Annotation
- Introduction
- Understanding Convolutional Neural Networks for Image Recognition
- Environment Setup and Required Tools
- Essential Python Libraries for CNN Development
- Working with the CIFAR-10 Dataset
- Building CNN Architecture with Keras
- Model Compilation and Training Configuration
- Practical Implementation Steps
- Pros and Cons
- Conclusion
- Frequently Asked Questions
CNN Image Recognition Tutorial: Python, Keras & TensorFlow Guide
Learn how to build a Convolutional Neural Network for image recognition using Python and Keras. This tutorial covers CNN architecture, dataset
Introduction
Convolutional Neural Networks have transformed computer vision, enabling machines to interpret visual data with unprecedented accuracy. This comprehensive tutorial guides you through building a practical CNN for image recognition using Python, Keras, and TensorFlow. We'll cover everything from environment setup to model evaluation, providing hands-on experience with real-world implementation. Whether you're exploring AI tutorials or building production systems, this guide delivers actionable knowledge for effective image recognition solutions.
Understanding Convolutional Neural Networks for Image Recognition
Convolutional Neural Networks represent a specialized architecture designed specifically for processing visual data. Unlike traditional neural networks that treat input data as flat vectors, CNNs preserve spatial relationships through their unique layer structure. This spatial awareness enables them to detect patterns, edges, and textures in ways that mimic human visual processing. The hierarchical feature extraction capability makes CNNs particularly effective for complex visual tasks where context and spatial relationships matter.
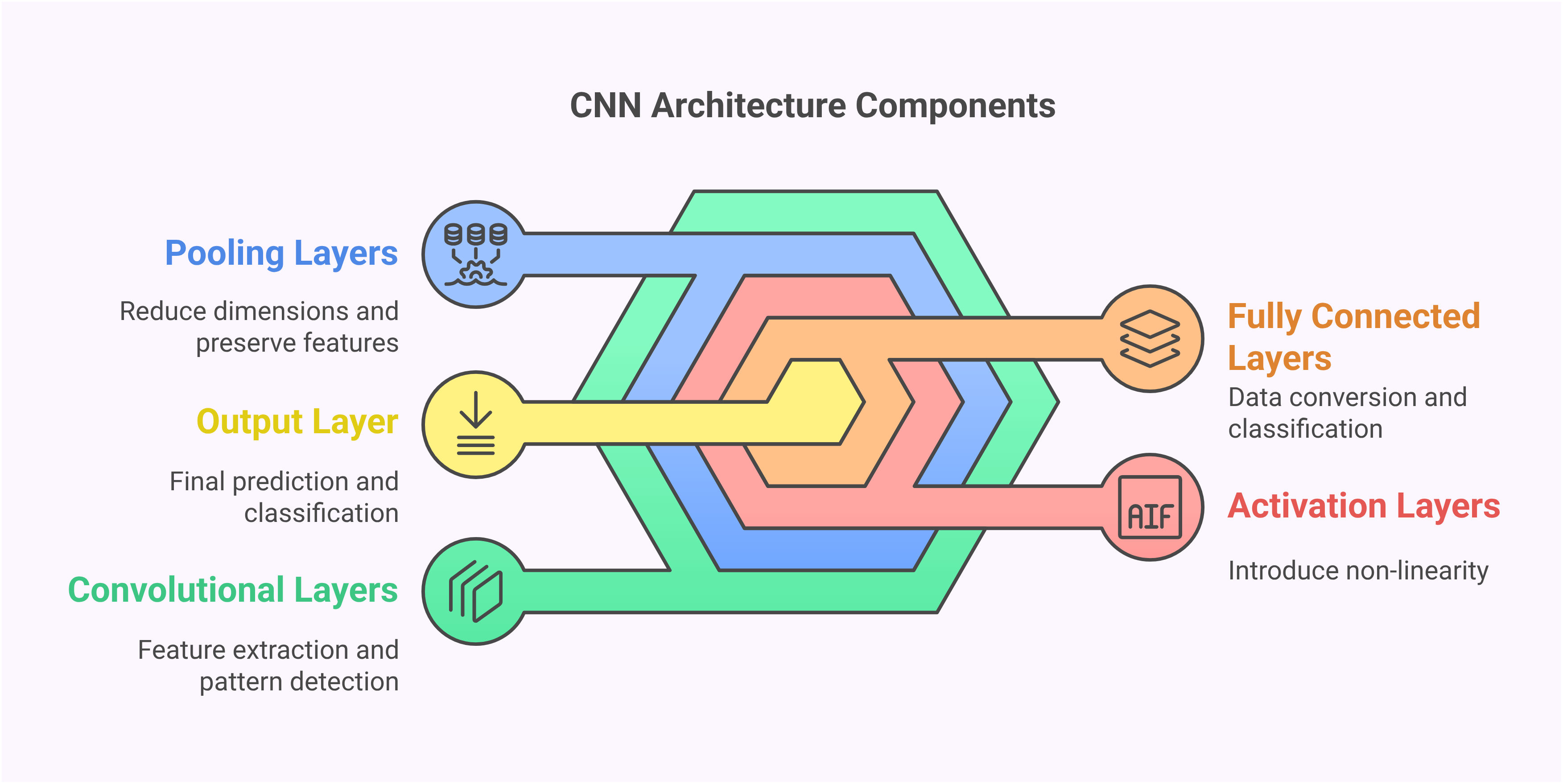
The fundamental building blocks of CNNs include convolutional layers that scan images with filters to detect features, pooling layers that reduce dimensionality while preserving important information, and fully connected layers that perform final classification. This structured approach allows CNNs to automatically learn relevant features without manual engineering, making them ideal for various image recognition applications from medical diagnostics to autonomous driving systems.
Environment Setup and Required Tools
Before implementing your CNN, proper environment configuration is essential. This tutorial uses Python 3.7+ with TensorFlow 2.x and Keras as the primary deep learning framework. The setup process involves installing several key packages that provide the computational backbone for neural network operations. Begin by creating a virtual environment to manage dependencies cleanly, then install the required packages using pip.
The core packages include TensorFlow for backend computations, Keras for high-level neural network APIs, NumPy for numerical operations, and Matplotlib for visualization. Additional useful libraries include OpenCV for advanced image processing and Scikit-learn for data preprocessing utilities. These tools collectively provide a robust foundation for building and experimenting with deep learning models across different hardware configurations.
Essential Python Libraries for CNN Development
Importing the correct libraries establishes the foundation for your image recognition system. The key imports include NumPy for array operations, Keras layers for network architecture, and dataset utilities for loading training data. Each library serves specific purposes in the CNN pipeline, from data manipulation to model definition and training.
The Sequential model from Keras provides a linear stack of layers, while Conv2D implements convolutional operations. Dropout layers prevent overfitting, BatchNormalization stabilizes training, and MaxPooling2D reduces spatial dimensions. Understanding each component's role helps in designing effective architectures and troubleshooting issues during development. These libraries form the core of modern deep learning frameworks used in production environments.
Working with the CIFAR-10 Dataset
The CIFAR-10 dataset serves as an excellent benchmark for image recognition tasks, containing 60,000 color images across 10 categories including airplanes, automobiles, birds, cats, deer, dogs, frogs, horses, ships, and trucks. Each 32x32 pixel image represents real-world objects with varying perspectives and lighting conditions, making it challenging enough to demonstrate CNN capabilities while remaining computationally manageable.
Data preprocessing involves normalizing pixel values to the 0-1 range by dividing by 255, which stabilizes training and improves convergence. One-hot encoding transforms categorical labels into binary vectors, enabling multi-class classification. Proper preprocessing ensures that the network receives standardized input, reducing training time and improving final accuracy. This dataset provides practical experience with real-world model validation techniques.
Building CNN Architecture with Keras
Designing the CNN architecture involves strategically stacking layers to extract increasingly complex features. The example architecture begins with convolutional layers using 3x3 filters and ReLU activation, followed by dropout and batch normalization for regularization. Max pooling layers reduce spatial dimensions while preserving important features, and the network culminates with dense layers for classification.
Key architectural decisions include filter sizes, pooling strategies, and layer depth. Smaller filters (3x3) capture fine details while larger filters recognize broader patterns. The number of filters increases in deeper layers to handle more complex feature combinations. This progressive complexity allows the network to learn hierarchical representations, from simple edges in early layers to complex object parts in deeper layers. Such architectures form the basis of modern computer vision systems.
Model Compilation and Training Configuration
Compiling the model involves specifying the loss function, optimizer, and evaluation metrics. For multi-class classification, categorical crossentropy measures prediction error, while the Adam optimizer adapts learning rates during training. Accuracy metrics track performance throughout the training process, providing immediate feedback on model improvement.
Training parameters like batch size and epochs significantly impact results. Smaller batches provide more frequent weight updates but require more computation, while larger batches offer stability but may converge slower. The validation split monitors generalization performance, helping detect overfitting early. These configurations balance training efficiency with model quality, essential for developing reliable AI applications.
Practical Implementation Steps
The implementation follows a structured workflow beginning with environment setup and data loading. After importing necessary libraries, load and preprocess the CIFAR-10 dataset, then define the CNN architecture using Keras Sequential API. Compile the model with appropriate loss functions and optimizers, then train using the prepared data with validation monitoring.
Evaluation involves testing the trained model on unseen data and analyzing performance metrics. The step-by-step approach ensures understanding of each component while building toward a complete working system. This methodology applies to various image recognition tasks beyond the tutorial scope, providing transferable skills for real-world projects.
Pros and Cons
Advantages
- Automatically learns relevant features without manual engineering
- Achieves high accuracy on complex image recognition tasks
- Robust to variations in scale, rotation, and lighting conditions
- Efficient processing through parameter sharing in convolutional layers
- Proven effectiveness across diverse computer vision applications
- Continuous improvement with larger datasets and better architectures
- Transfer learning capabilities for related visual tasks
Disadvantages
- Computationally intensive training requiring significant resources
- Large labeled datasets needed for optimal performance
- Susceptible to overfitting without proper regularization
- Complex hyperparameter tuning for optimal results
- Black box nature making interpretation challenging
Conclusion
This tutorial demonstrates the practical implementation of Convolutional Neural Networks for image recognition using Python and Keras. From environment setup through model evaluation, we've covered the essential steps for building effective computer vision systems. The CIFAR-10 dataset provides a realistic testing ground, while the CNN architecture showcases modern deep learning techniques. As you continue developing image recognition solutions, remember that successful implementations balance architectural complexity with computational efficiency, and always validate performance with rigorous testing. The skills gained here provide a solid foundation for tackling more advanced computer vision challenges in real-world applications.
Frequently Asked Questions
What is the ideal number of layers for a CNN?
There's no universal answer - start with 3-5 convolutional layers for basic tasks, increasing depth for complex recognition. Balance depth with computational constraints and overfitting risks through proper regularization techniques.
How can I improve my CNN model's accuracy?
Enhance accuracy through data augmentation, hyperparameter tuning, architectural optimization, regularization methods, and transfer learning. Experiment with different optimizers, learning rates, and layer configurations while monitoring validation performance.
Can this tutorial work with other datasets?
Yes, the methodology applies to various image datasets. Adjust input dimensions, normalization, and output layers to match your specific data characteristics while maintaining the core CNN architecture principles.
How does CNN handle image variations like rotation and scale?
CNNs use pooling layers and data augmentation to maintain invariance to small transformations, but may require specific techniques like spatial transformers for large variations in rotation and scale.
What are the key parameters to tune in a CNN model?
Important parameters include filter sizes, number of layers, learning rate, batch size, and regularization techniques like dropout to optimize performance and prevent overfitting in image recognition tasks.
Relevant AI & Tech Trends articles
Stay up-to-date with the latest insights, tools, and innovations shaping the future of AI and technology.
Grok AI: Free Unlimited Video Generation from Text & Images | 2024 Guide
Grok AI offers free unlimited video generation from text and images, making professional video creation accessible to everyone without editing skills.
Grok 4 Fast Janitor AI Setup: Complete Unfiltered Roleplay Guide
Step-by-step guide to configuring Grok 4 Fast on Janitor AI for unrestricted roleplay, including API setup, privacy settings, and optimization tips
Top 3 Free AI Coding Extensions for VS Code 2025 - Boost Productivity
Discover the best free AI coding agent extensions for Visual Studio Code in 2025, including Gemini Code Assist, Tabnine, and Cline, to enhance your