Annotation
- Введение
- Понимание нулевой классификации текста
- Традиционные и нулевые подходы к классификации
- Обзор библиотеки Hugging Face Transformers
- Улучшение производительности нулевой классификации
- Практическое руководство по реализации
- Цены и лицензирование Hugging Face
- Плюсы и минусы
- Реальные приложения и случаи использования
- Заключение
- Часто задаваемые вопросы
Классификация текста с нулевым обучением с помощью Hugging Face: Полное практическое руководство
Классификация текста с нулевым обучением с помощью Hugging Face позволяет классифицировать текст без обучающих данных. Это руководство охватывает реализацию, преимущества и код
Введение
Традиционная классификация текста долгое время опиралась на обширные размеченные наборы данных, требуя значительных ручных усилий и ресурсов. Однако нулевая классификация текста представляет собой смену парадигмы в обработке естественного языка, позволяя моделям ИИ категоризировать текст в предопределенные классы без какого-либо предварительного обучения на размеченных примерах. Этот революционный подход использует мощность предварительно обученных языковых моделей из библиотеки Hugging Face Transformers, делая классификацию текста доступной даже когда размеченные данные недоступны. Это всеобъемлющее руководство исследует практическую реализацию, преимущества и реальные применения нулевой классификации для разработчиков и ученых по данным.
Понимание нулевой классификации текста
Что такое нулевая классификация текста?
Нулевая классификация текста представляет собой передовую технику машинного обучения, где модели категоризируют текст в классы, которые они никогда не встречали во время обучения. В отличие от традиционных подходов, которые требуют обширных размеченных наборов данных, нулевая классификация использует возможности семантического понимания больших языковых моделей. Эти модели, обученные на массивных корпусах текста, развивают сложные представления о языковых отношениях, позволяя им обобщать на новые задачи классификации без дополнительного обучения. Эта способность особенно ценна в динамичных средах, где категории часто меняются или когда размеченные данные scarce.
Основной механизм включает сравнение семантического сходства между входным текстом и кандидатными метками, используя предварительные знания модели. Когда вы предоставляете образец текста и потенциальные категории, модель оценивает, насколько близко текст соответствует каждой метке на основе ее понимания языковых паттернов и контекстуальных отношений. Этот подход устраняет необходимость в трудоемком размечении данных и переобучении модели, делая его идеальным для быстрого прототипирования и развертывания в производственных средах.
Традиционные и нулевые подходы к классификации
Традиционная классификация текста следует парадигме обучения с учителем, требуя тщательно подобранных наборов данных, где каждый текстовый пример вручную размечен соответствующей категорией. Этот процесс включает сбор тысяч примеров, их аннотирование подходящими метками и обучение специализированной модели, которая учится распознавать паттерны, связанные с каждой категорией. Хотя эффективный, этот подход требует значительных ресурсов и становится непрактичным при работе с новыми темами или быстро меняющимися потребностями классификации.
Нулевая классификация фундаментально отличается использованием моделей, которые уже развили всестороннее понимание языка через предварительное обучение на разнообразных текстовых источниках. Эти модели могут выводить отношения между новым текстом и кандидатными метками без специфического обучения на целевых категориях. Преимущества выходят за рамки просто устранения размечения данных – нулевая классификация предлагает замечательную гибкость, позволяя вам мгновенно адаптироваться к новым схемам классификации, просто изменяя кандидатные метки. Это делает ее особенно ценной для приложений в ИИ чат-ботах и инструментах разговорного ИИ, где пользовательские запросы могут охватывать разнообразные темы.
Обзор библиотеки Hugging Face Transformers
Библиотека Hugging Face Transformers стала определяющим ресурсом для современной обработки естественного языка, предоставляя упрощенный доступ к передовым предварительно обученным моделям. Эта всеобъемлющая библиотека абстрагирует сложности архитектуры модели и реализации, позволяя разработчикам сосредоточиться на решении практических проблем, а не технических деталях. Для нулевой классификации specifically, Hugging Face предлагает оптимизированные версии популярных моделей, таких как BERT, RoBERTa и DistilBERT, каждая с distinct преимуществами и характеристиками производительности.
Что делает библиотеку особенно мощной, так это ее интуитивный интерфейс pipeline, который позволяет выполнять сложные задачи НЛП с минимальным кодом. Pipeline нулевой классификации обрабатывает всю underlying сложность, включая токенизацию, вывод модели и интерпретацию результатов, предоставляя чистый, удобный API. Эта доступность демократизировала передовые возможности НЛП, делая их доступными для разработчиков без глубоких знаний в машинном обучении или архитектурах трансформеров. Совместимость библиотеки с различными ИИ API и SDK further enhances its utility в производственных средах.
Улучшение производительности нулевой классификации
Выбор оптимальных предварительно обученных моделей
Выбор правильной предварительно обученной модели значительно влияет на точность и производительность нулевой классификации. Разные модели преуспевают в различных сценариях based на их обучающих данных, архитектуре и предполагаемых случаях использования. BERT (Bidirectional Encoder Representations from Transformers) остается популярным выбором для его robust производительности across diverse текстовых типов, having been trained на Wikipedia и book corpus данных. Его bidirectional attention mechanism позволяет ему понимать контекст с обоих направлений, делая его particularly эффективным для nuanced задач классификации.
RoBERTa (Robustly Optimized BERT Pretraining Approach) представляет оптимизированную версию, которая удаляет next-sentence prediction objective BERT и employs более extensive обучение с larger batches и longer sequences. Эти оптимизации often result в superior производительности для нулевых задач. Для resource-constrained сред, DistilBERT предлагает compelling альтернативу – эта distilled версия maintains approximately 97% производительности BERT while being 40% smaller и 60% faster, делая ее ideal для приложений, requiring rapid inference или развертывания на limited hardware.
Стратегическая формулировка кандидатных меток
Качество и формулировка кандидатных меток directly influence точность классификации в нулевых сценариях. Эффективные метки должны быть описательными, недвусмысленными и семантически distinct друг от друга. Instead of использования single-word категорий like "sports," consider более descriptive phrases like "professional sports news" или "amateur athletic activities," которые provide clearer semantic signals к модели. Эта specificity помогает модели better понимать intended границы категоризации и reduces confusion между similar концепциями.
When dealing с hierarchical системами категоризации, вы можете structure метки to reflect эти relationships. Например, instead of использования flat меток like "basketball" и "football," вы можете implement hierarchical подход с "sports - basketball - NBA" и "sports - football - NFL." Эта structured маркировка может improve точность by leveraging понимание модели отношений категорий. Additionally, consider включение negative примеров или out-of-scope меток when appropriate, так как это помогает модели better различать между relevant и irrelevant классификациями для вашего specific случая использования.
Стратегии тонкой настройки для конкретной области
While нулевая классификация works remarkably well out-of-the-box, производительность может быть further enhanced через domain-specific тонкую настройку when specialized терминология или контекст involved. Тонкая настройка involves additional обучение на small наборе данных relevant к вашей specific области, allowing модели adapt ее понимание к specialized словарю и концепциям. Этот подход particularly ценен для technical областей like медицинская литература, legal документы или scientific papers, где standard языковые модели могут struggle с domain-specific терминологией.
Процесс тонкой настройки typically requires modest набор данных размеченных примеров из вашей target области – often just a few hundred samples могут yield significant улучшения. During тонкой настройки, модель adjusts ее parameters to better распознавать паттерны и relationships specific к вашей области while retaining ее general языковое понимание capabilities. Этот hybrid подход combines гибкость нулевой классификации с precision адаптации области, делая его ideal для specialized приложений в платформах автоматизации ИИ и enterprise системах.
Практическое руководство по реализации
Настройка среды и установка
Начало работы с нулевой классификацией требует minimal настройки, благодаря well-designed экосистеме Hugging Face. Начните с установки необходимых Python пакетов using pip. Библиотека transformers предоставляет core функциональность, while pandas предлагает convenient возможности манипуляции данными для handling текстовых наборов данных. Для optimal производительности, ensure вы используете Python среду с version 3.7 или higher, и consider настройку GPU ускорения if available, так как это может significantly ускорить inference для larger наборов данных.
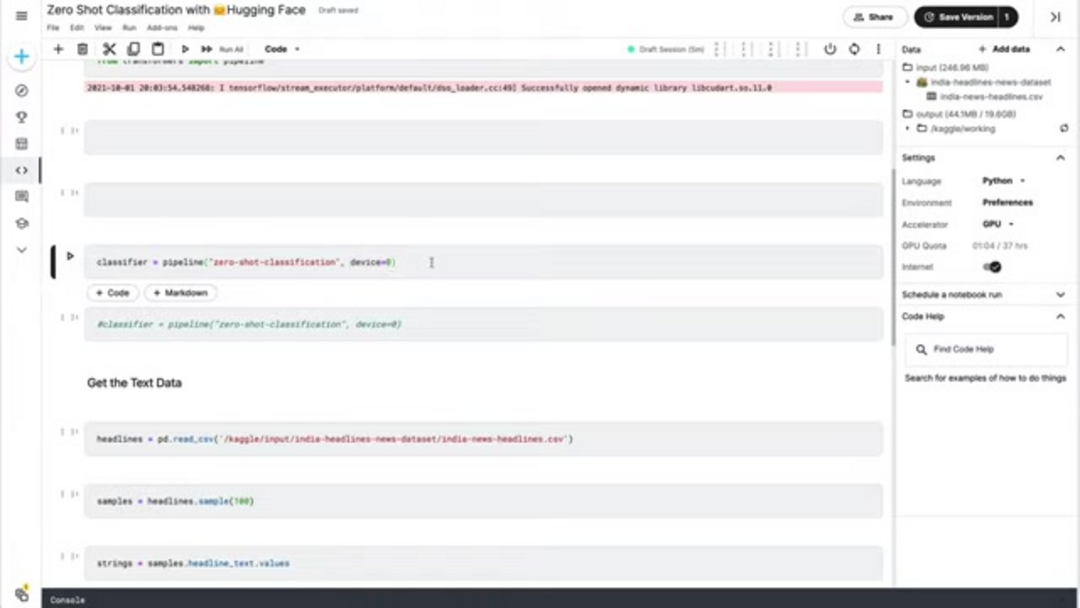
pip install transformers pandas torchПосле установки, import необходимые components в вашем Python скрипте или notebook. Функция pipeline из transformers предоставляет high-level интерфейс для нулевой классификации, while pandas facilitates загрузку данных и манипуляцию. Если у вас есть CUDA-совместимый GPU available, PyTorch automatically leverage его для accelerated вычислений, though CPU выполнение remains fully functional для smaller-scale приложений.
from transformers import pipeline
import pandas as pdПодготовка данных и инициализация классификатора
Proper подготовка данных crucial для effective нулевой классификации. Начните с загрузки ваших текстовых данных из source файлов – common форматы include CSV, JSON, или plain текстовые файлы. Для demonstration целей, мы предположим CSV файл, содержащий новостные заголовки, но подход обобщается на любой текстовый source. Ensure ваши текстовые данные clean и properly отформатированы, так как extraneous символы или проблемы форматирования могут impact точность классификации.
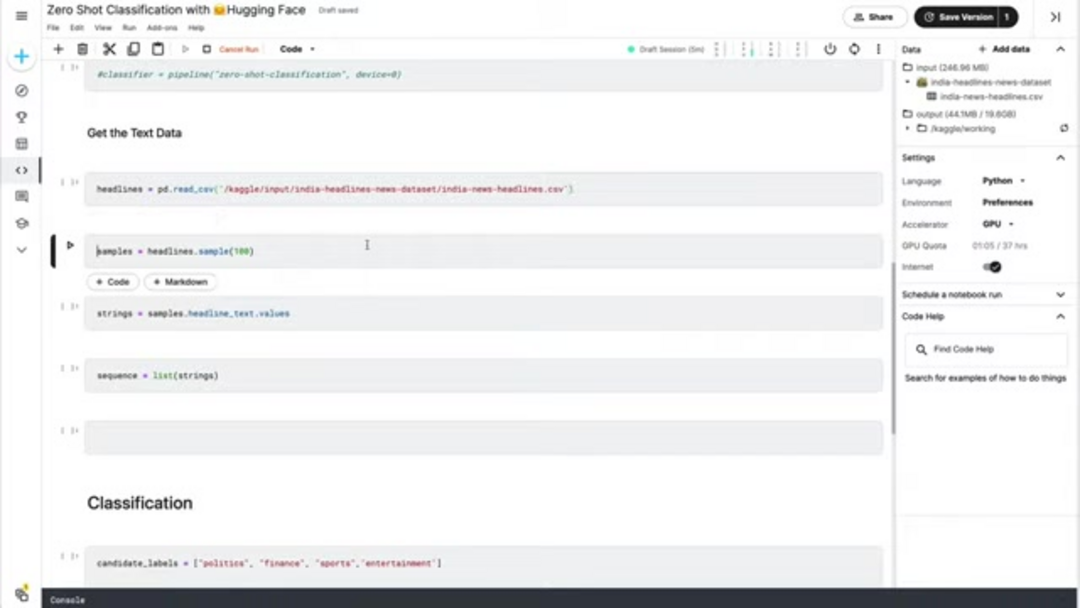
# Load headline data from CSV
headlines_df = pd.read_csv('news_headlines.csv')
headline_samples = headlines_df['headline_text'].sample(100).tolist()Инициализируйте нулевой классификатор using функцию pipeline Hugging Face. Параметр device позволяет вам specify whether использовать CPU или GPU обработку – setting device=0 enables первый available GPU для accelerated inference. Классификатор automatically downloads и configures appropriate предварительно обученную модель, typically версию BERT optimized для нулевых задач.
# Initialize classifier with GPU acceleration
classifier = pipeline('zero-shot-classification', device=0)Выполнение классификации и анализ результатов
С вашими данными prepared и классификатором инициализированным, define ваши кандидатные метки based на категориях, которые вы хотите идентифицировать. Эти метки represent потенциальные классификации для ваших текстовых данных. Выберите метки, которые mutually exclusive и comprehensively cover ожидаемые типы контента в вашем наборе данных. Для новостной категоризации, typical метки might include политика, бизнес, спорт, развлечения, технологии, и здоровье.
candidate_labels = ['politics', 'business', 'sports', 'entertainment', 'technology', 'health']Выполните классификацию, передав ваши текстовые samples и кандидатные метки классификатору. Модель returns probability scores для каждой метки, indicating how strongly текст aligns с каждой категорией. Вы можете process эти results to assign highest-probability метку к каждому текстовому sample или implement threshold-based фильтрацию to exclude low-confidence классификации.
# Perform classification
classification_results = classifier(headline_samples, candidate_labels)
# Analyze and display results
for i, result in enumerate(classification_results):
top_label = result['labels'][0]
confidence = result['scores'][0]
print(f"Sample {i+1}: {headline_samples[i][:50]}...")
print(f"Predicted: {top_label} (confidence: {confidence:.3f})")
print("---")Цены и лицензирование Hugging Face
Основная библиотека Hugging Face Transformers и большинство предварительно обученных моделей available под open-source лицензиями, primarily Apache 2.0, allowing free использование для both research и commercial приложений. Эта доступность была instrumental в widespread adoption моделей трансформеров across отраслей. Open-source nature enables разработчикам inspect, modify, и extend кодобазу to meet specific требования без licensing restrictions или costs.
Для enterprise пользователей, requiring enhanced возможности, Hugging Face предлагает premium услуги including accelerated inference APIs, dedicated expert поддержка, и private хостинг моделей. Эти услуги typically operate на subscription моделях с pricing based на usage volume и required features. Inference API предоставляет optimized инфраструктуру развертывания с guaranteed performance SLAs, while expert поддержка предлагает direct доступ к technical команде Hugging Face для assistance с complex реализациями и optimization challenges. Эти услуги particularly ценны для организаций, использующих хостинг моделей ИИ решения в масштабе.
Плюсы и минусы
Преимущества
- Устраняет необходимость в дорогостоящем и трудоемком размечении данных
- Мгновенно адаптируется к новым категориям без переобучения модели
- Возможность быстрого развертывания для proof-of-concept и производства
- Экономически эффективное решение для организаций с ограниченными ресурсами МЛ
- Отличная производительность на общей классификации текста домена
- Масштабируемость across multiple языков и текстовых типов
- Непрерывное улучшение по мере обновления базовых моделей
Недостатки
- Нижняя точность по сравнению с обученными моделями с ample размеченными данными
- Изменчивость производительности across different областей и текстовых типов
- Зависимость от качества и специфичности кандидатных меток
- Ограниченный контроль над поведением модели и границами решений
- Потенциальное унаследованное смещение из источников предварительного обучения данных
Реальные приложения и случаи использования
Нулевая классификация текста находит приложения across многочисленные отрасли и сценарии, где быстрая, гибкая категоризация текста ценна. В системах управления контентом, она enables automatic тегирование статей, постов блогов, и документов без manual вмешательства. Новостные организации leverage нулевую классификацию to categorize входящие статьи в тематические разделы, while e-commerce платформы используют ее to organize отзывы о продуктах и обратную связь клиентов по теме или настроению.
Операции обслуживания клиентов benefit от automatic маршрутизации тикетов поддержки и запросов к appropriate отделам based на анализе контента. Социальные медиа платформы и онлайн-сообщества employ нулевую классификацию для модерации контента, identifying inappropriate материал или categorizing пользовательский контент. Исследовательские учреждения используют технику to organize академические статьи и научную литературу по области или методологии. Эти приложения демонстрируют versatility нулевой классификации across агентов и ассистентов ИИ и различных бизнес-контекстах.
Заключение
Нулевая классификация текста представляет значительное продвижение в обработке естественного языка, демократизируя доступ к мощным возможностям категоризации текста без традиционного требования к размеченным обучающим данным. Используя предварительно обученные модели из библиотеки Hugging Face Transformers, разработчики и организации могут быстро implement гибкие системы классификации, которые адаптируются к evolving потребностям. Хотя подход may not always match precision полностью supervised методов с abundant размеченными данными, его гибкость, скорость, и экономическая эффективность делают его invaluable для многочисленных практических приложений. Поскольку языковые модели continue улучшаться, возможности нулевой классификации likely expand further, открывая новые возможности для intelligent обработки текста across отраслей и случаев использования. Для тех, кто исследует различные ИИ решения, всеобъемлющие каталоги инструментов ИИ могут предоставить additional контекст и альтернативы.
Часто задаваемые вопросы
Какие типы текста лучше всего подходят для классификации с нулевым обучением?
Классификация с нулевым обучением хорошо работает с текстами общей тематики, такими как новостные статьи, отзывы о продуктах, электронные письма и посты в социальных сетях. Технический или узкоспециализированный контент может потребовать адаптации к предметной области для оптимальных результатов.
Сколько кандидатов-меток мне следует использовать?
Используйте 4-8 четко определенных, различных меток для наилучшей производительности. Слишком много несвязанных меток могут размыть результаты, а слишком мало могут не охватить все соответствующие категории в ваших текстовых данных.
Всегда ли классификация с нулевым обучением превосходит традиционную классификацию?
Нет – при наличии обильных, качественных размеченных данных контролируемые методы часто достигают более высокой точности. Классификация с нулевым обучением превосходит, когда размеченных данных мало, категории часто меняются или приоритет отдается быстрому развертыванию.
Могу ли я повысить точность классификации с нулевым обучением?
Да – попробуйте различные предварительно обученные модели, уточните кандидатов-меток для ясности, используйте иерархическую маркировку для сложных категорий и рассмотрите тонкую настройку для конкретной предметной области с ограниченными размеченными данными, когда они доступны.
Как классификация с нулевым обучением обрабатывает неоднозначный текст?
Классификация с нулевым обучением может испытывать трудности с неоднозначным текстом, поскольку она полагается на семантическое сходство. Использование более четких кандидатов-меток и контекста может помочь повысить точность в таких случаях.
Релевантные статьи об ИИ и технологических трендах
Будьте в курсе последних инсайтов, инструментов и инноваций, формирующих будущее ИИ и технологий.
Grok AI: Бесплатное неограниченное создание видео из текста и изображений | Руководство 2024
Grok AI предлагает бесплатное неограниченное создание видео из текста и изображений, делая профессиональное создание видео доступным для всех без навыков редактирования.
Настройка Grok 4 Fast в Janitor AI: Полное руководство по ролевой игре без фильтров
Пошаговое руководство по настройке Grok 4 Fast в Janitor AI для неограниченной ролевой игры, включая настройку API, параметры конфиденциальности и советы по оптимизации
Топ-3 бесплатных расширений для ИИ-программирования в VS Code 2025 - Повышение производительности
Откройте для себя лучшие бесплатные расширения для ИИ-программирования в Visual Studio Code в 2025 году, включая Gemini Code Assist, Tabnine и Cline, чтобы улучшить вашу