Annotation
- Introducción
- Evolución de las Técnicas de Clasificación de Texto
- La Revolución del Transformador en el PLN
- Marcos de Aprendizaje Profundo para Clasificación de Texto
- Aprendizaje por Transferencia con Modelos Pre-entrenados
- Implementación Práctica con ULMFiT
- Ventajas y Desventajas
- Aplicaciones y Herramientas del Mundo Real
- Análisis de Texto Empresarial con Gong.io
- Etiquetado y Programación Automatizada de Correos Electrónicos
- Direcciones Futuras en Clasificación de Texto
- Conclusión
- Preguntas frecuentes
Guía Avanzada de Clasificación de Texto: Marcos de Aprendizaje Profundo y Técnicas
Guía avanzada de clasificación de texto que cubre marcos de aprendizaje profundo, BERT, transformadores, aprendizaje por transferencia y aplicaciones del mundo real para una precisión

Introducción
La clasificación de texto representa un pilar fundamental del Procesamiento del Lenguaje Natural, capacitando a los sistemas para categorizar e interpretar automáticamente datos de texto no estructurados. Esta guía completa explora cómo los marcos de aprendizaje profundo han transformado las capacidades de clasificación de texto, permitiendo una precisión sin precedentes en la categorización de documentos, el análisis de sentimientos y la organización automatizada de contenido. Ya sea que estés construyendo automatización de servicio al cliente o sistemas de moderación de contenido, comprender estas técnicas avanzadas es esencial para las aplicaciones modernas de IA.
Evolución de las Técnicas de Clasificación de Texto
La progresión de las metodologías de clasificación de texto refleja avances más amplios en lingüística computacional y aprendizaje automático. Los enfoques tempranos dependían en gran medida de métodos estadísticos que trataban el texto como simples colecciones de palabras sin considerar relaciones semánticas o significado contextual.

El modelo Bag of Words surgió como un estándar temprano, representando documentos como vectores de frecuencia de palabras mientras ignoraba completamente la gramática, el orden de las palabras y el contexto semántico. Aunque sencillo de implementar y proporcionando resultados interpretables, BoW sufría de limitaciones significativas incluyendo restricciones de vocabulario e incapacidad para capturar relaciones entre palabras. Por ejemplo, trataría "gato" y "gatito" como entidades completamente distintas sin conexión semántica, y procesaría "la película fue divertida y no aburrida" de manera idéntica a "la película fue aburrida y no divertida" – claramente problemático para una clasificación precisa de sentimientos.
A medida que los recursos computacionales se expandieron y las arquitecturas de redes neuronales maduraron, surgieron enfoques más sofisticados. Las Redes Neuronales Convolucionales (CNN) y las Redes Neuronales Recurrentes (RNN) comenzaron a aprovechar representaciones de palabras distribuidas que capturaban similitudes semánticas a través de modelos de espacio vectorial. Este avance permitió a los modelos entender que las palabras relacionadas deberían tener representaciones vectoriales similares, mejorando dramáticamente la precisión de clasificación en varios dominios incluyendo chatbots de IA y sistemas de respuesta automatizada.
La Revolución del Transformador en el PLN
La introducción en 2018 de las arquitecturas transformadoras marcó un momento crucial para el procesamiento del lenguaje natural. Estos modelos emplearon mecanismos de auto-atención para procesar secuencias completas simultáneamente mientras capturaban relaciones contextuales entre todas las palabras en un documento.
Modelos como BERT, ELMo y GPT aprovecharon arquitecturas transformadoras para generar incrustaciones de palabras contextuales – representaciones que varían según las palabras circundantes en lugar de mantener representaciones estáticas. Esta comprensión contextual permitió un rendimiento sin precedentes en tareas que requieren una comprensión del lenguaje matizada, desde el análisis de documentos legales hasta la categorización de textos médicos. Las demandas computacionales de estos modelos típicamente requieren aceleración por GPU, pero las mejoras en precisión justifican la inversión en infraestructura para sistemas de producción, particularmente en plataformas de automatización de IA donde la precisión es crítica.
Marcos de Aprendizaje Profundo para Clasificación de Texto
Las canalizaciones modernas de clasificación de texto típicamente aprovechan marcos de aprendizaje profundo establecidos que proporcionan herramientas integrales para el desarrollo, entrenamiento y despliegue de modelos. El ecosistema ha madurado significativamente, ofreciendo múltiples opciones robustas adaptadas a diferentes casos de uso y preferencias del equipo.
TensorFlow, desarrollado por Google, ofrece un ecosistema listo para producción con documentación extensa y soporte comunitario. Su gráfico de computación estática proporciona oportunidades de optimización que benefician escenarios de despliegue a gran escala. PyTorch, favorecido por las comunidades de investigación, presenta gráficos de computación dinámicos que permiten arquitecturas de modelo más flexibles y flujos de trabajo de depuración más fáciles. Ambos marcos se integran perfectamente con bibliotecas especializadas de PLN como spaCy, que proporciona tokenización, etiquetado de partes del discurso y reconocimiento de entidades nombradas de calidad industrial – pasos de preprocesamiento esenciales para una clasificación de texto efectiva en APIs y SDKs de IA.
Aprendizaje por Transferencia con Modelos Pre-entrenados
El aprendizaje por transferencia ha reducido dramáticamente los requisitos de datos y computación para construir clasificadores de texto de alto rendimiento. En lugar de entrenar modelos desde cero, los practicantes pueden afinar modelos pre-entrenados en corpus de texto masivos, adaptando la comprensión general del lenguaje a tareas de clasificación específicas.
Este enfoque aprovecha el conocimiento lingüístico codificado en modelos como BERT, que han aprendido estructuras gramaticales, relaciones semánticas e incluso conocimiento factual del entrenamiento en Wikipedia, libros y contenido web. El afinado requiere conjuntos de datos etiquetados significativamente más pequeños – a veces solo cientos o miles de ejemplos en lugar de millones – haciendo accesible la clasificación de texto sofisticada a organizaciones sin recursos de datos masivos. Esta metodología ha demostrado ser particularmente valiosa para herramientas de escritura de IA que necesitan categorizar contenido por tono, estilo o tema.
Implementación Práctica con ULMFiT
El enfoque de Ajuste Fino del Modelo de Lenguaje Universal (ULMFiT) proporciona una metodología estructurada para adaptar modelos de lenguaje pre-entrenados a tareas específicas de clasificación de texto. Este proceso de tres fases se ha convertido en un flujo de trabajo estándar para muchos practicantes de PLN.
Primero, comienza con un modelo de lenguaje pre-entrenado en un corpus general grande como Wikipedia. Este modelo ya ha aprendido patrones generales de lenguaje y relaciones semánticas. Segundo, afina este modelo de lenguaje en texto específico del dominio – incluso texto no etiquetado de tu dominio objetivo mejora el rendimiento. Finalmente, añade una capa de clasificación y afina todo el modelo en tu conjunto de datos de clasificación etiquetado. Este enfoque de especialización gradual típicamente supera el entrenamiento de clasificadores directamente en datos etiquetados limitados.
Para incrustaciones de palabras personalizadas, el proceso implica usar Gensim para implementar un generador de oraciones que alimenta texto a algoritmos Word2Vec, entrenando incrustaciones específicas del dominio que luego pueden integrarse con canalizaciones de spaCy para tareas de clasificación posteriores. Este enfoque es especialmente valioso para herramientas de IA conversacional que necesitan entender terminología específica del dominio y patrones de frases.
Ventajas y Desventajas
Ventajas
- La comprensión contextual captura el significado matizado del lenguaje
- El aprendizaje por transferencia reduce significativamente los requisitos de datos
- Los modelos pre-entrenados proporcionan un rendimiento base sólido
- Los ecosistemas de marcos ofrecen herramientas y soporte extensos
- Las arquitecturas escalables manejan grandes volúmenes de documentos
- Mejora continua a través del afinado de modelos
- Soporte multilingüe mediante incrustaciones cruzadas lingüísticas
Desventajas
- La intensidad computacional requiere recursos de GPU
- Desafíos de interpretabilidad del modelo para usuarios empresariales
- La adaptación del dominio aún requiere experiencia técnica
- Limitaciones de vocabulario para terminología altamente especializada
- Complejidad de despliegue en entornos de producción
Aplicaciones y Herramientas del Mundo Real
Análisis de Texto Empresarial con Gong.io
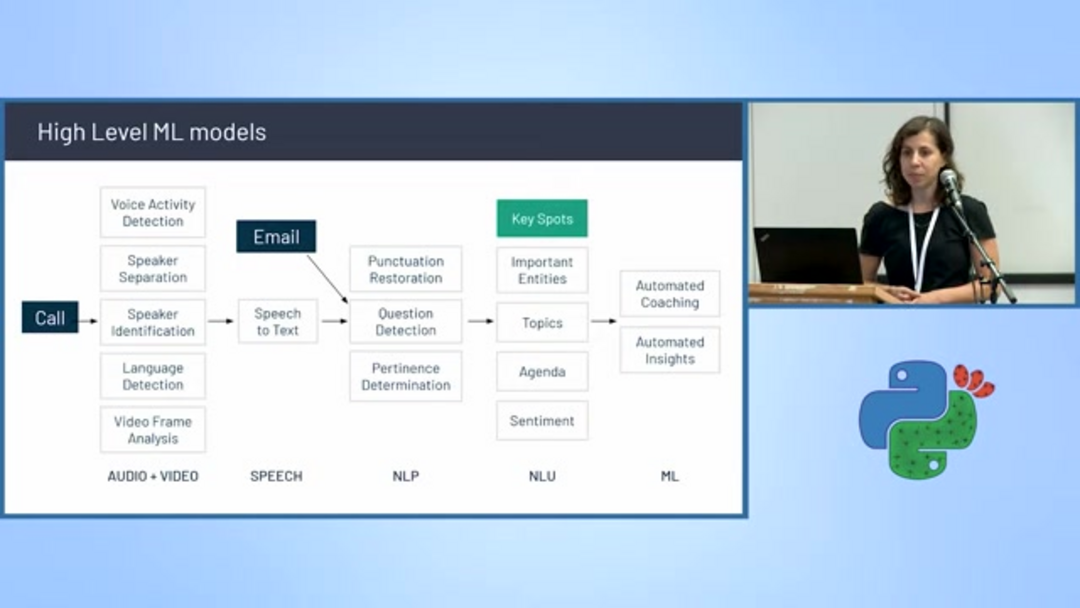
Plataformas comerciales como Gong.io demuestran cómo la clasificación de texto avanzada transforma las operaciones empresariales, particularmente en dominios de ventas y éxito del cliente. La plataforma graba, transcribe y analiza conversaciones de ventas usando una canalización sofisticada de modelos de aprendizaje automático.
La arquitectura de Gong incorpora múltiples clasificadores especializados incluyendo detección de actividad de voz, separación e identificación de hablantes, detección de idioma y conversión de voz a texto. Más allá de la transcripción básica, el sistema realiza análisis avanzados incluyendo restauración de puntuación, detección de preguntas, modelado de temas, determinación de pertinencia, seguimiento de agenda, análisis de sentimientos y extracción de entidades. Este enfoque integral permite a agentes y asistentes de IA proporcionar insights accionables a equipos de ventas, destacando menciones competitivas, discusiones de propuestas de valor y patrones de manejo de objeciones.
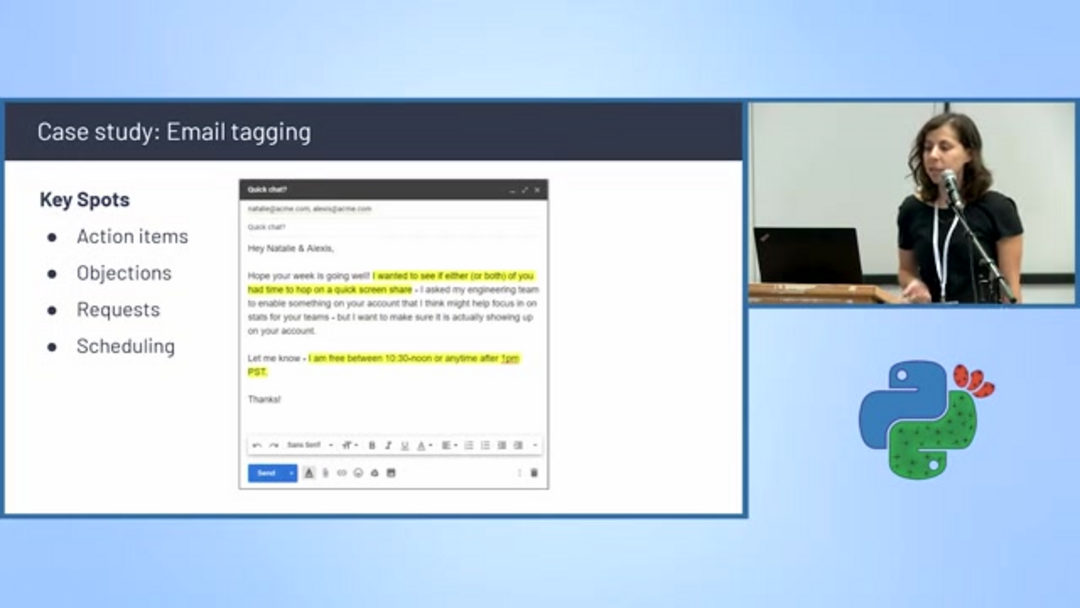
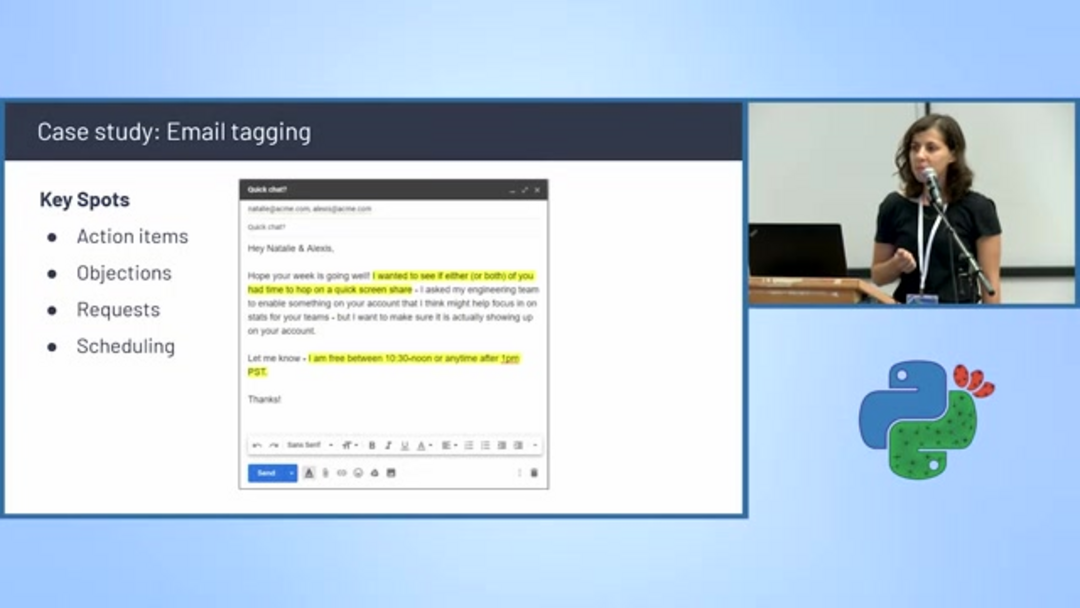
Etiquetado y Programación Automatizada de Correos Electrónicos
La clasificación de texto impulsa sistemas inteligentes de gestión de correo electrónico que categorizan automáticamente mensajes y extraen información accionable. Los algoritmos de detección de programación identifican correos electrónicos que contienen propuestas de reunión, discusiones de disponibilidad y coordinación de calendario, etiquetándolos automáticamente para manejo prioritario.
Estos sistemas analizan elementos clave de conversación incluyendo elementos de acción, objeciones, solicitudes específicas y menciones de programación. Al filtrar y categorizar correos electrónicos basándose en el contenido, las empresas pueden optimizar la gestión del flujo de trabajo y asegurar un seguimiento oportuno de comunicaciones críticas. Esta capacidad es particularmente valiosa para asistentes de correo electrónico de IA que ayudan a gestionar bandejas de entrada desbordadas y priorizar respuestas.
Direcciones Futuras en Clasificación de Texto
El campo continúa evolucionando rápidamente, con varias direcciones de investigación prometedoras abordando limitaciones actuales y expandiendo posibilidades de aplicación. La IA Explicable (XAI) se centra en hacer las decisiones del modelo interpretables para usuarios humanos, construyendo confianza y facilitando el análisis de errores. El modelado de lenguaje de bajos recursos apunta a extender capacidades de clasificación sofisticadas a idiomas con recursos de texto digital limitados.
Los enfoques multimodales integran texto con otros tipos de datos como imágenes y audio, creando contextos de comprensión más ricos – particularmente valiosos para el análisis de redes sociales donde el texto y el contenido visual interactúan. Las estrategias de aprendizaje activo optimizan los esfuerzos de anotación identificando las muestras más informativas para revisión humana, mientras que las técnicas de aprendizaje de pocos ejemplos permiten una adaptación efectiva del modelo con ejemplos de entrenamiento mínimos, abordando uno de los puntos más significativos de dolor en el despliegue del aprendizaje automático.
Conclusión
La clasificación de texto ha evolucionado desde métodos estadísticos simples hasta enfoques sofisticados de aprendizaje profundo que entienden el matiz contextual y las relaciones semánticas. La combinación de arquitecturas transformadoras, aprendizaje por transferencia y marcos integrales ha hecho accesible la clasificación de alta precisión en diversos dominios y aplicaciones. A medida que la investigación continúa avanzando en explicabilidad, eficiencia y capacidades multimodales, la clasificación de texto se volverá cada vez más integral para sistemas inteligentes que procesan, organizan y derivan insights de los volúmenes en constante crecimiento de texto digital. Dominar estas técnicas proporciona una ventaja competitiva significativa en el desarrollo de soluciones impulsadas por IA que entienden y categorizan el lenguaje humano con una comprensión similar a la humana.
Preguntas frecuentes
¿Por qué importa el orden de las palabras en la clasificación de texto?
El orden de las palabras lleva un significado semántico crucial: cambiar la secuencia puede alterar completamente el significado de una oración. Los modelos que ignoran el orden de las palabras no pueden distinguir entre 'la película fue divertida y no aburrida' versus 'la película fue aburrida y no divertida', lo que lleva a resultados de clasificación inexactos, particularmente en el análisis de sentimientos.
¿Cuáles son los pasos principales para entrenar incrustaciones de palabras personalizadas?
Entrenar incrustaciones personalizadas implica tres pasos clave: implementar un generador de oraciones usando Gensim para alimentar texto al modelo, ejecutar Word2Vec o algoritmos similares para entrenar incrustaciones en su corpus de dominio, luego integrar el modelo entrenado con spaCy u otras canalizaciones de PLN para tareas de clasificación posteriores que requieren comprensión del lenguaje específico del dominio.
¿Cómo beneficia el aprendizaje por transferencia a la clasificación de texto?
El aprendizaje por transferencia permite ajustar finamente modelos preentrenados en tareas específicas, reduciendo los requisitos de datos y mejorando la precisión al aprovechar el conocimiento de grandes conjuntos de datos, haciéndolo eficiente para la adaptación de dominio.
¿Cuáles son las ventajas clave de los modelos transformadores en PLN?
Los modelos transformadores utilizan autoatención para procesar secuencias en paralelo, capturando relaciones contextuales entre palabras, lo que lleva a un mejor rendimiento en tareas como la clasificación de texto y el análisis de sentimientos.
¿Cómo se puede aplicar la clasificación de texto en entornos empresariales?
La clasificación de texto se utiliza en la automatización del servicio al cliente, moderación de contenido, categorización de correos electrónicos y análisis de ventas, ayudando a las empresas a automatizar procesos y obtener información de los datos de texto.
Artículos relevantes sobre IA y tendencias tecnológicas
Mantente al día con las últimas ideas, herramientas e innovaciones que dan forma al futuro de la IA y la tecnología.
Grok AI: Generación Ilimitada de Videos Gratuita a partir de Texto e Imágenes | Guía 2024
Grok AI ofrece generación ilimitada de videos gratuita a partir de texto e imágenes, haciendo accesible la creación de videos profesionales para todos sin necesidad de habilidades de edición.
Configuración de Grok 4 Fast en Janitor AI: Guía Completa de Juego de Roles Sin Filtros
Guía paso a paso para configurar Grok 4 Fast en Janitor AI para juego de roles sin restricciones, incluyendo configuración de API, ajustes de privacidad y consejos de optimización
Las 3 mejores extensiones gratuitas de IA para programar en VS Code 2025 - Aumenta la productividad
Descubre las mejores extensiones gratuitas de agentes de IA para programar en Visual Studio Code en 2025, incluyendo Gemini Code Assist, Tabnine y Cline, para mejorar tu