Annotation
- Introduction
- Understanding AI's Role in Data Generation
- Building a Pokémon Generator: Leveraging Arrays
- Creating a Sentiment Classifier: Harnessing Enums
- Comparing Array and Enum Generation
- Customizing AI Data Output with Zod
- Pros and Cons
- Conclusion
- Frequently Asked Questions
AI Structured Data: Arrays & Enums Guide for Developers | ToolPicker
This guide explores using arrays and enums in AI SDKs for structured data generation, with practical examples like Pokémon generators and sentiment

Introduction
As artificial intelligence continues to transform software development, mastering structured data generation becomes essential for building robust applications. This comprehensive guide explores how developers can leverage arrays and enums within AI SDKs to create organized, predictable outputs. These data structures enable more efficient processing, better type safety, and improved user experiences in AI-driven applications across various domains.
Understanding AI's Role in Data Generation
Traditional software development often requires manual data structure definition, but AI SDKs now enable dynamic generation that adapts to specific requirements. This paradigm shift allows applications to become more flexible and responsive to user needs. Arrays and enums represent two fundamental patterns that developers can implement to structure AI outputs effectively. Arrays organize related items into lists, while enums classify data into predefined categories, both providing significant benefits for data validation and processing efficiency.
The integration of these structures with modern development tools creates powerful combinations for building intelligent applications. When working with AI APIs and SDKs, understanding how to properly implement arrays and enums can dramatically improve output consistency and application reliability.
Building a Pokémon Generator: Leveraging Arrays
Arrays serve as the foundation for managing collections of similar objects in AI-generated data. Consider a practical example where you need to generate Pokémon lists based on specific types like 'fire' or 'water'. Using an AI SDK, you can instruct the model to produce structured arrays containing Pokémon names and their associated abilities. This approach requires defining a clear schema for individual Pokémon objects, then wrapping this schema in an array structure.
The implementation typically involves using Zod, a TypeScript-first schema validation library, to define the data structure:
import { z } from "zod";
export const pokemonSchema = z.object({
name: z.string(),
abilities: z.array(z.string()),
});
export const pokemonUISchema = z.array(pokemonSchema);This schema definition ensures that each Pokémon object contains a name string and an array of ability strings. The pokemonUISchema then specifies that the AI should generate multiple instances of these objects, creating a coherent list. The prompt engineering aspect involves instructing the AI to 'Generate a list of 5 {type} type Pokémon', where the type parameter dynamically adjusts based on user input.
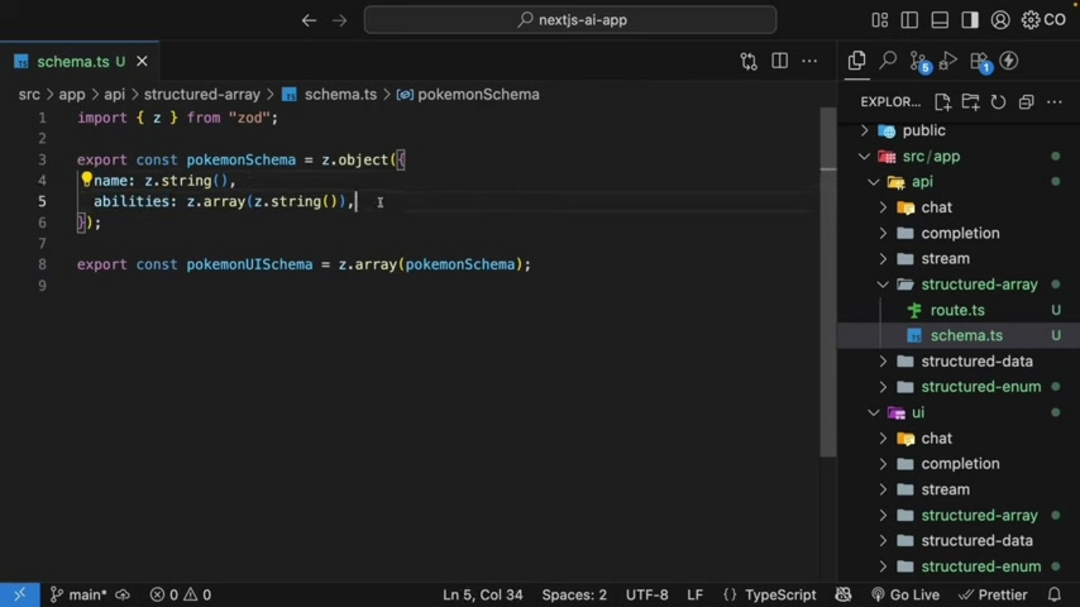
Key implementation considerations include proper schema validation, output specification in route handlers, and ensuring the AI understands the array context. This approach demonstrates how arrays can organize complex data collections for applications requiring multiple similar objects, making it particularly useful for AI automation platforms that handle repetitive data generation tasks.
Creating a Sentiment Classifier: Harnessing Enums
Enums provide a structured approach to classification tasks where outputs must fall within predefined categories. A sentiment analysis classifier perfectly illustrates this concept, where text must be categorized as positive, negative, or neutral. Unlike arrays, enums don't require complex schema definitions – instead, developers directly specify the possible values within the route handler.
The implementation typically uses the generateObject function rather than streaming approaches:
import { generateObject } from "ai";
import { openAI } from "@ai-sdk/openai";
export async function POST(req: Request) {
try {
const { text } = await req.json();
const result = await generateObject({
model: openAI("gpt-4.1-mini"),
output: "enum",
enum: ["positive", "negative", "neutral"],
prompt: `Classify the sentiment in this text: ${text}`,
});
return result.toJsonResponse();
} catch (error) {
console.error("Error generating sentiment", error);
return new Response("Failed to generate sentiment", { status: 500 });
}
}
Critical factors for successful enum implementation include model selection – more capable models like GPT-4.1-mini provide better consistency – and clear enum value definition. This approach ensures that AI outputs remain within expected boundaries, making it invaluable for AI agents and assistants that require reliable classification capabilities.
Comparing Array and Enum Generation
Understanding the distinctions between array and enum generation helps developers select the appropriate data structure for specific use cases. Arrays excel at managing collections of objects, while enums specialize in classification tasks where outputs must conform to predefined categories. The implementation differences extend beyond schema requirements to include the AI SDK functions used and how data gets processed.
Arrays typically work with streamObject for progressive data generation, making them suitable for large datasets or real-time applications. Enums, however, work best with generateObject since they produce single classification values. The table below highlights key differences:
| Feature | Arrays | Enums |
|---|---|---|
| Data Structure | List of objects | Predefined categories |
| Schema Required | Yes, defines object structure | No, values defined in handler |
| Output Type | array | enum |
| AI SDK Function | streamObject | generateObject |
| Use Case | Collections of similar objects | Classification and categorization |
| Data Processing | Returns array of objects | Returns single classified value |
These structural differences impact how developers approach AI prompt engineering and output handling, making proper selection crucial for application success.
Customizing AI Data Output with Zod
Zod provides extensive capabilities for defining and validating schemas in TypeScript applications, offering type-safe validation that ensures AI-generated data meets specific structural requirements. Beyond basic array and enum implementations, Zod supports complex validation scenarios that enhance data reliability and application robustness.
Advanced Zod features include complex object validation for nested data structures, custom validation functions for application-specific rules, and data transformations that modify outputs to better suit application needs. These capabilities become particularly valuable when working with AI writing tools that generate structured content or when implementing code formatting rules for generated outputs.
By combining Zod's validation power with AI data generation, developers can create more reliable applications that handle structured data effectively while maintaining type safety and data integrity throughout the processing pipeline.
Pros and Cons
Advantages
- Improved data consistency and predictability in AI outputs
- Enhanced type safety and reduced runtime errors
- Structured data organization for better application architecture
- Easier data validation and processing workflows
- Better integration with existing development tools and libraries
- More maintainable and scalable AI application code
- Clear separation between data structure and business logic
Disadvantages
- Additional complexity in schema definition and validation
- Potential performance overhead with complex validations
- Learning curve for developers new to structured AI data
- Limited flexibility for dynamic or unpredictable data patterns
- Dependency on specific AI models for enum consistency
Conclusion
Mastering arrays and enums for AI structured data generation represents a significant advancement in modern software development. These data structures provide the foundation for building reliable, maintainable AI applications that produce consistent, validated outputs. By understanding when to use arrays for object collections and enums for classification tasks, developers can create more robust applications that leverage AI capabilities effectively. The integration with validation libraries like Zod further enhances data reliability, while proper implementation considerations ensure optimal performance and user experience across various AI-driven applications.
Frequently Asked Questions
What is the main benefit of using arrays for AI-generated data?
Arrays provide structured organization for lists of related data points, enabling predictable iteration and processing of multiple items. This is essential when AI generates collections of similar objects like products or search results, improving data management and application reliability.
When should developers choose enums over other data structures?
Enums are ideal for classification tasks where outputs must fit predefined categories. They restrict AI responses to specific values, ensuring consistency in sentiment analysis, status classification, and decision-making processes while improving application robustness.
Can enums work with streamObject in AI SDKs?
No, enums are designed specifically for generateObject, which returns single classification values. For streaming data, developers should use arrays or other structures that support progressive output generation and real-time processing.
Why does model selection matter for enum generation?
More capable AI models provide better consistency in generating correct enum values. Less advanced models may struggle with predefined categories, leading to unpredictable results. Selecting appropriate models ensures reliable classification output.
How does Zod improve AI data validation?
Zod provides type-safe schema validation that ensures AI-generated data meets structural requirements, reducing errors and improving application reliability through defined schemas for arrays, enums, and complex objects.
Relevant AI & Tech Trends articles
Stay up-to-date with the latest insights, tools, and innovations shaping the future of AI and technology.
Grok AI: Free Unlimited Video Generation from Text & Images | 2024 Guide
Grok AI offers free unlimited video generation from text and images, making professional video creation accessible to everyone without editing skills.
Grok 4 Fast Janitor AI Setup: Complete Unfiltered Roleplay Guide
Step-by-step guide to configuring Grok 4 Fast on Janitor AI for unrestricted roleplay, including API setup, privacy settings, and optimization tips
Top 3 Free AI Coding Extensions for VS Code 2025 - Boost Productivity
Discover the best free AI coding agent extensions for Visual Studio Code in 2025, including Gemini Code Assist, Tabnine, and Cline, to enhance your