Annotation
- Introduction
- Comprendre la classification de texte personnalisée
- Pourquoi choisir le service Azure AI Language pour la classification de texte
- Configuration du service Azure AI Language
- Entraînement de votre modèle de classification de texte personnalisé
- Structure de tarification du service Azure AI Language
- Fonctionnalités et capacités principales
- Applications pratiques et cas d'utilisation
- Défis courants d'implémentation
- Avantages et inconvénients
- Conclusion
- Questions fréquemment posées
Service de langage Azure AI : Guide de configuration et de formation de la classification de texte personnalisée
Apprenez à mettre en œuvre la classification de texte personnalisée avec le service de langage Azure AI, de la configuration et de la formation au déploiement, pour un texte précis

Introduction
Dans l'environnement commercial riche en données d'aujourd'hui, catégoriser et comprendre efficacement les données textuelles est devenu essentiel pour prendre des décisions éclairées. Le service Azure AI Language de Microsoft offre des capacités puissantes de traitement du langage naturel, y compris la classification de texte personnalisée qui permet aux organisations de créer des systèmes de catégorisation sur mesure. Ce tutoriel complet vous guide à travers le processus complet de configuration, d'entraînement et de déploiement de modèles de classification de texte personnalisés en utilisant l'infrastructure cloud d'Azure.
Comprendre la classification de texte personnalisée
La classification de texte personnalisée représente une approche d'apprentissage automatique spécialisée qui attribue automatiquement des catégories prédéfinies aux documents textuels en fonction de vos besoins commerciaux spécifiques. Contrairement à l'analyse de texte générale qui pourrait se concentrer sur l'analyse des sentiments ou l'extraction de phrases clés, la classification de texte personnalisée vous permet de définir des catégories spécifiques au domaine qui correspondent à vos besoins organisationnels. Par exemple, vous pourriez classer les tickets de support client en catégories comme 'Problème technique', 'Demande de facturation' ou 'Demande de fonctionnalité' – fournissant un contexte immédiat pour le routage et la résolution.
Le service Azure AI Language offre des capacités de niveau entreprise pour créer des solutions de classification de texte sophistiquées qui évoluent avec votre volume de données et vos exigences de complexité.
Pourquoi choisir le service Azure AI Language pour la classification de texte
Le service Azure AI Language offre plusieurs avantages convaincants pour les organisations mettant en œuvre la classification de texte personnalisée. L'architecture cloud-native de la plateforme assure une évolutivité transparente pour gérer des volumes de texte massifs sans dégradation des performances. Les algorithmes avancés d'apprentissage automatique et les techniques de traitement du langage naturel offrent des taux de précision élevés, tandis que les options de personnalisation vous permettent d'entraîner des modèles spécifiquement sur votre domaine de données. Le service s'intègre facilement avec d'autres API et SDK IA et plateformes d'automatisation IA, créant un écosystème IA complet. Le modèle de tarification à l'usage offre une flexibilité d'optimisation des coûts, le rendant accessible pour les petites expériences et les déploiements de production à grande échelle.
Configuration du service Azure AI Language
Avant de commencer le processus de configuration, assurez-vous d'avoir un abonnement Azure actif. Microsoft propose des comptes d'essai gratuits pour les nouveaux utilisateurs, offrant du crédit pour explorer les services sans engagement financier immédiat. Le processus de configuration implique plusieurs étapes clés qui établissent la base de vos projets de classification de texte.
La première étape consiste à créer une ressource Azure AI Language via le portail Azure. Cette ressource sert de point de gestion central pour vos modèles de classification de texte personnalisés et fournit un accès à Language Studio – l'interface web pour le développement de modèles. Après vous être connecté à portal.azure.com avec vos identifiants, naviguez vers 'Créer une ressource' et recherchez 'Language Service'. Sélectionnez le service approprié dans les résultats et procédez à la création.
Pendant la configuration, fournissez les détails essentiels, y compris votre abonnement Azure, le groupe de ressources pour la gestion organisationnelle, et la sélection de la région géographique – choisir des emplacements près de vos sources de données peut améliorer les performances. Attribuez un nom unique à votre ressource Language Service et sélectionnez le niveau de tarification qui correspond à la portée de votre projet. Le niveau gratuit F0 fonctionne bien pour l'expérimentation, tandis que les environnements de production nécessitent généralement les niveaux Standard ou Premium pour des limites de transaction plus élevées et des fonctionnalités avancées.
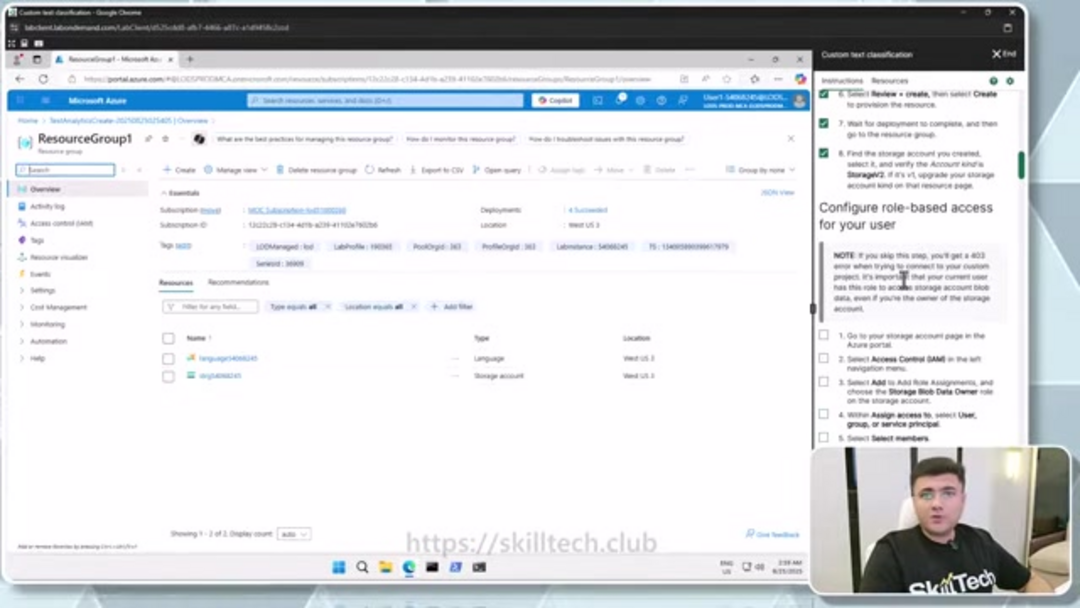
Le service Azure AI Language nécessite des comptes de stockage associés pour la fonctionnalité opérationnelle. Pendant la création de la ressource, vous configurerez un nouveau compte de stockage ou lierez un existant, en vous assurant que Standard LRS (Stockage Redondant Localement) est sélectionné pour la fiabilité. Après le déploiement, configurez le contrôle d'accès basé sur les rôles en naviguant vers la section Contrôle d'accès (IAM) de votre compte de stockage. Ajoutez une attribution de rôle en sélectionnant 'Propriétaire des données blob de stockage' et attribuez-la à votre compte utilisateur, permettant les permissions appropriées pour les opérations d'entraînement de modèles.
Entraînement de votre modèle de classification de texte personnalisé
Avec l'infrastructure établie, le processus d'entraînement du modèle commence par la préparation et l'étiquetage des données – étapes critiques qui impactent directement la précision et les performances de classification.
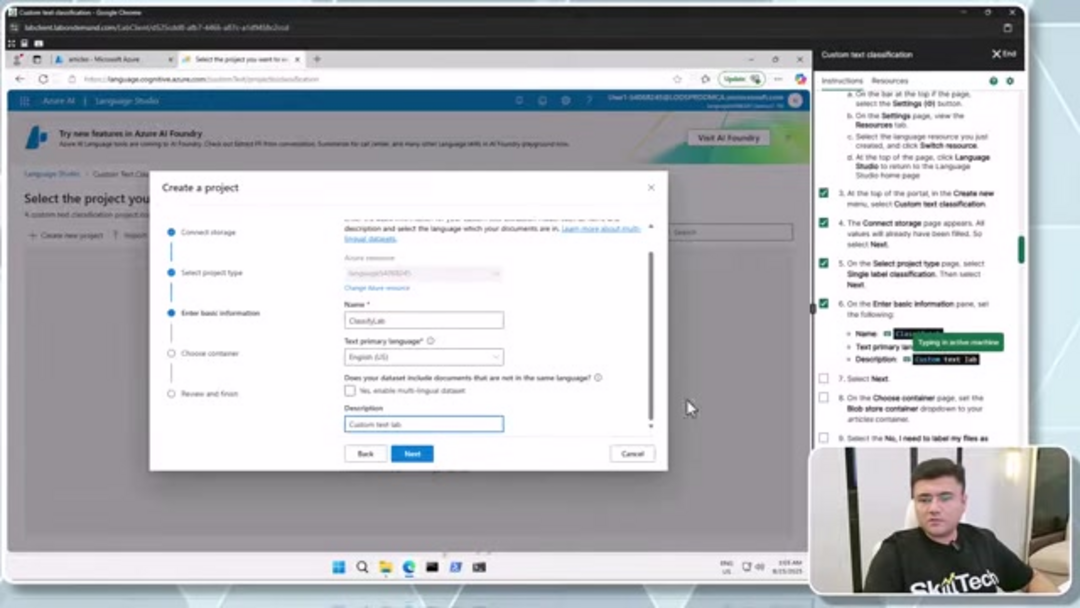
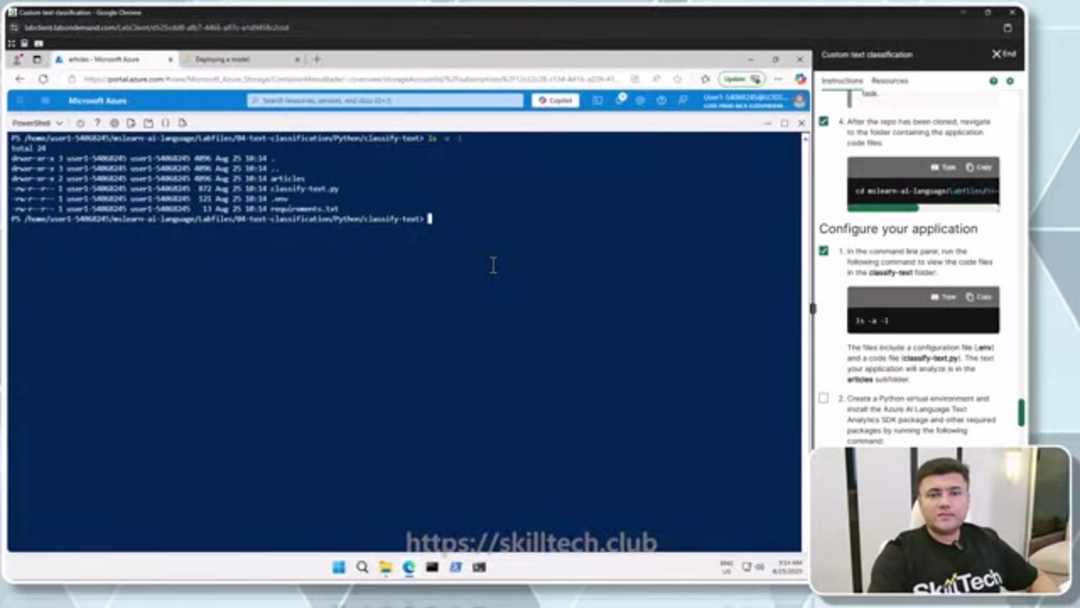
Commencez par créer un conteneur dédié dans votre compte de stockage spécifiquement pour les documents d'entraînement. Naviguez vers la section Conteneurs et créez un nouveau conteneur nommé "articles" avec le niveau d'accès défini sur "Conteneur" pour permettre les opérations blob appropriées. Téléchargez vos exemples de documents – ceux-ci doivent représenter les diverses catégories de texte que vous souhaitez classer. Pour des résultats optimaux, assurez-vous que votre jeu de données d'entraînement inclut suffisamment d'exemples de chaque catégorie, avec des documents qui représentent de manière réaliste les variations de texte que votre modèle rencontrera en production. Cette phase de préparation est cruciale pour construire des agents et assistants IA efficaces qui peuvent traiter et catégoriser les informations avec précision.
L'étiquetage des données fournit la base structurée qui permet à votre modèle d'apprendre les distinctions de catégories. Dans Language Studio, accédez à la section Étiquetage des données où vous verrez les fichiers téléchargés de votre compte de stockage. Créez des classes personnalisées qui correspondent à vos besoins de classification – par exemple, vous pourriez établir des catégories comme 'Sports', 'Actualités', 'Divertissement', et 'Petites annonces' pour une application média. Attribuez systématiquement chaque document à sa catégorie appropriée, en assurant un étiquetage cohérent à travers votre jeu de données. Cette approche méticuleuse de la préparation des données influence significativement la précision du modèle et sa capacité de généralisation.
Initiez le processus d'entraînement en accédant aux Travaux d'entraînement dans Language Studio. Créez un nouveau travail d'entraînement nommé de manière appropriée pour votre projet, tel que "ClassifyArticles". Configurez la division des données entre les ensembles d'entraînement et de test – la division par défaut 80/20 fournit généralement un bon équilibre entre l'apprentissage du modèle et la validation. Pendant l'entraînement, Azure emploie des techniques avancées d'apprentissage automatique pour analyser les modèles dans vos données étiquetées et construire des capacités de classification. Après la fin de l'entraînement, évaluez les performances du modèle en utilisant les métriques fournies, y compris les mesures de précision, de rappel et de score F1 qui indiquent à quel point votre modèle distingue entre les catégories.
Structure de tarification du service Azure AI Language
Comprendre le modèle de tarification d'Azure aide à la planification budgétaire et à l'optimisation des coûts. Le niveau gratuit (F0) fournit des transactions mensuelles limitées adaptées à l'expérimentation et aux projets de preuve de concept. Le niveau standard (S0) fonctionne sur une tarification à l'usage basée sur le volume de transactions, idéal pour les applications en croissance avec des modèles d'utilisation variables. Le niveau premium offre une tarification de capacité réservée pour les déploiements d'entreprise à volume élevé nécessitant des coûts prévisibles et un débit maximum. Considérez votre volume de traitement de texte attendu et vos exigences de temps de réponse lors de la sélection du niveau approprié pour votre implémentation.
Fonctionnalités et capacités principales
Le service Azure AI Language offre une fonctionnalité complète de traitement du langage naturel au-delà de la classification de texte personnalisée. L'analyse des sentiments détermine le ton émotionnel dans le texte, tandis que l'extraction de phrases clés identifie les concepts et sujets centraux. La détection de langue reconnaît automatiquement la langue du texte, et la reconnaissance d'entités nommées identifie les personnes, organisations et lieux mentionnés dans le contenu. Le service prend également en charge la reconnaissance d'entités nommées personnalisée pour les entités spécifiques au domaine et la réponse aux questions personnalisée pour construire des bases de connaissances intelligentes. Ces capacités peuvent être combinées pour créer des outils d'écriture IA et des chatbots IA sophistiqués qui comprennent et traitent le langage naturel efficacement.
Applications pratiques et cas d'utilisation
La classification de texte personnalisée trouve des applications dans de nombreuses industries et fonctions commerciales. Les organisations de service client automatisent la catégorisation des tickets, acheminant les demandes vers les équipes appropriées basées sur l'analyse du contenu. Les prestataires de soins de santé classent les dossiers médicaux et les retours des patients pour améliorer la coordination des soins et l'efficacité opérationnelle. Les institutions financières analysent les documents, les actualités et les rapports pour l'évaluation des risques et l'identification des opportunités. Les plateformes de commerce électronique catégorisent les avis sur les produits et les retours des clients pour améliorer la découverte et la satisfaction. Les entreprises médiatiques classent le contenu pour des recommandations personnalisées et l'engagement du public. Ces applications démontrent comment la classification de texte s'intègre avec les outils de conversation IA et les assistants email IA pour automatiser le traitement de l'information.
Défis courants d'implémentation
Plusieurs défis peuvent survenir pendant les projets de classification de texte personnalisée. Le déséquilibre des données se produit lorsque certaines catégories ont significativement plus d'exemples d'entraînement que d'autres, créant potentiellement des modèles biaisés – des techniques comme la suréchantillonnage des classes minoritaires peuvent résoudre ce problème. Le surajustement se produit lorsque les modèles deviennent trop complexes et performent mal sur de nouvelles données – la régularisation et la validation croisée aident à maintenir la généralisation. La disponibilité limitée de données étiquetées peut contraindre l'entraînement des modèles – les approches d'apprentissage actif et les techniques de transfert d'apprentissage peuvent optimiser les jeux de données limités. Les définitions de catégories ambiguës confondent les modèles pendant l'entraînement – passer suffisamment de temps à établir des catégories claires et distinctes améliore les résultats. Les problèmes de qualité des données, y compris le bruit et l'incohérence, impactent les performances – un nettoyage approfondi des données et un prétraitement établissent une base solide pour une classification précise.
Avantages et inconvénients
Avantages
- Infrastructure cloud hautement évolutive gère efficacement les grands volumes de texte
- Les algorithmes avancés d'apprentissage automatique offrent des résultats de classification précis
- Options de personnalisation complètes pour les définitions de catégories spécifiques au domaine
- Intégration transparente avec l'écosystème complet des services Azure
- Tarification flexible à l'usage optimise les coûts opérationnels
- Sécurité de niveau entreprise et certifications de conformité
- Amélioration continue des modèles grâce aux capacités de réentraînement
Inconvénients
- Nécessite un abonnement Azure actif et une dépendance au cloud
- Courbe d'apprentissage plus raide pour les nouveaux venus aux services Azure
- Les coûts peuvent augmenter significativement avec une utilisation à volume élevé
- Fonctionnalité hors ligne limitée due à la nature cloud
- Considérations de gouvernance des données pour les informations sensibles
Conclusion
Le service Azure AI Language fournit une plateforme robuste et évolutive pour implémenter des solutions de classification de texte personnalisées qui transforment le texte non structuré en informations catégorisées actionnables. En suivant le processus complet de configuration, d'entraînement et de déploiement décrit dans ce guide, les organisations peuvent construire des systèmes de classification sur mesure qui répondent à des besoins commerciaux spécifiques. Les capacités d'intégration du service avec d'autres services Azure AI et les modèles de tarification flexibles le rendent accessible pour des projets de différentes échelles et complexités. Alors que les données textuelles continuent de croître en volume et en importance, maîtriser la classification de texte personnalisée devient de plus en plus précieux pour extraire des insights, automatiser les processus et améliorer la prise de décision à travers les fonctions commerciales.
Questions fréquemment posées
À quoi sert le service de langage Azure AI ?
Le service de langage Azure AI est une plateforme de traitement du langage naturel basée sur le cloud qui fournit des capacités d'analyse de texte, y compris l'analyse des sentiments, l'extraction de phrases clés, la détection de la langue, la reconnaissance d'entités nommées et la classification de texte personnalisée pour les applications métier.
Combien coûte le service de langage Azure AI ?
Le service de langage Azure AI propose un niveau Gratuit (F0) pour l'expérimentation, des tarifs Standard (S0) à l'usage pour les applications en croissance, et un niveau Premium avec capacité réservée pour les déploiements d'entreprise avec des coûts prévisibles basés sur le volume de transactions.
Quels sont les principaux défis de la classification de texte personnalisée ?
Les principaux défis incluent le déséquilibre des données entre les catégories, le surajustement du modèle, les données d'entraînement étiquetées limitées, les définitions de catégories ambiguës et les problèmes de qualité des données qui nécessitent un prétraitement minutieux et une configuration du modèle.
Quelle est la précision de la classification de texte personnalisée d'Azure ?
La précision dépend de la qualité et de la quantité des données d'entraînement, mais les algorithmes avancés d'apprentissage automatique d'Azure offrent généralement des taux de précision et de rappel élevés lorsqu'ils sont correctement entraînés avec des documents représentatifs suffisants et bien étiquetés.
Combien de temps faut-il pour entraîner un modèle de classification de texte personnalisée ?
Le temps d'entraînement varie en fonction de la taille et de la complexité des données, mais il se situe généralement entre quelques minutes et plusieurs heures pour les grands ensembles de données en utilisant l'infrastructure évolutive d'Azure.
Articles pertinents sur l'IA et les tendances technologiques
Restez à jour avec les dernières informations, outils et innovations qui façonnent l'avenir de l'IA et de la technologie.
Grok AI : Génération Illimitée de Vidéos Gratuite à partir de Texte et d'Images | Guide 2024
Grok AI propose une génération illimitée de vidéos gratuite à partir de texte et d'images, rendant la création de vidéos professionnelles accessible à tous sans compétences en montage.
Configuration de Grok 4 Fast sur Janitor AI : Guide Complet de Jeu de Rôle Sans Filtre
Guide étape par étape pour configurer Grok 4 Fast sur Janitor AI pour un jeu de rôle sans restriction, incluant la configuration de l'API, les paramètres de confidentialité et les conseils d'optimisation
Top 3 des extensions de codage IA gratuites pour VS Code 2025 - Boostez votre productivité
Découvrez les meilleures extensions d'agents de codage IA gratuites pour Visual Studio Code en 2025, y compris Gemini Code Assist, Tabnine et Cline, pour améliorer votre