational purposes, including coursework, research projects, or final year projects. The open-source approach allows students to study and modify the implementation while learning modern AI techniques.
What are the system requirements?
Training requires substantial GPU resources, but the deployed web application can run on standard servers. For development, Python 3.8+, TensorFlow 2.x, and common data science libraries are needed, similar to many AI development environments.