Annotation
- Introduction
- Understanding Audio Transcription Services
- Core Infrastructure Components
- Website Interface and User Experience
- Production Architecture and Workflow
- Codebase Structure and GitHub Repository
- Real-World Development Challenges
- Containerization and Future Improvements
- Database Design and Job Tracking
- Pros and Cons
- Conclusion
- Frequently Asked Questions
Build Audio Transcription Service: Kubernetes, RabbitMQ Guide
Learn how to build a scalable audio transcription service with Kubernetes and RabbitMQ. This guide covers architecture, workflow, and implementation

Introduction
Building an audio transcription service requires careful planning across infrastructure, processing workflows, and user experience. This comprehensive guide walks through creating Phonic Tonic – a functional prototype demonstrating how to convert speech to text at scale. We'll explore the complete technical stack from container orchestration to message queuing, providing practical insights for developers building similar services.
Understanding Audio Transcription Services
Audio-to-text conversion has become essential across multiple industries including media production, academic research, legal documentation, and business communications. Modern transcription services leverage advanced speech recognition algorithms to deliver accurate text outputs from various audio formats. The growing demand stems from improved accessibility requirements, enhanced content searchability, and efficient data analysis capabilities. For developers, building such services presents unique challenges around scalability, accuracy, and cost optimization.
Phonic Tonic serves as an educational prototype that demonstrates real-world implementation challenges rather than presenting polished enterprise code. This approach provides valuable insights into the practical aspects of development, including infrastructure decisions, workflow design, and operational considerations that many tutorials overlook.
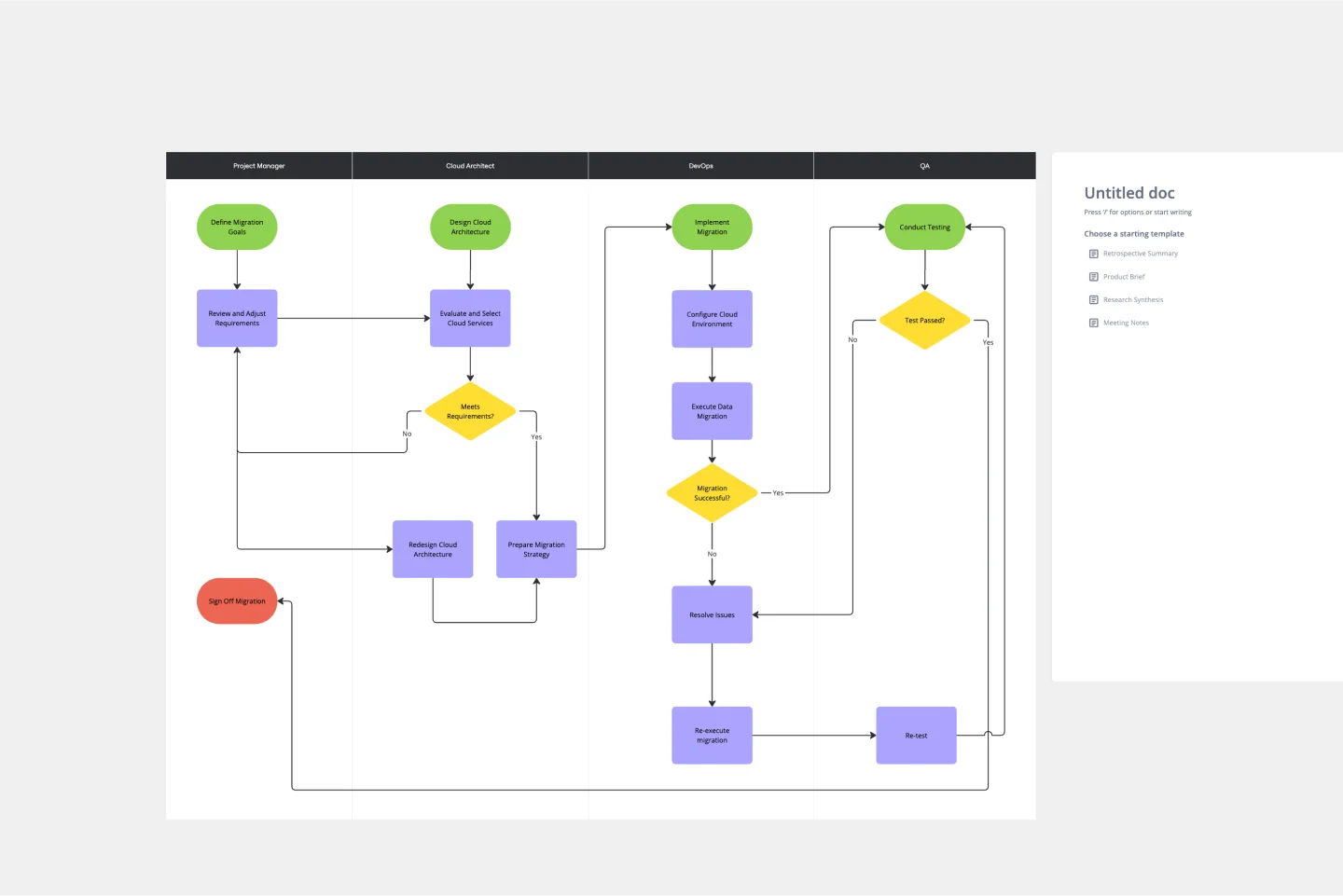
Core Infrastructure Components
The foundation of any reliable transcription service lies in its infrastructure architecture. Phonic Tonic employs a microservices approach using several key technologies that work together seamlessly. Kubernetes handles container orchestration, ensuring that different components can scale independently based on workload demands. This is particularly important for handling variable transcription request volumes throughout the day.
Message queuing with RabbitMQ enables asynchronous processing, preventing system overload during peak usage periods. When users upload multiple large audio files simultaneously, the queue manages the workload distribution across available workers. Cloud storage solutions like Google Cloud Storage provide durable, scalable file storage for both original audio files and generated transcripts, while MySQL databases track job status and user information throughout the processing pipeline.
Website Interface and User Experience
The user-facing component of Phonic Tonic focuses on simplicity and functionality. Users interact with a clean web interface where they can upload audio files in common formats like MP3, WAV, and M4A. The system includes comprehensive file validation to ensure uploaded content meets processing requirements before entering the transcription queue. Email collection enables notification delivery once transcription completes, creating a seamless user experience without requiring account creation.
Behind the scenes, the website handles initial file processing and coordinates with backend services through well-defined APIs. This separation of concerns allows frontend and backend development to proceed independently while maintaining system reliability. The interface design prioritizes clarity and ease of use, recognizing that many users may not have technical backgrounds but still require accurate transcription services.
Production Architecture and Workflow
The transcription workflow follows a carefully orchestrated sequence from file upload to text delivery. When a user submits an audio file, the system first validates the format and stores it in cloud storage. A database record creates a job entry with unique identifier and user contact information. The system then places a transcription request into the message queue, where available workers can claim tasks based on current capacity.
This distributed approach prevents single points of failure and enables horizontal scaling during high-demand periods. The architecture separates transcoding (format conversion) from actual speech recognition, allowing specialized optimization for each task. Completed transcriptions trigger email notifications to users with download links, while the system maintains audit trails for troubleshooting and analytics purposes.
Codebase Structure and GitHub Repository
The Phonic Tonic codebase, available publicly on GitHub, demonstrates practical implementation patterns for similar projects. The repository contains Docker configurations for containerized deployment, Kubernetes YAML files for orchestration, and source code for all major components. The web service handles user interactions and initial processing, while specialized workers manage specific tasks like audio transcoding, speech recognition, and email notifications.
Each component follows modular design principles, making the system easier to maintain and extend. The transcription worker integrates with cloud speech APIs, handling authentication, request formatting, and response processing. The code includes comprehensive error handling for common scenarios like network timeouts, invalid audio formats, and API quota limitations – essential considerations for production readiness.
Real-World Development Challenges
Building production-ready transcription services involves addressing numerous practical challenges beyond basic functionality. Phonic Tonic intentionally showcases common startup compromises, including hardcoded credentials that should use environment variables or Kubernetes secrets in production environments. The prototype lacks comprehensive monitoring and alerting systems, which would be essential for identifying performance issues or service disruptions in live deployment.
Security considerations extend beyond credential management to include input validation, access controls, and data encryption. The educational nature of this project means these aspects are simplified, but production systems would require rigorous security reviews and compliance with data protection regulations. Performance optimization represents another area for enhancement, particularly around handling large audio files and minimizing transcription latency.
Containerization and Future Improvements
The containerization strategy enables consistent deployment across different environments while simplifying dependency management. Future enhancements would focus on operational excellence through comprehensive logging using ELK stack implementations and metric monitoring with Prometheus and Grafana. These tools provide visibility into system performance and help identify bottlenecks before they impact users.
Alerting mechanisms would notify administrators of critical issues like queue backlogs, worker failures, or storage capacity limits. Load testing would validate system behavior under expected peak loads, ensuring reliable performance during usage spikes. These improvements represent the evolution from functional prototype to production-ready service capable of handling real user traffic.
Database Design and Job Tracking
The database schema for Phonic Tonic emphasizes simplicity and effectiveness for job tracking. Two primary tables manage the core workflow: the Jobs table stores high-level information including user email addresses and unique identifiers, while the Tasks table tracks individual processing steps with status updates, file metadata, and final transcription results. This separation allows flexible handling of complex processing pipelines while maintaining data integrity.
The design supports audit trails and troubleshooting by preserving historical job information and processing timelines. Future enhancements could include additional tables for user management, billing information, and analytics data, but the current implementation focuses on the essential requirements for a minimum viable product.
Pros and Cons
Advantages
- Scalable architecture using Kubernetes container orchestration
- Asynchronous processing prevents system overload during peaks
- Modular design enables independent component development
- Cloud storage provides durable, cost-effective file management
- Open source codebase facilitates learning and customization
- Comprehensive error handling for common failure scenarios
- Simple user interface reduces barriers to adoption
Disadvantages
- Hardcoded credentials pose significant security risks
- Missing monitoring and alerting for production environments
- Limited load testing data for performance validation
- Insufficient logging for effective troubleshooting
- Basic authentication without multi-user support
Conclusion
Building an audio transcription service like Phonic Tonic demonstrates the intersection of modern development practices and practical business requirements. While the prototype showcases functional implementation, production deployment would require addressing security, monitoring, and scalability considerations. The modular architecture provides a solid foundation for extension, whether adding support for additional languages, implementing real-time transcription, or integrating with content management systems. For developers embarking on similar projects, this guide offers both technical patterns and valuable insights into the realities of bringing transcription services from concept to operational status.
Frequently Asked Questions
What technologies power Phonic Tonic transcription service?
Phonic Tonic uses Kubernetes for container orchestration, RabbitMQ for message queuing, Google Cloud Storage for file management, and MySQL for job tracking, creating a scalable microservices architecture.
Is the Phonic Tonic code production-ready?
No, it's an educational prototype requiring security improvements, monitoring systems, and load testing before production deployment, but provides excellent learning foundation.
How does message queuing improve transcription services?
RabbitMQ enables asynchronous processing, preventing system overload during peak usage by distributing workloads across available workers and ensuring job persistence until completion.
What are key security considerations for transcription services?
Essential security measures include using environment variables for credentials, implementing proper access controls, encrypting sensitive data, and conducting regular security audits.
What audio formats are supported by Phonic Tonic?
Phonic Tonic supports common audio formats including MP3, WAV, and M4A, with built-in validation to ensure file compatibility before processing.
Relevant AI & Tech Trends articles
Stay up-to-date with the latest insights, tools, and innovations shaping the future of AI and technology.
Grok AI: Free Unlimited Video Generation from Text & Images | 2024 Guide
Grok AI offers free unlimited video generation from text and images, making professional video creation accessible to everyone without editing skills.
Top 3 Free AI Coding Extensions for VS Code 2025 - Boost Productivity
Discover the best free AI coding agent extensions for Visual Studio Code in 2025, including Gemini Code Assist, Tabnine, and Cline, to enhance your
Grok 4 Fast Janitor AI Setup: Complete Unfiltered Roleplay Guide
Step-by-step guide to configuring Grok 4 Fast on Janitor AI for unrestricted roleplay, including API setup, privacy settings, and optimization tips