Annotation
- Introduction
- Comprendre le défi de la détection des deepfakes
- Stratégie de jeu de données pour un entraînement de modèle robuste
- Mise en œuvre de l'architecture Vision Transformer
- Évaluation des performances et analyse des métriques
- Architecture de déploiement full-stack
- Flux de travail utilisateur de bout en bout
- Applications et cas d'usage dans le monde réel
- Fondation technique : la révolution des transformateurs
- Avantages et inconvénients
- Conclusion
- Questions fréquemment posées
Projet de Détection d'Images Deepfake : Guide d'Implémentation de Vision Transformer
Un guide complet sur la construction d'un système de détection d'images deepfake utilisant Vision Transformers, couvrant la préparation des données, l'entraînement du modèle et l'évaluation

Introduction
Alors que l'intelligence artificielle continue de progresser, la capacité à distinguer le contenu visuel authentique du contenu manipulé est devenue de plus en plus critique. Ce guide complet explore un projet complet d'apprentissage profond qui exploite l'architecture de transformateur de pointe pour détecter les images deepfake avec une précision remarquable. De la préparation des données au déploiement web, nous passerons en revue chaque composant de la construction d'un système robuste de détection de deepfake qui combine des techniques d'IA modernes avec des stratégies de mise en œuvre pratiques.
Comprendre le défi de la détection des deepfakes
La technologie des deepfakes représente l'un des défis les plus importants en matière d'authenticité des médias numériques aujourd'hui. Ces manipulations générées par l'IA peuvent aller de subtiles altérations faciales à des fabrications complètes qui sont presque impossibles à distinguer des images réelles pour les observateurs humains. Le projet que nous examinons relève ce défi en mettant en œuvre un système de détection sophistiqué qui analyse les artefacts visuels et les incohérences qui trahissent souvent le contenu généré par l'IA. Cette approche est particulièrement pertinente pour les professionnels travaillant avec générateurs d'images IA qui doivent vérifier l'authenticité du contenu.
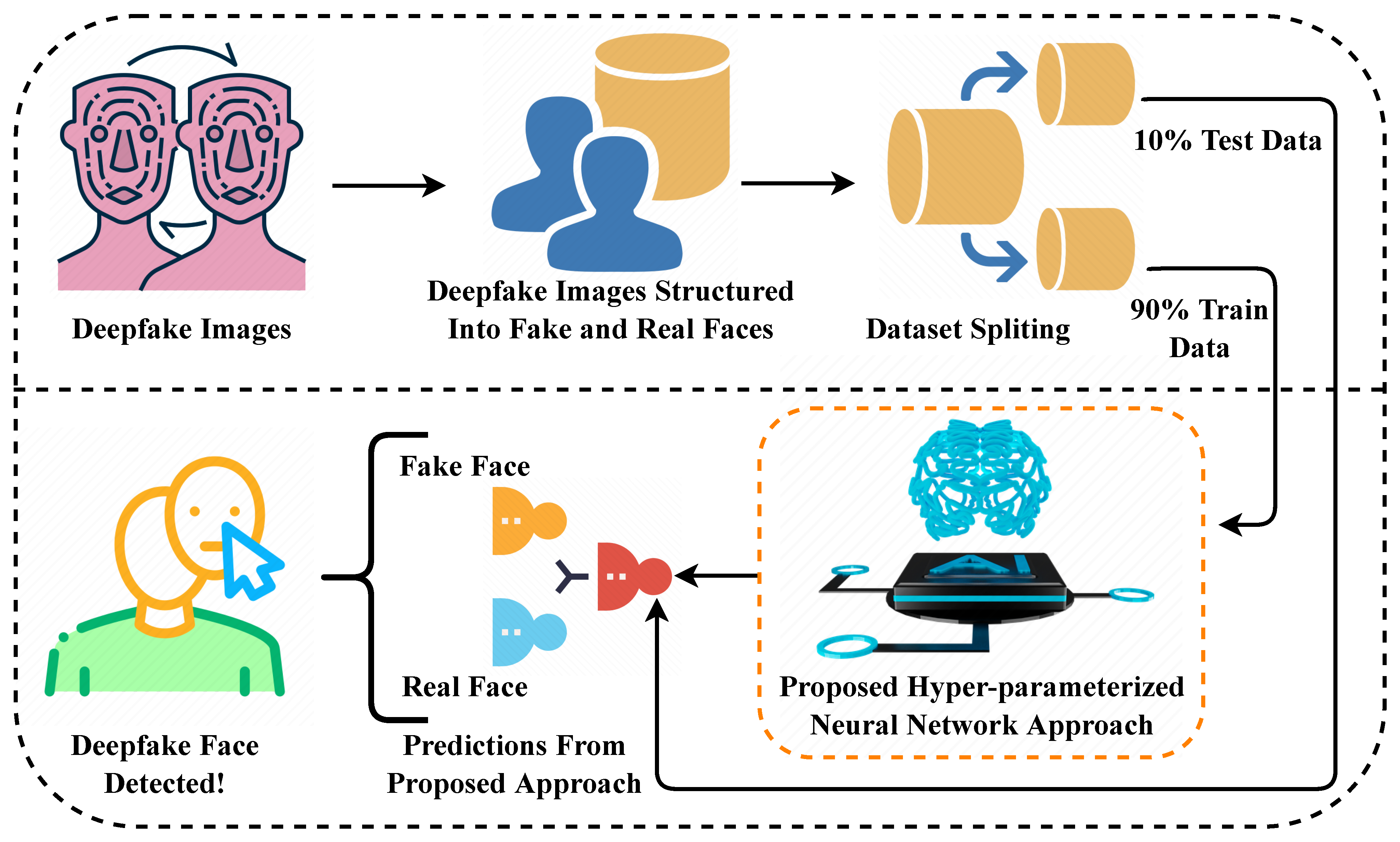
Stratégie de jeu de données pour un entraînement de modèle robuste
La base de tout modèle d'apprentissage profond efficace réside dans ses données d'entraînement. Pour ce projet de détection de deepfakes, le jeu de données a été soigneusement sélectionné pour inclure des exemples variés d'images authentiques et manipulées dans divers scénarios et niveaux de qualité. Cette diversité garantit que le modèle apprend à reconnaître les deepfakes quelle que soit la technique de génération spécifique utilisée ou le sujet de l'image.
Le jeu de données suit une division structurée en trois parties essentielle au bon développement du modèle :
- Données d'entraînement (70 %) : La plus grande partie expose le modèle à des milliers d'exemples variés, lui apprenant à reconnaître les motifs subtils et les artefacts qui distinguent les images réelles des deepfakes dans différentes conditions d'éclairage, résolutions et techniques de manipulation.
- Données de validation (15 %) : Utilisées pendant l'entraînement pour surveiller les performances et éviter le surapprentissage, ce sous-ensemble aide à affiner les hyperparamètres et assure que le modèle généralise bien plutôt que de mémoriser les exemples d'entraînement.
- Données de test (15 %) : Complètement retenues jusqu'à l'évaluation finale, ces données fournissent une évaluation impartiale des performances du modèle sur des images jamais vues auparavant dans des scénarios réels.
Mise en œuvre de l'architecture Vision Transformer
Au cœur de ce système de détection se trouve un modèle Vision Transformer (ViT), qui représente un écart significatif par rapport aux réseaux de neurones convolutionnels traditionnels pour l'analyse d'images. L'architecture de transformateur, initialement développée pour le traitement du langage naturel, a démontré des performances remarquables dans les tâches de vision par ordinateur en capturant les dépendances à long terme et le contexte global au sein des images.
Le processus de mise en œuvre dans l'environnement Jupyter Notebook suit une approche systématique :
- Configuration de l'environnement : Importation des bibliothèques essentielles incluant TensorFlow, Keras et des implémentations spécialisées de transformateurs, ainsi que des outils de manipulation et de visualisation de données.
- Construction du pipeline de données : Création de chargeurs de données efficaces qui gèrent le redimensionnement, la normalisation et les techniques d'augmentation comme la rotation, le retournement et les ajustements de luminosité pour améliorer la robustesse du modèle.
- Configuration du modèle : Définition de l'architecture Vision Transformer avec des tailles de patch, des dimensions d'incorporation et des têtes d'attention adaptées à la tâche de détection de deepfakes.
- Application de l'apprentissage par transfert : Exploitation de poids pré-entraînés à partir de jeux de données d'images à grande échelle et affinage du modèle spécifiquement pour la détection de deepfakes, réduisant significativement le temps d'entraînement et améliorant les performances.
- Optimisation de l'entraînement : Mise en œuvre de planification du taux d'apprentissage, d'arrêt précoce et de découpage du gradient pour assurer une convergence stable et efficace du modèle.
Évaluation des performances et analyse des métriques
L'évaluation d'un modèle de détection de deepfakes nécessite des métriques complètes qui vont au-delà de la simple précision. Le projet met en œuvre plusieurs approches d'évaluation pour évaluer minutieusement les performances du modèle et identifier les faiblesses potentielles.
L'analyse de la matrice de confusion révèle des informations critiques sur le comportement du modèle :
| Réel Prédit | Faux Prédit | |
|---|---|---|
| Vrai Réel | 37 831 | 249 |
| Vrai Faux | 326 | 37 755 |
Cette matrice démontre d'excellentes performances avec un minimum de faux positifs et de faux négatifs. Le modèle atteint environ 99,2 % de précision, avec des métriques de précision et de rappel dépassant toutes les deux 99 % pour les deux classes. Ces résultats indiquent un modèle bien équilibré qui performe de manière cohérente, qu'il détecte des images réelles ou fausses.
Architecture de déploiement full-stack
Pour rendre les capacités de détection de deepfakes accessibles aux utilisateurs finaux, le projet met en œuvre une application web complète avec des composants frontend et backend séparés. Cette architecture suit les pratiques modernes de développement web tout en assurant un service de modèle efficace et une expérience utilisateur réactive.
La pile de déploiement inclut :
- API Backend (Flask) : Un framework web Python léger qui héberge le modèle entraîné et fournit des points de terminaison RESTful pour le traitement d'images et la prédiction. Le backend gère le prétraitement des images, l'inférence du modèle et le formatage des résultats, le rendant compatible avec diverses API et SDK IA.
- Interface Frontend : Une application web réactive construite avec HTML, CSS et JavaScript qui fournit une interface intuitive de glisser-déposer pour le téléchargement d'images, des indicateurs de traitement en temps réel et une présentation claire des résultats.
- Optimisation du service de modèle : Mise en œuvre de mécanismes de mise en cache, de file d'attente de requêtes et d'accélération GPU pour assurer des temps de réponse rapides même sous charge importante, similaires aux capacités trouvées dans les plateformes professionnelles d'hébergement de modèles IA.
Flux de travail utilisateur de bout en bout
Le système complet fonctionne grâce à un flux de travail rationalisé qui équilibre la commodité de l'utilisateur et la robustesse technique :
- Soumission d'image : Les utilisateurs téléchargent des images via l'interface web, avec prise en charge des formats courants (JPEG, PNG) et validation automatique de la taille et des dimensions du fichier.
- Traitement backend : L'API Flask reçoit l'image, applique le prétraitement nécessaire (redimensionnement, normalisation) et exécute le pipeline d'inférence du modèle.
- Analyse en temps réel : Le Vision Transformer traite l'image, analysant les relations spatiales et les motifs de texture pour identifier les artefacts de manipulation caractéristiques des techniques de génération de deepfakes.
- Calcul du score de confiance : Le modèle génère à la fois une classification (réel/faux) et un score de confiance qui indique la certitude de la prédiction, aidant les utilisateurs à comprendre la fiabilité de chaque résultat.
- Livraison du résultat : Le frontend affiche le résultat de l'analyse avec des indicateurs visuels et du texte explicatif, rendant les résultats techniques accessibles aux utilisateurs non experts.
Applications et cas d'usage dans le monde réel
Les applications pratiques d'une détection robuste des deepfakes s'étendent à travers de multiples domaines où l'authenticité visuelle est primordiale. Les organisations de presse peuvent intégrer de tels systèmes pour vérifier le contenu soumis par les utilisateurs avant publication, tandis que les plateformes de médias sociaux pourraient déployer une technologie similaire pour signaler automatiquement les images potentiellement manipulées. Les professionnels juridiques et médico-légaux bénéficient d'outils fournissant une analyse préliminaire de l'authenticité des preuves, bien qu'une revue experte humaine reste essentielle pour les cas critiques. La technologie complète également les outils existants d'éditeur photo en ajoutant des capacités de vérification.
Dans les environnements d'entreprise, la détection de deepfakes aide à protéger contre les attaques d'ingénierie sociale sophistiquées qui utilisent des images manipulées pour la tromperie d'identité. Les institutions éducatives peuvent utiliser ces systèmes pour enseigner la littératie numérique et les compétences d'évaluation critique des médias. L'intégration croissante de technologies similaires dans les plateformes d'automatisation IA démontre l'importance croissante de la vérification du contenu dans les workflows automatisés.
Fondation technique : la révolution des transformateurs
Ce projet s'appuie sur le travail révolutionnaire présenté dans le document de recherche « Attention Is All You Need », qui a introduit l'architecture de transformateur qui a depuis révolutionné à la fois le traitement du langage naturel et la vision par ordinateur. Le mécanisme d'auto-attention au cœur des transformateurs permet au modèle de peser dynamiquement l'importance de différentes régions de l'image, le rendant particulièrement efficace pour détecter les artefacts subtils et globalement distribués qui caractérisent les manipulations deepfake.
Contrairement aux réseaux convolutionnels traditionnels qui traitent les images via des filtres locaux, les transformateurs peuvent capturer des dépendances à long terme sur l'ensemble de l'image simultanément. Cette perspective globale est cruciale pour identifier les incohérences dans l'éclairage, les motifs de texture et les proportions anatomiques qui trahissent souvent le contenu généré par l'IA. L'évolutivité de l'architecture lui permet également de bénéficier de jeux de données plus importants et de plus de ressources informatiques, suivant les tendances observées dans les répertoires d'outils IA complets qui suivent les capacités des modèles.
Avantages et inconvénients
Avantages
- Précision de détection exceptionnelle dépassant 99 % sur les données de test
- Mise en œuvre complète de bout en bout des données au déploiement
- Architecture open-source permettant la personnalisation et l'extension
- L'architecture Vision Transformer capture le contexte global de l'image
- Interface web conviviale accessible aux utilisateurs non techniques
- Performance robuste sur divers types et qualités d'images
- Temps d'inférence rapides adaptés aux applications en temps réel
Inconvénients
- Exigences computationnelles substantielles pour l'entraînement
- Nécessite une expertise significative en apprentissage automatique pour modifier
- Performance dépendante de la qualité et de la diversité des données d'entraînement
- Faux positifs potentiels avec des images très compressées
- Efficacité limitée contre les techniques de manipulation jamais vues auparavant
Conclusion
Ce projet de détection d'images deepfake démontre la puissante combinaison de l'architecture moderne de transformateur avec une mise en œuvre full-stack pratique. En exploitant les Vision Transformers, le système atteint une précision exceptionnelle pour distinguer les images authentiques des manipulations générées par l'IA tout en maintenant l'accessibilité via une interface web conviviale. Le flux de travail complet—de la préparation des données et l'entraînement du modèle au déploiement et à l'évaluation—fournit un cadre robuste qui peut être adapté à divers scénarios d'authentification d'images. Alors que la technologie des deepfakes continue d'évoluer, de tels systèmes de détection joueront un rôle de plus en plus vital dans le maintien de la confiance numérique et la lutte contre la désinformation visuelle à travers les plateformes et les industries.
Questions fréquemment posées
Qu'est-ce que la détection d'images deepfake ?
La détection d'images deepfake utilise l'intelligence artificielle pour identifier les images manipulées par des techniques d'apprentissage profond, analysant les artefacts visuels et les incohérences qui distinguent le contenu généré par IA des photographies authentiques.
Quelle est la précision de ce détecteur de deepfake ?
Le détecteur basé sur Vision Transformer atteint une précision de plus de 99 % sur les ensembles de données de test, avec des performances équilibrées entre les classes d'images réelles et fausses, bien que les performances puissent varier selon la qualité de l'image et les nouvelles techniques de manipulation.
Quelles technologies alimentent ce système de détection ?
Le système combine l'architecture Vision Transformer pour l'analyse d'images, TensorFlow/Keras pour l'apprentissage profond, Flask pour l'API backend et les technologies web modernes pour l'interface frontale, créant une application complète full-stack.
Les étudiants peuvent-ils utiliser ce projet pour apprendre ?
Oui, le projet est excellent à des fins éducatives, y compris les travaux de cours, les projets de recherche ou les projets de fin d'études. L'approche open source permet aux étudiants d'étudier et de modifier l'implémentation tout en apprenant les techniques modernes d'IA.
Quelles sont les exigences système ?
L'entraînement nécessite des ressources GPU substantielles, mais l'application web déployée peut fonctionner sur des serveurs standard. Pour le développement, Python 3.8+, TensorFlow 2.x et des bibliothèques courantes de science des données sont nécessaires, similaires à de nombreux environnements de développement IA.