Annotation
- Введение
- Понимание пользовательской классификации текста
- Почему стоит выбрать службу Azure AI Language для классификации текста
- Настройка службы Azure AI Language
- Обучение вашей модели пользовательской классификации текста
- Структура ценообразования службы Azure AI Language
- Основные функции и возможности
- Практические применения и случаи использования
- Общие проблемы внедрения
- Плюсы и минусы
- Заключение
- Часто задаваемые вопросы
Служба языка Azure AI: руководство по настройке и обучению пользовательской классификации текста
Узнайте, как реализовать пользовательскую классификацию текста с помощью службы языка Azure AI, от настройки и обучения до развертывания, для точного текста

Введение
В современной бизнес-среде, богатой данными, эффективная категоризация и понимание текстовых данных стали необходимыми для принятия обоснованных решений. Служба Azure AI Language от Microsoft предоставляет мощные возможности обработки естественного языка, включая пользовательскую классификацию текста, которая позволяет организациям создавать адаптированные системы категоризации. Это подробное руководство проведет вас через полный процесс настройки, обучения и развертывания моделей пользовательской классификации текста с использованием облачной инфраструктуры Azure.
Понимание пользовательской классификации текста
Пользовательская классификация текста представляет собой специализированный подход машинного обучения, который автоматически назначает предопределенные категории текстовым документам на основе ваших конкретных бизнес-требований. В отличие от общей текстовой аналитики, которая может фокусироваться на анализе тональности или извлечении ключевых фраз, пользовательская классификация текста позволяет вам определять доменно-специфические категории, соответствующие потребностям вашей организации. Например, вы можете классифицировать запросы в службу поддержки на категории, такие как «Техническая проблема», «Запрос по биллингу» или «Запрос функции» – обеспечивая немедленный контекст для маршрутизации и решения.
Служба Azure AI Language предоставляет корпоративные возможности для создания сложных решений классификации текста, которые масштабируются в соответствии с объемом данных и требованиями сложности.
Почему стоит выбрать службу Azure AI Language для классификации текста
Служба Azure AI Language предлагает несколько убедительных преимуществ для организаций, внедряющих пользовательскую классификацию текста. Облачная архитектура платформы обеспечивает бесшовную масштабируемость для обработки больших объемов текста без ухудшения производительности. Передовые алгоритмы машинного обучения и методы обработки естественного языка обеспечивают высокую точность, в то время как опции настройки позволяют обучать модели специально на вашем домене данных. Служба плавно интегрируется с другими AI API и SDK и платформами автоматизации ИИ, создавая комплексную экосистему ИИ. Модель ценообразования с оплатой по мере использования обеспечивает гибкость оптимизации затрат, делая ее доступной как для небольших экспериментов, так и для крупномасштабных производственных развертываний.
Настройка службы Azure AI Language
Прежде чем начать процесс конфигурации, убедитесь, что у вас есть активная подписка Azure. Microsoft предлагает пробные учетные записи для новых пользователей, предоставляя кредит для изучения услуг без немедленных финансовых обязательств. Процесс настройки включает несколько ключевых шагов, которые устанавливают основу для ваших проектов классификации текста.
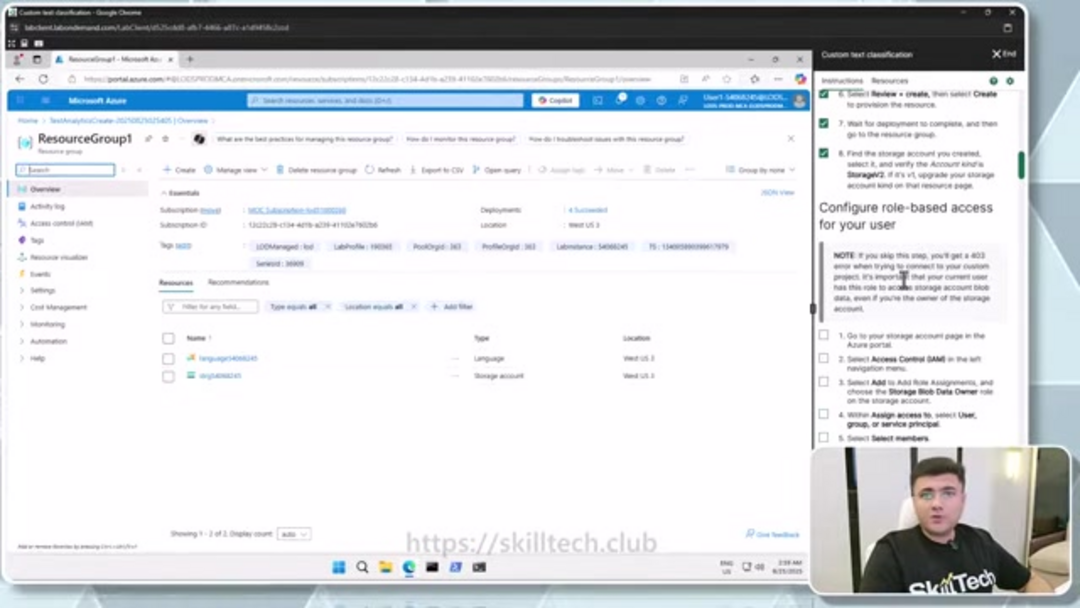
Первоначальный шаг включает создание ресурса Azure AI Language через портал Azure. Этот ресурс служит центральной точкой управления для ваших моделей пользовательской классификации текста и предоставляет доступ к Language Studio – веб-интерфейсу для разработки моделей. После входа на portal.azure.com с вашими учетными данными перейдите к «Создать ресурс» и найдите «Language Service». Выберите соответствующую службу из результатов и продолжите создание.
Во время конфигурации укажите основные детали, включая вашу подписку Azure, группу ресурсов для организационного управления и выбор географического региона – выбор местоположений рядом с источниками данных может улучшить производительность. Назначьте уникальное имя для вашего ресурса Language Service и выберите тарифный уровень, соответствующий объему вашего проекта. Бесплатный уровень F0 хорошо подходит для экспериментов, в то время как производственные среды обычно требуют стандартных или премиальных уровней для более высоких лимитов транзакций и расширенных функций.
Служба Azure AI Language требует связанные учетные записи хранения для операционной функциональности. Во время создания ресурса вы настроите новую учетную запись хранения или свяжете существующую, убедившись, что выбран Standard LRS (локально избыточное хранилище) для надежности. После завершения развертывания настройте управление доступом на основе ролей, перейдя в раздел Управление доступом (IAM) вашей учетной записи хранения. Добавьте назначение роли, выбрав «Владелец данных больших двоичных объектов хранилища» и назначьте его вашей учетной записи пользователя, обеспечивая надлежащие разрешения для операций обучения моделей.
Обучение вашей модели пользовательской классификации текста
После установки инфраструктуры процесс обучения модели начинается с подготовки данных и маркировки – критических шагов, которые напрямую влияют на точность и производительность классификации.
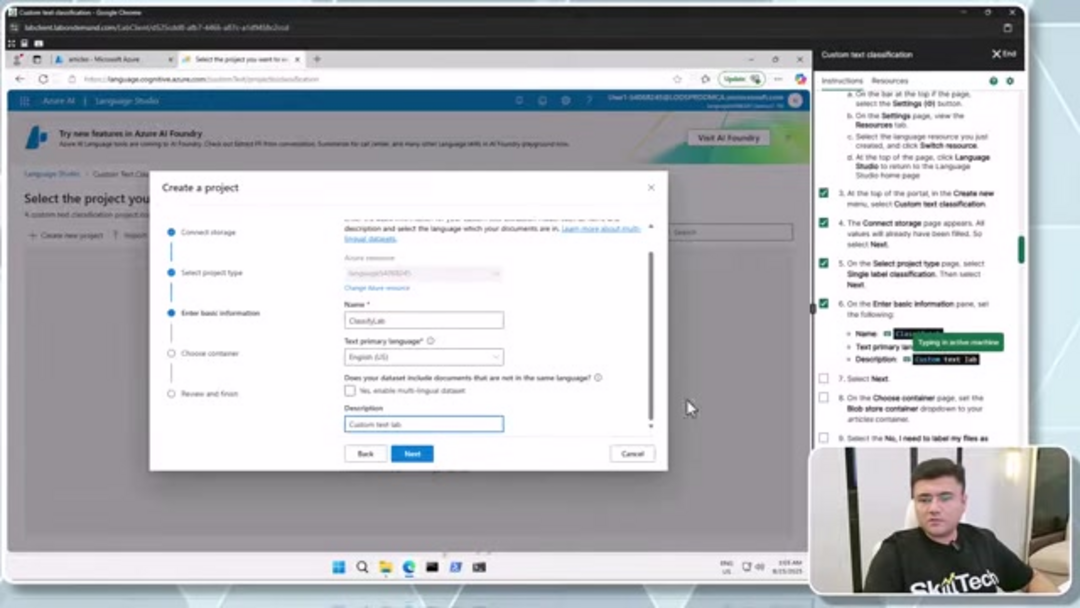
Начните с создания выделенного контейнера в вашей учетной записи хранения специально для обучающих документов. Перейдите в раздел Контейнеры и создайте новый контейнер с именем «articles» с уровнем доступа, установленным на «Container», чтобы обеспечить правильные операции с большими двоичными объектами. Загрузите ваши примеры документов – они должны представлять различные текстовые категории, которые вы хотите классифицировать. Для оптимальных результатов убедитесь, что ваш обучающий набор данных включает достаточное количество примеров из каждой категории, с документами, которые реалистично представляют вариации текста, с которыми ваша модель столкнется в производстве. Эта фаза подготовки важна для построения эффективных агентов и помощников ИИ, которые могут обрабатывать и категоризировать информацию точно.
Маркировка данных обеспечивает структурированную основу, которая позволяет вашей модели изучать различия категорий. В Language Studio откройте раздел Маркировка данных, где вы увидите загруженные файлы из вашей учетной записи хранения. Создайте пользовательские классы, соответствующие вашим потребностям классификации – например, вы можете установить категории, такие как «Спорт», «Новости», «Развлечения» и «Объявления» для медиа-приложения. Систематически назначайте каждый документ в соответствующую категорию, обеспечивая последовательную маркировку по всему набору данных. Этот тщательный подход к подготовке данных значительно влияет на точность модели и способность к обобщению.
Инициируйте процесс обучения, обратившись к Заданиям обучения в Language Studio. Создайте новое задание обучения с подходящим именем для вашего проекта, например «ClassifyArticles». Настройте разделение данных между обучающими и тестовыми наборами – стандартное разделение 80/20 обычно обеспечивает хороший баланс между обучением модели и валидацией. Во время обучения Azure использует передовые методы машинного обучения для анализа шаблонов в ваших размеченных данных и построения возможностей классификации. После завершения обучения оцените производительность модели, используя предоставленные метрики, включая точность, полноту и измерения F1-меры, которые указывают, насколько хорошо ваша модель различает категории.
Структура ценообразования службы Azure AI Language
Понимание модели ценообразования Azure помогает в планировании бюджета и оптимизации затрат. Бесплатный уровень (F0) предоставляет ограниченное количество ежемесячных транзакций, подходящих для экспериментов и проектов подтверждения концепции. Стандартный уровень (S0) работает по ценообразованию с оплатой по мере использования на основе объема транзакций, идеально подходит для растущих приложений с переменными шаблонами использования. Премиум уровень предлагает ценообразование с зарезервированной емкостью для корпоративных развертываний с высоким объемом, требующих предсказуемых затрат и максимальной пропускной способности. Учтите ожидаемый объем обработки текста и требования к времени отклика при выборе подходящего уровня для вашей реализации.
Основные функции и возможности
Служба Azure AI Language предоставляет комплексную функциональность обработки естественного языка помимо пользовательской классификации текста. Анализ тональности определяет эмоциональный тон в тексте, в то время как извлечение ключевых фраз идентифицирует центральные концепции и темы. Определение языка автоматически распознает язык текста, а распознавание именованных сущностей идентифицирует людей, организации и местоположения, упомянутые в содержании. Служба также поддерживает пользовательское распознавание именованных сущностей для доменно-специфических сущностей и пользовательские вопросы и ответы для построения интеллектуальных баз знаний. Эти возможности могут быть объединены для создания сложных инструментов написания ИИ и чат-ботов ИИ, которые понимают и обрабатывают естественный язык эффективно.
Практические применения и случаи использования
Пользовательская классификация текста находит применение во многих отраслях и бизнес-функциях. Организации службы поддержки автоматизируют категоризацию заявок, маршрутизируя запросы к соответствующим командам на основе анализа содержания. Поставщики медицинских услуг классифицируют медицинские записи и отзывы пациентов для улучшения координации ухода и операционной эффективности. Финансовые учреждения анализируют документы, новости и отчеты для оценки рисков и идентификации возможностей. Электронные коммерческие платформы категоризируют отзывы о продуктах и обратную связь клиентов для улучшения обнаружения и удовлетворенности. Медиа-компании классифицируют контент для персонализированных рекомендаций и вовлечения аудитории. Эти применения демонстрируют, как классификация текста интегрируется с инструментами разговорного ИИ и помощниками по электронной почте ИИ для автоматизации обработки информации.
Общие проблемы внедрения
Несколько проблем могут возникнуть во время проектов пользовательской классификации текста. Дисбаланс данных происходит, когда некоторые категории имеют значительно больше обучающих примеров, чем другие, потенциально создавая смещенные модели – техники, такие как передискретизация меньшинственных классов, могут решить это. Переобучение происходит, когда модели становятся слишком сложными и плохо работают на новых данных – регуляризация и перекрестная проверка помогают поддерживать обобщение. Ограниченная доступность размеченных данных может ограничивать обучение модели – подходы активного обучения и техники трансферного обучения могут оптимизировать ограниченные наборы данных. Неоднозначные определения категорий сбивают с толку модели во время обучения – выделение достаточного времени на установление четких, различных категорий улучшает результаты. Проблемы качества данных, включая шум и несогласованность, влияют на производительность – тщательная очистка данных и предварительная обработка устанавливают прочную основу для точной классификации.
Плюсы и минусы
Преимущества
- Высокомасштабируемая облачная инфраструктура эффективно обрабатывает большие объемы текста
- Передовые алгоритмы машинного обучения обеспечивают точные результаты классификации
- Полные опции настройки для доменно-специфических определений категорий
- Бесшовная интеграция с комплексной экосистемой служб Azure
- Гибкое ценообразование с оплатой по мере использования оптимизирует операционные затраты
- Корпорационная безопасность и сертификаты соответствия
- Непрерывное улучшение модели через возможности переобучения
Недостатки
- Требуется активная подписка Azure и зависимость от облака
- Более крутая кривая обучения для новичков в службах Azure
- Затраты могут значительно возрасти при использовании с высоким объемом
- Ограниченная офлайн-функциональность из-за облачной природы
- Соображения управления данными для конфиденциальной информации
Заключение
Служба Azure AI Language предоставляет надежную, масштабируемую платформу для внедрения решений пользовательской классификации текста, которые преобразуют неструктурированный текст в действенную категоризированную информацию. Следуя комплексному процессу настройки, обучения и развертывания, описанному в этом руководстве, организации могут построить адаптированные системы классификации, которые удовлетворяют конкретным бизнес-потребностям. Возможности интеграции службы с другими службами ИИ Azure и гибкие модели ценообразования делают ее доступной для проектов различных масштабов и сложностей. Поскольку текстовые данные продолжают расти в объеме и важности, освоение пользовательской классификации текста становится все более ценным для извлечения инсайтов, автоматизации процессов и улучшения принятия решений в бизнес-функциях.
Часто задаваемые вопросы
Для чего используется служба языка Azure AI?
Служба языка Azure AI — это облачная платформа обработки естественного языка, которая предоставляет возможности анализа текста, включая анализ тональности, извлечение ключевых фраз, определение языка, распознавание именованных сущностей и пользовательскую классификацию текста для бизнес-приложений.
Сколько стоит служба языка Azure AI?
Служба языка Azure AI предлагает бесплатный уровень (F0) для экспериментов, стандартную (S0) оплату по мере использования для растущих приложений и уровень Premium с зарезервированной емкостью для корпоративных развертываний с предсказуемыми затратами на основе объема транзакций.
Каковы основные проблемы пользовательской классификации текста?
Ключевые проблемы включают дисбаланс данных между категориями, переобучение модели, ограниченные размеченные обучающие данные, неоднозначные определения категорий и проблемы качества данных, требующие тщательной предварительной обработки и настройки модели.
Насколько точна пользовательская классификация текста Azure?
Точность зависит от качества и количества обучающих данных, но передовые алгоритмы машинного обучения Azure обычно обеспечивают высокую точность и полноту при правильном обучении с достаточным количеством хорошо размеченных репрезентативных документов.
Сколько времени занимает обучение модели пользовательской классификации текста?
Время обучения варьируется в зависимости от размера и сложности данных, но обычно составляет от нескольких минут до нескольких часов для больших наборов данных с использованием масштабируемой инфраструктуры Azure.
Релевантные статьи об ИИ и технологических трендах
Будьте в курсе последних инсайтов, инструментов и инноваций, формирующих будущее ИИ и технологий.
Grok AI: Бесплатное неограниченное создание видео из текста и изображений | Руководство 2024
Grok AI предлагает бесплатное неограниченное создание видео из текста и изображений, делая профессиональное создание видео доступным для всех без навыков редактирования.
Настройка Grok 4 Fast в Janitor AI: Полное руководство по ролевой игре без фильтров
Пошаговое руководство по настройке Grok 4 Fast в Janitor AI для неограниченной ролевой игры, включая настройку API, параметры конфиденциальности и советы по оптимизации
Топ-3 бесплатных расширений для ИИ-программирования в VS Code 2025 - Повышение производительности
Откройте для себя лучшие бесплатные расширения для ИИ-программирования в Visual Studio Code в 2025 году, включая Gemini Code Assist, Tabnine и Cline, чтобы улучшить вашу