Annotation
- Введение
- Почему выбирают открытый исходный код для AI?
- Представляем Docling: Герой открытого исходного кода
- Сравнение Docling с закрытыми альтернативами
- Основные техники: Извлечение, Парсинг, Чанкинг, Встраивание и Извлечение
- Запуск примера с Docling
- Плюсы и минусы
- Заключение
- Часто задаваемые вопросы
Docling Парсинг Документов с Открытым Исходным Кодом: Полное Руководство по Реализации ИИ
Руководство по парсингу документов Docling с открытым исходным кодом для ИИ: реализуйте обработку PDF, разбиение на фрагменты, внедрение и конвейеры RAG локально.

Введение
В современной бизнес-среде, основанной на данных, AI-агенты стали незаменимыми инструментами для поддержки клиентов и анализа данных. Основой эффективных AI-систем является их способность получать доступ и понимать информацию, специфичную для компании, которая часто содержится в документах, PDF-файлах и веб-сайтах. Хотя существует множество коммерческих инструментов для парсинга документов, многие из них связаны с затратами на API и ограничениями закрытого исходного кода. Docling появляется как мощная альтернатива с открытым исходным кодом, которая предоставляет полный контроль над вашим конвейером обработки документов, сохраняя при этом конфиденциальность данных и гибкость настройки.
Почему выбирают открытый исходный код для AI?
При разработке AI-агентов доступ к проприетарным данным имеет решающее значение для достижения значимых результатов. Эти данные обычно включают внутренние документы, PDF-отчеты и корпоративные веб-сайты, содержащие специфические знания о вашей организации. Традиционные решения для парсинга часто требуют отправки конфиденциальных данных на сторонние платформы, создавая потенциальные уязвимости безопасности и постоянные лицензионные расходы. Альтернативы с открытым исходным кодом, такие как Docling, устраняют эти проблемы, позволяя осуществлять локальную обработку в вашей собственной инфраструктуре.
Преимущества парсинга документов с открытым исходным кодом выходят за рамки экономии затрат. Вы получаете полную прозрачность в том, как обрабатываются ваши данные, возможность настраивать логику парсинга для уникальных структур документов и свободу от привязки к поставщику. Этот подход особенно хорошо согласуется с требованиями предприятий к управлению данными и соответствию. Для организаций, исследующих решения по извлечению документов с помощью AI, открытый исходный код предоставляет как технические, так и стратегические преимущества.

Инструменты с открытым исходным кодом обеспечивают значительную ценность через несколько ключевых преимуществ: полный контроль над конвейерами обработки данных, неограниченные возможности настройки, прозрачные операции, повышающие безопасность, активная поддержка сообщества и существенное снижение затрат по сравнению с проприетарными альтернативами. Эти преимущества делают открытый исходный код особенно привлекательным для организаций, создающих комплексные платформы автоматизации AI, требующие надежных возможностей обработки документов.
Представляем Docling: Герой открытого исходного кода
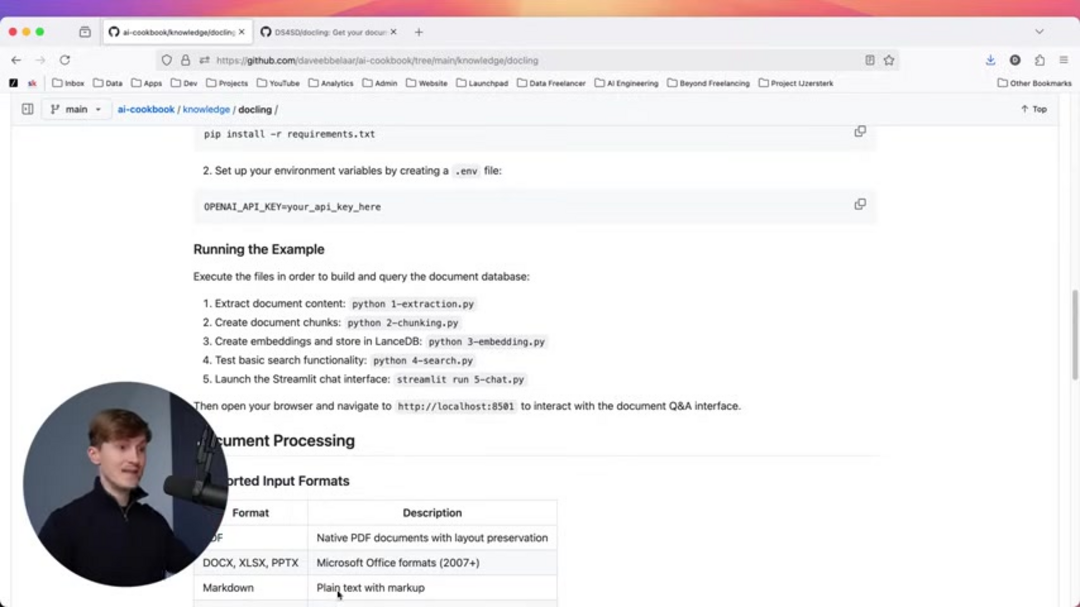
Docling представляет собой sophisticated библиотеку обработки документов с открытым исходным кодом, которая преобразует различные форматы документов в унифицированные структурированные данные. Построенная с продвинутыми возможностями AI, она превосходно справляется с анализом макета и распознаванием структуры таблиц, сохраняя при этом эффективность локальной обработки. Библиотека поддерживает широкий спектр форматов, включая PDF, DOCX-файлы, XLSX-таблицы, PPTX-презентации, Markdown-документы, HTML-страницы и различные форматы изображений.

Что отличает Docling, так это его гибкие варианты вывода, позволяющие разработчикам экспортировать обработанный контент в форматы HTML, Markdown, JSON или обычный текст. Эта универсальность делает его идеальным для интеграции в существующие рабочие процессы и приложения. Система эффективно работает на стандартном оборудовании и обладает расширяемой архитектурой, которая позволяет разработчикам включать пользовательские модели или изменять конвейеры обработки для конкретных требований. Это делает Docling особенно ценным для корпоративных систем поиска документов, реализаций извлечения отрывков и проектов извлечения знаний.
Для разработчиков, работающих с AI API и SDK, Docling предоставляет надежную основу для построения конвейеров Retrieval Augmented Generation (RAG). Его продвинутые возможности чанкинга и оптимизации обработки гарантируют, что GenAI-приложения получают хорошо структурированные входные данные знаний, значительно улучшая качество ответов и точность в системах вопросов и ответов на основе документов.
Сравнение Docling с закрытыми альтернативами
При оценке решений для парсинга документов важно понимать, как Docling сравнивается с коммерческими альтернативами, такими как Microsoft Azure AI Document Intelligence, Amazon Textract и различные проприетарные сервисы. Фундаментальное различие заключается в природе Docling с открытым исходным кодом по сравнению с закрытым исходным кодом и подходом, зависящим от API, коммерческих предложений.
Коммерческие сервисы парсинга документов обычно работают по моделям ценообразования на основе использования, которые могут стать дорогими в масштабе. Каждый обработанный документ влечет затраты, и операции с большими объемами могут быстро накапливать значительные расходы. Кроме того, эти сервисы требуют отправки конфиденциальных документов на внешние серверы, что вызывает опасения по поводу конфиденциальности данных и потенциальные проблемы соответствия для организаций, работающих с конфиденциальной информацией.
Docling устраняет эти проблемы, позволяя осуществлять полную локальную обработку без внешних зависимостей. Ваши данные никогда не покидают вашу инфраструктуру, обеспечивая максимальную безопасность и соответствие нормам защиты данных. Модель открытого исходного кода также предоставляет неограниченные возможности настройки – вы можете изменять логику парсинга, добавлять поддержку специализированных типов документов или интегрировать пользовательские AI-модели, адаптированные к вашим конкретным требованиям. Этот уровень гибкости обычно недоступен в коммерческих PDF редакторах и решениях для парсинга, которые предлагают ограниченные варианты конфигурации.
Основные техники: Извлечение, Парсинг, Чанкинг, Встраивание и Извлечение
Построение эффективного конвейера извлечения знаний включает несколько взаимосвязанных этапов, которые преобразуют сырые документы в поисковую, контекстную информацию. Каждый этап играет критическую роль в обеспечении того, чтобы ваши AI-агенты могли эффективно получать доступ и использовать содержимое документов.
Перед началом реализации убедитесь, что у вас установлены необходимые предварительные условия. Начните с установки требуемых пакетов с помощью pip install -r requirements.txt, что должно включать Docling и любые дополнительные зависимости. Создайте файл .env для хранения переменных окружения, включая ваш API-ключ OpenAI для генерации встраиваний, если используются внешние модели.
Построение конвейера следует этим ключевым этапам:
- Извлечение: Начните с извлечения содержимого из исходных документов с помощью конвертера документов Docling. После установки через pip install docling вы можете обрабатывать PDF, URL-адреса и различные форматы файлов в читаемое структурированное содержимое. Этот начальный этап обрабатывает обнаружение формата и извлечение содержимого, сохраняя структуру документа.
- Парсинг: Фаза парсинга идентифицирует и категоризирует элементы документа, включая текстовые абзацы, списки, таблицы и структурные компоненты. Docling преобразует содержимое в формат Markdown, сохраняя семантические отношения между элементами, что делает содержимое более легким для манипуляции и обработки на последующих этапах.
- Чанкинг: Чанкинг документа логически сегментирует содержимое для оптимальной обработки. Гибридный чанкер Docling автоматически регулирует размеры чанков на основе структуры содержимого, предотвращая слишком мелкие фрагменты и разделяя большие разделы в соответствии с параметрами подгонки текста. Это обеспечивает сохранение контекста при поддержании управляемых единиц обработки.
- Встраивание: Этап встраивания преобразует обработанные текстовые чанки в числовые векторы с использованием моделей встраивания. Вы можете использовать различные модели, включая встраивания OpenAI или альтернативы с открытым исходным кодом, создавая векторные представления, которые захватывают семантическое значение для эффективных операций поиска сходства.
- Извлечение: Заключительный этап включает хранение встраиваний в векторной базе данных, такой как LanceDB, обеспечивая эффективный поиск сходства и извлечение контекста. Это позволяет AI-агентам и ассистентам быстро находить соответствующие разделы документов при ответах на вопросы или предоставлении информации.
Запуск примера с Docling
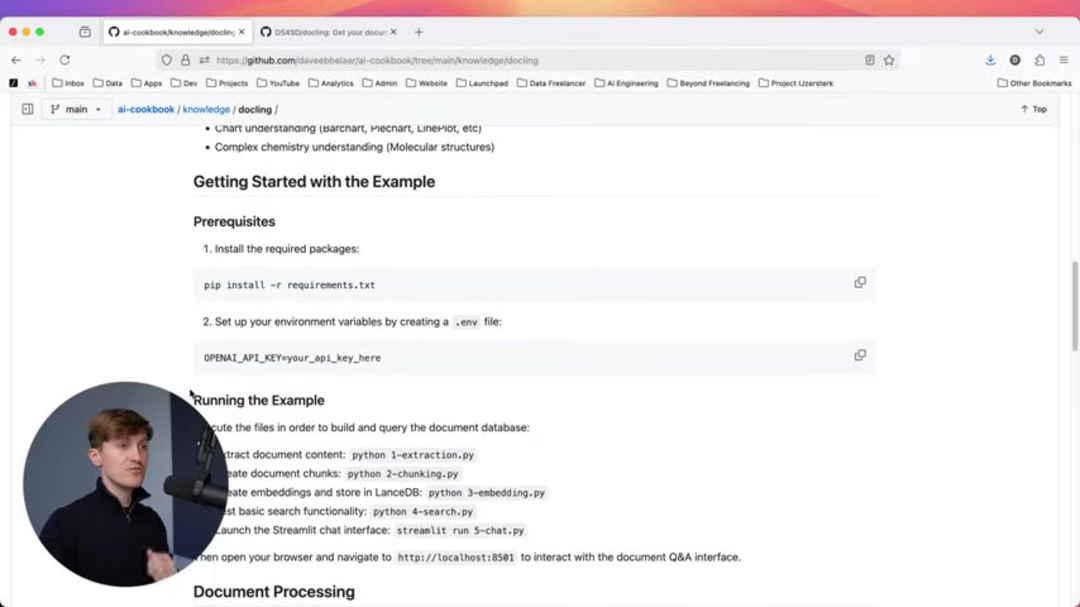
Чтобы продемонстрировать практическую реализацию, следуйте этим последовательным шагам для построения и тестирования полного конвейера обработки документов. Убедитесь, что каждый шаг завершается успешно, прежде чем переходить к следующему, и поддерживайте надлежащую безопасность для ваших файлов конфигурации окружения.
- Выполните python 1-extraction.py для извлечения содержимого документа из ваших исходных файлов или URL-адресов, генерируя структурированный вывод, готовый для дальнейшей обработки.
- Запустите python 2-chunking.py для создания оптимально размеренных чанков документа с использованием интеллектуальных алгоритмов сегментации Docling, подготавливая содержимое для генерации встраиваний.
- Обработайте python 3-embedding.py для генерации встраиваний и хранения их в векторной базе данных LanceDB, создавая индекс поиска для вашего содержимого документа.
- Протестируйте базовую функциональность поиска с помощью python 4-search.py, чтобы убедиться, что ваш конвейер работает корректно и возвращает релевантные результаты для примерных запросов.
- Запустите интерактивный интерфейс чата Streamlit с помощью streamlit run 5-chat.py, предоставляя удобный способ запроса вашей базы знаний документов.
После завершения этих шагов откройте ваш веб-браузер и перейдите по адресу localhost:8501 для доступа к интерфейсу вопросов и ответов по документам. Это предоставляет практическую демонстрацию того, как Docling обеспечивает интеллектуальное взаимодействие с документами через редактор документов и возможности поиска, интегрированные в разговорные интерфейсы.
Плюсы и минусы
Преимущества
- Полное решение с открытым исходным кодом с лицензией MIT
- Локальная обработка обеспечивает максимальную конфиденциальность данных
- Широкая поддержка форматов, включая PDF и DOCX
- Продвинутый анализ макета и распознавание таблиц
- Гибкие форматы вывода для интеграции
- Настраиваемый конвейер парсинга для уникальных потребностей
- Активная поддержка сообщества и документация
Недостатки
- Требует технических знаний для реализации
- Ограниченная интеграция визуальных языковых моделей
- Сложное понимание химических документов
- Ограничения локального оборудования для больших объемов
Заключение
Docling представляет собой значительный прогресс в обработке документов с открытым исходным кодом, предоставляя организациям мощную альтернативу коммерческим сервисам парсинга. Его комплексная поддержка форматов, продвинутые возможности AI и гибкая архитектура делают его идеальным для построения sophisticated систем извлечения знаний. Обеспечивая локальную обработку и полную настройку, Docling решает критические проблемы, связанные с конфиденциальностью данных, контролем затрат и гибкостью интеграции. Независимо от того, разрабатываете ли вы AI-агентов, строите RAG-конвейеры или создаете корпоративные решения поиска, Docling предлагает инструменты и возможности, необходимые для преобразования содержимого документов в действенный интеллект, сохраняя полный контроль над вашими данными и рабочими процессами обработки.
Часто задаваемые вопросы
Какие форматы файлов поддерживает Docling?
Docling поддерживает широкий спектр форматов документов, включая PDF, DOCX, XLSX, PPTX, Markdown, HTML и различные форматы изображений, что делает его универсальным для разнообразных потребностей обработки документов.
Является ли Docling действительно открытым исходным кодом?
Да, Docling использует лицензию MIT, предоставляя полный доступ к открытому исходному коду без ограничений или лицензионных сборов для коммерческого или личного использования.
Как Docling улучшает конвейеры RAG?
Docling оптимизирует конвейеры RAG с помощью расширенного разбиения на фрагменты, анализа макета и распознавания таблиц, предоставляя приложениям GenAI структурированные, контекстные знания из документов.
Может ли Docling обрабатывать документы локально?
Да, Docling работает полностью локально на стандартном оборудовании, обеспечивая конфиденциальность данных и устраняя зависимость от внешних API или облачных сервисов.
Какое оборудование рекомендуется для Docling?
Docling работает на стандартном оборудовании, но для больших объемов рекомендуется многоядерные процессоры и достаточный объем оперативной памяти; GPU может ускорить некоторые модели, если интегрирован.
Релевантные статьи об ИИ и технологических трендах
Будьте в курсе последних инсайтов, инструментов и инноваций, формирующих будущее ИИ и технологий.
Grok AI: Бесплатное неограниченное создание видео из текста и изображений | Руководство 2024
Grok AI предлагает бесплатное неограниченное создание видео из текста и изображений, делая профессиональное создание видео доступным для всех без навыков редактирования.
Топ-3 бесплатных расширений для ИИ-программирования в VS Code 2025 - Повышение производительности
Откройте для себя лучшие бесплатные расширения для ИИ-программирования в Visual Studio Code в 2025 году, включая Gemini Code Assist, Tabnine и Cline, чтобы улучшить вашу
Настройка Grok 4 Fast в Janitor AI: Полное руководство по ролевой игре без фильтров
Пошаговое руководство по настройке Grok 4 Fast в Janitor AI для неограниченной ролевой игры, включая настройку API, параметры конфиденциальности и советы по оптимизации