Annotation
- Introduction
- Why Choose Open Source for AI?
- Introducing Docling: An Open Source Hero
- Comparing Docling to Closed Source Alternatives
- Essential Techniques: Extraction, Parsing, Chunking, Embedding & Retrieval
- Running the Docling Example
- Pros and Cons
- Conclusion
- Frequently Asked Questions
Docling Open Source Document Parsing: Complete AI Implementation Guide
Docling open-source document parsing guide for AI: implement PDF processing, chunking, embedding, and RAG pipelines locally.

Introduction
In today's data-driven business environment, AI agents have become essential tools for customer support and data analysis. The foundation of effective AI systems lies in their ability to access and understand company-specific information, which often resides in documents, PDFs, and websites. While numerous commercial tools exist for document parsing, many come with API costs and closed-source limitations. Docling emerges as a powerful open-source alternative that provides complete control over your document processing pipeline while maintaining data privacy and customization flexibility.
Why Choose Open Source for AI?
When developing AI agents, access to proprietary data is crucial for achieving meaningful results. This data typically includes internal documents, PDF reports, and company websites that contain specific knowledge about your organization. Traditional parsing solutions often require sending sensitive data to third-party platforms, creating potential security vulnerabilities and ongoing licensing expenses. Open source alternatives like Docling eliminate these concerns by enabling local processing within your own infrastructure.
The advantages of open source document parsing extend beyond cost savings. You gain complete transparency into how your data is processed, the ability to customize parsing logic for unique document structures, and freedom from vendor lock-in. This approach aligns particularly well with enterprise requirements for data governance and compliance. For organizations exploring AI document extraction solutions, open source provides both technical and strategic benefits.

Open source tools deliver significant value through several key benefits: complete control over data processing pipelines, unlimited customization possibilities, transparent operations that enhance security, active community support, and substantial cost reductions compared to proprietary alternatives. These advantages make open source particularly attractive for organizations building comprehensive AI automation platforms that require reliable document processing capabilities.
Introducing Docling: An Open Source Hero
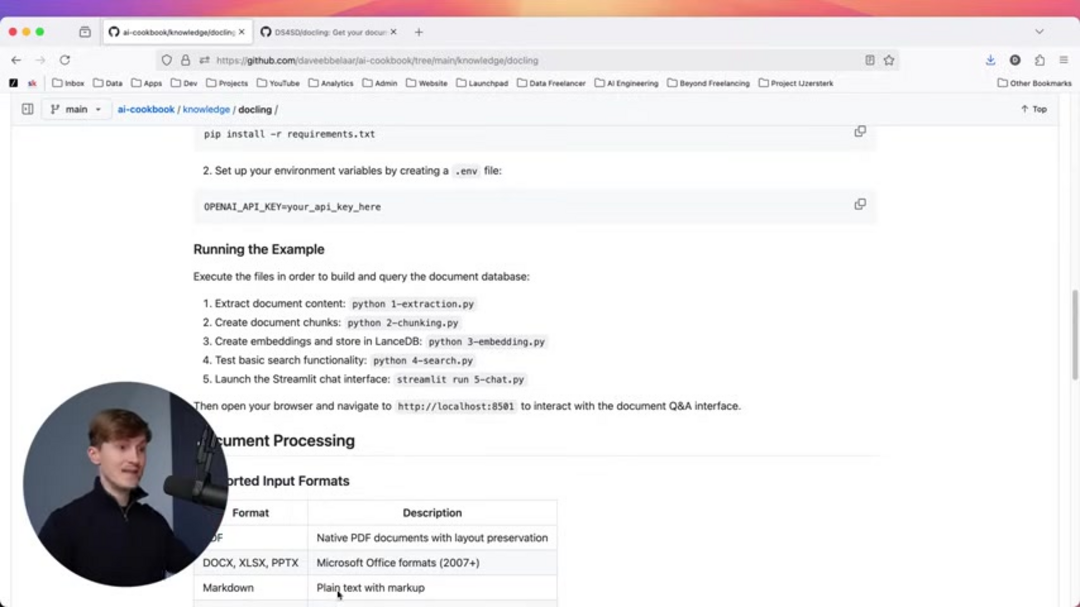
Docling represents a sophisticated open-source document processing library that transforms diverse document formats into unified, structured data. Built with advanced AI capabilities, it excels at layout analysis and table structure recognition while maintaining local processing efficiency. The library supports an extensive range of formats including PDFs, DOCX files, XLSX spreadsheets, PPTX presentations, Markdown documents, HTML pages, and various image formats.

What sets Docling apart is its flexible output options, allowing developers to export processed content to HTML, Markdown, JSON, or plain text formats. This versatility makes it ideal for integration into existing workflows and applications. The system operates efficiently on standard hardware and features extensible architecture that enables developers to incorporate custom models or modify processing pipelines for specific requirements. This makes Docling particularly valuable for enterprise document search systems, passage retrieval implementations, and knowledge extraction projects.
For developers working with AI APIs and SDKs, Docling provides a robust foundation for building Retrieval Augmented Generation (RAG) pipelines. Its advanced chunking capabilities and processing optimizations ensure that GenAI applications receive well-structured knowledge inputs, significantly improving response quality and accuracy in document-based question answering systems.
Comparing Docling to Closed Source Alternatives
When evaluating document parsing solutions, it's essential to understand how Docling compares to commercial alternatives like Microsoft Azure AI Document Intelligence, Amazon Textract, and various proprietary services. The fundamental distinction lies in Docling's open-source nature versus the closed-source, API-dependent approach of commercial offerings.
Commercial document parsing services typically operate on usage-based pricing models that can become expensive at scale. Each document processed incurs costs, and high-volume operations can quickly accumulate significant expenses. Additionally, these services require sending sensitive documents to external servers, raising data privacy concerns and potential compliance issues for organizations handling confidential information.
Docling eliminates these concerns by enabling complete local processing without external dependencies. Your data never leaves your infrastructure, ensuring maximum security and compliance with data protection regulations. The open-source model also provides unlimited customization opportunities – you can modify parsing logic, add support for specialized document types, or integrate custom AI models tailored to your specific requirements. This level of flexibility is typically unavailable in commercial PDF editor and parsing solutions that offer limited configuration options.
Essential Techniques: Extraction, Parsing, Chunking, Embedding & Retrieval
Constructing an effective knowledge extraction pipeline involves several interconnected stages that transform raw documents into searchable, contextual information. Each stage plays a critical role in ensuring your AI agents can effectively access and utilize document content.
Before beginning implementation, ensure you have the necessary prerequisites installed. Start by installing required packages using pip install -r requirements.txt, which should include Docling and any additional dependencies. Create a .env file to store environment variables, including your OpenAI API key for embedding generation if using external models.
The pipeline construction follows these key stages:
- Extraction: Begin by extracting content from source documents using Docling's document converter. After installing via pip install docling, you can process PDFs, URLs, and various file formats into readable structured content. This initial stage handles format detection and content extraction while preserving document structure.
- Parsing: The parsing phase identifies and categorizes document elements including text paragraphs, lists, tables, and structural components. Docling converts content to Markdown format while maintaining semantic relationships between elements, making the content easier to manipulate and process in subsequent stages.
- Chunking: Document chunking logically segments content for optimal processing. Docling's Hybrid chunker automatically adjusts chunk sizes based on content structure, preventing overly small fragments while splitting large sections according to text fitting parameters. This ensures context preservation while maintaining manageable processing units.
- Embedding: The embedding stage converts processed text chunks into numerical vectors using embedding models. You can utilize various models including OpenAI's embeddings or open-source alternatives, creating vector representations that capture semantic meaning for efficient similarity search operations.
- Retrieval: The final stage involves storing embeddings in a vector database like LanceDB, enabling efficient similarity search and context retrieval. This allows AI agents and assistants to quickly locate relevant document sections when answering questions or providing information.
Running the Docling Example
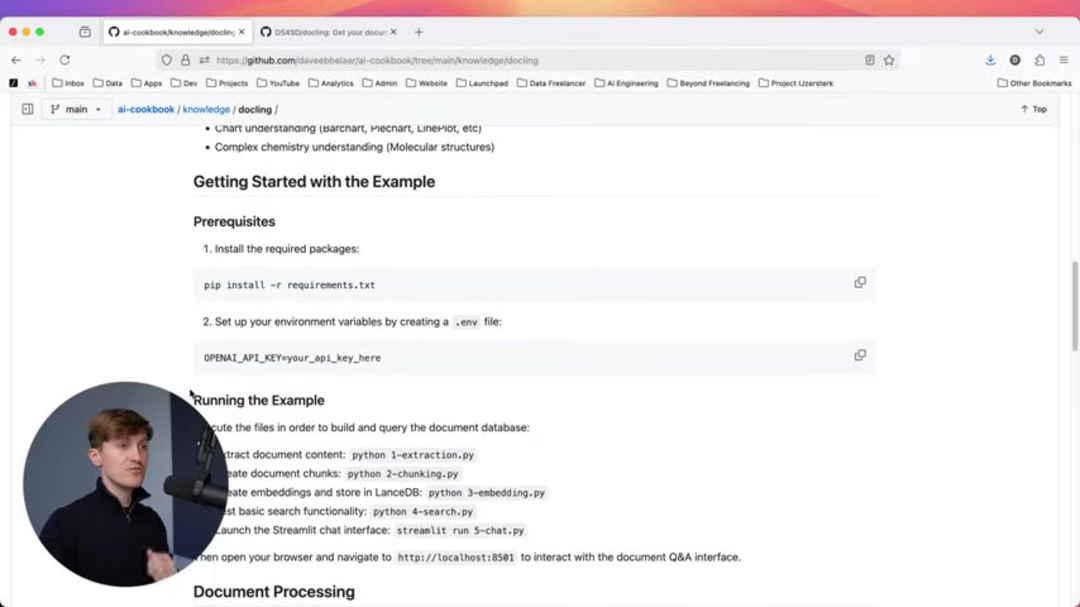
To demonstrate a practical implementation, follow these sequential steps to build and test a complete document processing pipeline. Ensure each step completes successfully before proceeding to the next, and maintain proper security for your environment configuration files.
- Execute python 1-extraction.py to extract document content from your source files or URLs, generating structured output ready for further processing.
- Run python 2-chunking.py to create optimally sized document chunks using Docling's intelligent segmentation algorithms, preparing content for embedding generation.
- Process python 3-embedding.py to generate embeddings and store them in LanceDB vector database, creating the search index for your document content.
- Test basic search functionality with python 4-search.py to verify your pipeline is working correctly and returning relevant results for sample queries.
- Launch the interactive Streamlit chat interface using streamlit run 5-chat.py, providing a user-friendly way to query your document knowledge base.
After completing these steps, open your web browser and navigate to localhost:8501 to access the document Q&A interface. This provides a practical demonstration of how Docling enables intelligent document interaction through document editor and search capabilities integrated into conversational interfaces.
Pros and Cons
Advantages
- Complete open-source solution with MIT licensing
- Local processing ensures maximum data privacy
- Extensive format support including PDF and DOCX
- Advanced layout analysis and table recognition
- Flexible output formats for integration
- Customizable parsing pipeline for unique needs
- Active community support and documentation
Disadvantages
- Requires technical expertise for implementation
- Limited visual language model integration
- Complex chemistry document understanding
- Local hardware limitations for large volumes
Conclusion
Docling represents a significant advancement in open-source document processing, providing organizations with a powerful alternative to commercial parsing services. Its comprehensive format support, advanced AI capabilities, and flexible architecture make it ideal for building sophisticated knowledge extraction systems. By enabling local processing and complete customization, Docling addresses critical concerns around data privacy, cost control, and integration flexibility. Whether you're developing AI agents, building RAG pipelines, or creating enterprise search solutions, Docling offers the tools and capabilities needed to transform document content into actionable intelligence while maintaining full control over your data and processing workflows.
Frequently Asked Questions
What file formats does Docling support?
Docling supports extensive document formats including PDF, DOCX, XLSX, PPTX, Markdown, HTML, and various image formats, making it versatile for diverse document processing needs.
Is Docling truly open source?
Yes, Docling uses MIT licensing, providing complete open-source access without restrictions or licensing fees for commercial or personal use.
How does Docling enhance RAG pipelines?
Docling optimizes RAG pipelines through advanced chunking, layout analysis, and table recognition, providing GenAI applications with structured, contextual knowledge from documents.
Can Docling process documents locally?
Yes, Docling operates entirely locally on standard hardware, ensuring data privacy and eliminating dependency on external APIs or cloud services.
What hardware is recommended for Docling?
Docling runs on standard hardware, but for large volumes, recommend multi-core CPUs and sufficient RAM; GPU can accelerate some models if integrated.
Relevant AI & Tech Trends articles
Stay up-to-date with the latest insights, tools, and innovations shaping the future of AI and technology.
Grok AI: Free Unlimited Video Generation from Text & Images | 2024 Guide
Grok AI offers free unlimited video generation from text and images, making professional video creation accessible to everyone without editing skills.
Top 3 Free AI Coding Extensions for VS Code 2025 - Boost Productivity
Discover the best free AI coding agent extensions for Visual Studio Code in 2025, including Gemini Code Assist, Tabnine, and Cline, to enhance your
Grok 4 Fast Janitor AI Setup: Complete Unfiltered Roleplay Guide
Step-by-step guide to configuring Grok 4 Fast on Janitor AI for unrestricted roleplay, including API setup, privacy settings, and optimization tips