Annotation
- Введение
- Основы обучения с нулевым выстрелом
- Скрытые эмбеддинги: Техническая основа
- Модели TARS: Продвинутая классификация с нулевым выстрелом
- Инженерия промптов для оптимальной производительности
- Открытые решения и реализация
- Практические бизнес-приложения
- Плюсы и минусы
- Заключение
- Часто задаваемые вопросы
Обучение с нулевым выстрелом: Классификация текста без размеченных обучающих данных
Обучение с нулевым выстрелом позволяет ИИ классифицировать текст в непредвиденные категории без размеченных данных, используя семантические вложения и передачу знаний для

Введение
В быстро развивающейся области обработки естественного языка, обучение с нулевым выстрелом представляет собой революционный сдвиг в том, как машины понимают и категоризируют текст. Этот инновационный подход позволяет моделям искусственного интеллекта классифицировать документы, настроения и темы без необходимости в обширных размеченных обучающих наборах данных – ограничение, которое традиционно сдерживало приложения машинного обучения. Используя семантическое понимание и передачу знаний, обучение с нулевым выстрелом открывает новые возможности для организаций, работающих с динамическим контентом и развивающимися потребностями в классификации в различных ИИ чат-ботах и платформах автоматизации.
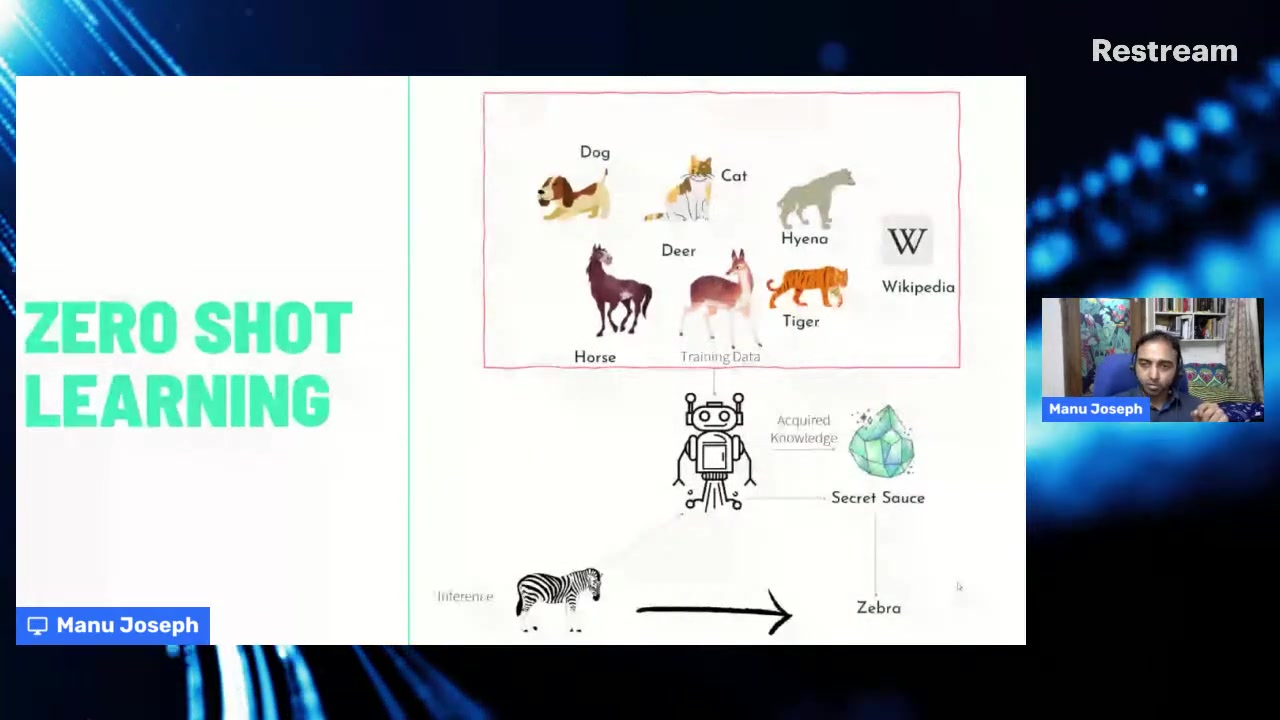
Основы обучения с нулевым выстрелом
Обучение с нулевым выстрелом представляет собой смену парадигмы по сравнению с традиционными методами обучения с учителем. В то время как классические подходы требуют значительного количества размеченных примеров для каждой категории классификации, обучение с нулевым выстрелом позволяет моделям категоризировать текст в классы, с которыми они никогда не сталкивались во время обучения. Эта способность проистекает из умения модели понимать семантические отношения и передавать знания из смежных областей.
Основной механизм включает проекцию как текстовых входов, так и меток категорий в общее семантическое пространство, где их отношения могут быть измерены с помощью метрик сходства. Этот подход имитирует человеческое рассуждение – мы часто можем категоризировать новые концепции на основе нашего понимания связанных идей без необходимости в явных примерах.
Скрытые эмбеддинги: Техническая основа
Скрытые эмбеддинги формируют техническую основу эффективных систем классификации с нулевым выстрелом. Эти эмбеддинги создают многомерное пространство, где как текстовое содержание, так и метки категорий могут быть представлены численно, позволяя проводить точные расчеты сходства. Продвинутые модели, такие как Sentence-BERT (S-BERT), преуспевают в генерации этих эмбеддингов, захватывая тонкие семантические значения за пределами простого сопоставления ключевых слов.
Процесс эмбеддинга обычно следует этим шагам:
- Кодирование текста: Входной текст обрабатывается через кодировщик на основе трансформеров для создания плотного векторного представления.
- Представление меток: Метки категорий аналогично кодируются с использованием той же архитектуры модели.
- Оценка сходства: Косинусное сходство или другие метрики вычисляют соответствие между текстом и метками.
- Решение классификации: Система присваивает текст категории с наивысшим баллом сходства.
Эта методология оказывается ценной для инструментов ИИ для письма, которые нуждаются в категоризации разнообразных типов контента без постоянного переобучения.
Модели TARS: Продвинутая классификация с нулевым выстрелом
Модели Text-Aware Representation of Sentences (TARS) представляют значительное продвижение в возможностях обучения с нулевым выстрелом. Эти специализированные архитектуры строятся на основе базовых моделей, таких как BERT, но включают дополнительные механизмы для обработки задач классификации без обучения, специфичного для задачи. Модели TARS демонстрируют гибкость в адаптации к новым схемам категоризации, сохраняя при этом надежную производительность.
Сила TARS заключается в его способности понимать контекстуальные отношения между текстом и потенциальными метками. Этот тонкий подход позволяет более точную категоризацию, особенно для сложных задач. Реализация включает предварительно обученные модели, применяемые к новым областям с минимальной настройкой, что идеально для быстрого развертывания. Это хорошо согласуется с современными инструментами разговорного ИИ, которые требуют динамического понимания контента.
Инженерия промптов для оптимальной производительности
Эффективная инженерия промптов играет ключевую роль в максимизации производительности обучения с нулевым выстрелом. Поскольку модели полагаются на представления меток, то, как сформулированы метки, влияет на точность. Хорошо продуманные промпты предоставляют контекст для понимания границ категорий.
Лучшие практики включают использование описательных, недвусмысленных названий меток. Для анализа настроений промпты вроде "текст, выражающий удовлетворение" и "текст, выражающий критику" дают лучшие результаты. Продвинутые техники используют множественные вариации промптов и ансамблевые методы для улучшения надежности, что ценно для API и SDK ИИ, где критически важна стабильная производительность.
Открытые решения и реализация
Экосистема обучения с нулевым выстрелом выигрывает от надежных реализаций с открытым исходным кодом. Библиотеки, такие как Hugging Face's Transformers, предоставляют предварительно обученные модели для задач с нулевым выстрелом, в то время как фреймворки, такие как SetFit, предлагают эффективные возможности с минимальными вычислительными потребностями.
Эти решения включают предварительно настроенные модели, стандартизированные API, документацию и обновления. Для разработчиков, работающих с платформами автоматизации ИИ, это снижает барьеры внедрения и предоставляет прочную основу для кастомизации.
Практические бизнес-приложения
Обучение с нулевым выстрелом приносит ценность в сценариях, где традиционная классификация непрактична. Служба поддержки клиентов категоризирует заявки в поддержку по новым проблемам без переобучения. Маркетинг анализирует отзывы о новых продуктах, а комплаенс отслеживает неизвестные риски.
Для агентов и ассистентов ИИ возможности с нулевым выстрелом позволяют адаптивные взаимодействия, понимая запросы пользователей вне обученных областей. Это также помогает в модерации контента, идентифицируя новый неподходящий контент на основе семантического сходства.
Плюсы и минусы
Преимущества
- Устраняет необходимость в обширных размеченных обучающих наборах данных
- Позволяет классифицировать совершенно новые, невиданные категории
- Облегчает быструю адаптацию к изменяющимся бизнес-требованиям
- Сокращает время подготовки данных и связанные затраты
- Поддерживает передачу знаний между смежными областями
Недостатки
- Может достигать более низкой точности, чем обучение с учителем при достаточных данных
- Производительность сильно зависит от качества эмбеддингов и дизайна промптов
- Может испытывать трудности с высокоспециализированными или техническими категориями доменов
Заключение
Обучение с нулевым выстрелом представляет собой значительный скачок в обеспечении доступности и эффективности классификации текста. Уменьшая зависимость от размеченных наборов данных, оно открывает машинное обучение для организаций с динамическими потребностями. Хотя оно не заменяет полностью обучение с учителем, оно предлагает мощную альтернативу для гибкости и быстрой адаптации, особенно в приложениях, связанных с текстовыми редакторами и системами управления контентом.
Часто задаваемые вопросы
Что такое обучение с нулевым выстрелом простыми словами?
Обучение с нулевым выстрелом позволяет моделям ИИ классифицировать текст в классы, которые они никогда не видели во время обучения, понимая семантические отношения, а не полагаясь на размеченные примеры для каждой конкретной категории.
Чем обучение с нулевым выстрелом отличается от традиционной классификации?
Традиционная классификация требует обширных размеченных данных для каждой категории, в то время как обучение с нулевым выстрелом использует семантическое понимание для классификации непредвиденных категорий без конкретных обучающих примеров.
Каковы основные бизнес-преимущества обучения с нулевым выстрелом?
Ключевые преимущества включают снижение затрат на разметку данных, более быструю адаптацию к новым категориям, обработку динамических потребностей классификации и возможность классификации при нехватке размеченных данных.
Какие отрасли больше всего выигрывают от классификации текста с нулевым выстрелом?
Обслуживание клиентов, модерация контента, исследование рынка, мониторинг соответствия и любые области с развивающимися категориями или возникающими темами, где разметка данных является сложной задачей.
Каковы ограничения обучения с нулевым выстрелом?
Ограничения включают потенциально более низкую точность по сравнению с обучением с учителем, зависимость от качества вложений и дизайна промптов, а также трудности с неоднозначным или высокотехническим контентом.
Релевантные статьи об ИИ и технологических трендах
Будьте в курсе последних инсайтов, инструментов и инноваций, формирующих будущее ИИ и технологий.
Grok AI: Бесплатное неограниченное создание видео из текста и изображений | Руководство 2024
Grok AI предлагает бесплатное неограниченное создание видео из текста и изображений, делая профессиональное создание видео доступным для всех без навыков редактирования.
Настройка Grok 4 Fast в Janitor AI: Полное руководство по ролевой игре без фильтров
Пошаговое руководство по настройке Grok 4 Fast в Janitor AI для неограниченной ролевой игры, включая настройку API, параметры конфиденциальности и советы по оптимизации
Топ-3 бесплатных расширений для ИИ-программирования в VS Code 2025 - Повышение производительности
Откройте для себя лучшие бесплатные расширения для ИИ-программирования в Visual Studio Code в 2025 году, включая Gemini Code Assist, Tabnine и Cline, чтобы улучшить вашу